Object-Attribute Binding in Text-to-Image Generation: Evaluation and Control
2404.13766
0
0

Abstract
Current diffusion models create photorealistic images given a text prompt as input but struggle to correctly bind attributes mentioned in the text to the right objects in the image. This is evidenced by our novel image-graph alignment model called EPViT (Edge Prediction Vision Transformer) for the evaluation of image-text alignment. To alleviate the above problem, we propose focused cross-attention (FCA) that controls the visual attention maps by syntactic constraints found in the input sentence. Additionally, the syntax structure of the prompt helps to disentangle the multimodal CLIP embeddings that are commonly used in T2I generation. The resulting DisCLIP embeddings and FCA are easily integrated in state-of-the-art diffusion models without additional training of these models. We show substantial improvements in T2I generation and especially its attribute-object binding on several datasets.footnote{Code and data will be made available upon acceptance.
Create account to get full access
Overview
- This paper investigates the problem of object-attribute binding in text-to-image (T2I) generation, which is the ability to accurately associate visual objects with their corresponding attributes described in the input text.
- The authors propose methods to evaluate and control object-attribute binding in T2I models, aiming to improve the alignment between generated images and the semantic information in the input text.
- Key contributions include a novel evaluation metric, techniques for improving binding, and analysis of the factors affecting binding performance.
Plain English Explanation
The paper looks at how well text-to-image generation models are able to correctly match the objects and their properties described in the input text with the visuals they produce. For example, if the text says "a red car," the generated image should show a red car, not a blue car.
The researchers develop new ways to