Attri-Net: A Globally and Locally Inherently Interpretable Model for Multi-Label Classification Using Class-Specific Counterfactuals

0

Sign in to get full access
Overview
- The paper proposes a new model called Attri-Net for multi-label classification tasks that is inherently globally and locally interpretable.
- Attri-Net uses class-specific counterfactuals to generate explanations for individual predictions as well as the overall model behavior.
- The model demonstrates strong performance on several benchmark datasets while providing detailed and human-understandable explanations.
Plain English Explanation
Attri-Net is a new machine learning model designed for multi-label classification problems, where an object or document can belong to multiple categories simultaneously. The key innovation of Attri-Net is that it is inherently interpretable, meaning it can explain its predictions in a way that humans can understand.
Typical black-box machine learning models like neural networks are powerful but act as "black boxes" - it's very difficult to understand how they arrive at their decisions. Attri-Net, on the other hand, uses a technique called "class-specific counterfactuals" to generate explanations. Essentially, it can point to specific features of the input data that were most influential in its classification decisions for each label.
For example, if Attri-Net is classifying a document as belonging to the "politics" and "economics" categories, it could explain that the mentions of certain political figures and economic terms were the key factors driving those predictions. This transparency allows users to trust the model's decisions and understand its reasoning.
In addition to explaining individual predictions, Attri-Net can also provide global insights into how the model works overall. By analyzing the class-specific counterfactuals across many samples, the model can reveal the most important factors it uses to make decisions, akin to a post on interpretable network visualizations in the human-in-the-loop approach.
The researchers demonstrate that Attri-Net performs competitively with state-of-the-art black-box models on standard multi-label benchmarks, while also providing these rich explanations. This represents an important advancement in the field of interpretable machine learning, allowing users to understand and trust the model's decisions.
Technical Explanation
Attri-Net is a novel neural network architecture for multi-label classification that is inherently interpretable at both the global and local levels. The key innovation is the use of class-specific counterfactuals to generate explanations for the model's predictions.
At the core of Attri-Net is a "factorization layer" that decomposes the input features into class-specific attributes. These attributes represent the important factors that the model uses to make predictions for each class. During training, the model learns to associate these attributes with the correct labels through a multi-task learning objective.
At inference time, Attri-Net can use the learned attribute-label associations to provide explanations for its predictions. For a given input, the model can highlight the most relevant attributes for each predicted label, essentially showing the user "why" it made that classification decision. This aligns with work on intrinsic user-centric interpretability through global explanations.
Additionally, by analyzing the attribute importance scores across many inputs, Attri-Net can uncover the global factors that most influence its overall behavior. This provides a high-level understanding of the model's decision-making process, similar to techniques for evaluating explainability attributes and prototypes in medical classification models.
The researchers evaluate Attri-Net on several standard multi-label benchmarks and show that it achieves performance competitive with state-of-the-art black-box models, while also providing detailed explanations for its predictions. This work represents an important step towards more explainable "black-box" models that can be trusted and understood by users.
Critical Analysis
The Attri-Net paper presents a thoughtful and well-designed approach to achieving inherent interpretability in a multi-label classification model. The use of class-specific counterfactuals is a clever way to generate explanations that are both local (for individual predictions) and global (for overall model behavior).
One potential limitation is the scalability of the approach, as the number of class-specific attributes may grow quickly as the number of labels increases. The researchers mention that they address this by using a sparse factorization layer, but it's an open question how well Attri-Net would perform on datasets with a very large number of labels.
Additionally, while the paper demonstrates strong performance on benchmark datasets, it would be valuable to see how the model behaves in real-world applications with more diverse and noisy data. The ability to provide faithful and meaningful explanations is crucial, and further validation in complex, deployment-ready scenarios would strengthen the case for Attri-Net.
Overall, this work represents an important contribution to the field of interpretable machine learning. By combining strong predictive performance with inherent interpretability, Attri-Net offers a compelling alternative to traditional black-box models, aligning with the growing emphasis on explainable AI systems. Continued research in this direction has the potential to make machine learning more transparent and trustworthy for a wide range of applications.
Conclusion
The Attri-Net model proposed in this paper addresses a key challenge in machine learning: providing inherently interpretable predictions for multi-label classification tasks. By leveraging class-specific counterfactuals, the model can offer detailed explanations for its decisions, both at the individual prediction level and across the entire model.
This work represents an important advancement in the field of interpretable machine learning, demonstrating that it's possible to achieve competitive predictive performance while also maintaining transparency and human-understandable reasoning. As AI systems become more prevalent in high-stakes domains, the ability to trust and understand model decisions will be critical. The Attri-Net approach offers a promising path forward in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Attri-Net: A Globally and Locally Inherently Interpretable Model for Multi-Label Classification Using Class-Specific Counterfactuals
Susu Sun, Stefano Woerner, Andreas Maier, Lisa M. Koch, Christian F. Baumgartner
Interpretability is crucial for machine learning algorithms in high-stakes medical applications. However, high-performing neural networks typically cannot explain their predictions. Post-hoc explanation methods provide a way to understand neural networks but have been shown to suffer from conceptual problems. Moreover, current research largely focuses on providing local explanations for individual samples rather than global explanations for the model itself. In this paper, we propose Attri-Net, an inherently interpretable model for multi-label classification that provides local and global explanations. Attri-Net first counterfactually generates class-specific attribution maps to highlight the disease evidence, then performs classification with logistic regression classifiers based solely on the attribution maps. Local explanations for each prediction can be obtained by interpreting the attribution maps weighted by the classifiers' weights. Global explanation of whole model can be obtained by jointly considering learned average representations of the attribution maps for each class (called the class centers) and the weights of the linear classifiers. To ensure the model is ``right for the right reason, we further introduce a mechanism to guide the model's explanations to align with human knowledge. Our comprehensive evaluations show that Attri-Net can generate high-quality explanations consistent with clinical knowledge while not sacrificing classification performance.
Read more6/11/2024

0
This actually looks like that: Proto-BagNets for local and global interpretability-by-design
Kerol Djoumessi, Bubacarr Bah, Laura Kuhlewein, Philipp Berens, Lisa Koch
Interpretability is a key requirement for the use of machine learning models in high-stakes applications, including medical diagnosis. Explaining black-box models mostly relies on post-hoc methods that do not faithfully reflect the model's behavior. As a remedy, prototype-based networks have been proposed, but their interpretability is limited as they have been shown to provide coarse, unreliable, and imprecise explanations. In this work, we introduce Proto-BagNets, an interpretable-by-design prototype-based model that combines the advantages of bag-of-local feature models and prototype learning to provide meaningful, coherent, and relevant prototypical parts needed for accurate and interpretable image classification tasks. We evaluated the Proto-BagNet for drusen detection on publicly available retinal OCT data. The Proto-BagNet performed comparably to the state-of-the-art interpretable and non-interpretable models while providing faithful, accurate, and clinically meaningful local and global explanations. The code is available at https://github.com/kdjoumessi/Proto-BagNets.
Read more6/26/2024

0
Interpretable Network Visualizations: A Human-in-the-Loop Approach for Post-hoc Explainability of CNN-based Image Classification
Matteo Bianchi, Antonio De Santis, Andrea Tocchetti, Marco Brambilla
Transparency and explainability in image classification are essential for establishing trust in machine learning models and detecting biases and errors. State-of-the-art explainability methods generate saliency maps to show where a specific class is identified, without providing a detailed explanation of the model's decision process. Striving to address such a need, we introduce a post-hoc method that explains the entire feature extraction process of a Convolutional Neural Network. These explanations include a layer-wise representation of the features the model extracts from the input. Such features are represented as saliency maps generated by clustering and merging similar feature maps, to which we associate a weight derived by generalizing Grad-CAM for the proposed methodology. To further enhance these explanations, we include a set of textual labels collected through a gamified crowdsourcing activity and processed using NLP techniques and Sentence-BERT. Finally, we show an approach to generate global explanations by aggregating labels across multiple images.
Read more5/7/2024
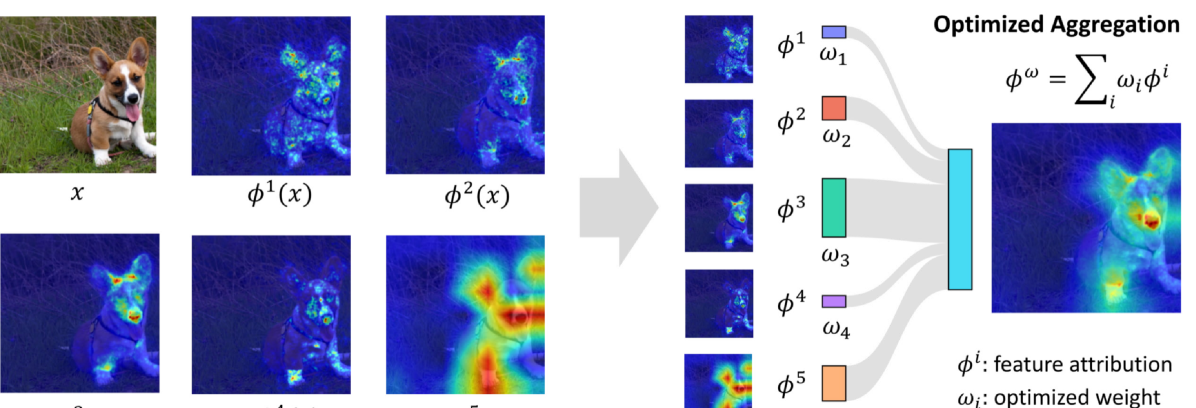
0
Provably Better Explanations with Optimized Aggregation of Feature Attributions
Thomas Decker, Ananta R. Bhattarai, Jindong Gu, Volker Tresp, Florian Buettner
Using feature attributions for post-hoc explanations is a common practice to understand and verify the predictions of opaque machine learning models. Despite the numerous techniques available, individual methods often produce inconsistent and unstable results, putting their overall reliability into question. In this work, we aim to systematically improve the quality of feature attributions by combining multiple explanations across distinct methods or their variations. For this purpose, we propose a novel approach to derive optimal convex combinations of feature attributions that yield provable improvements of desired quality criteria such as robustness or faithfulness to the model behavior. Through extensive experiments involving various model architectures and popular feature attribution techniques, we demonstrate that our combination strategy consistently outperforms individual methods and existing baselines.
Read more6/10/2024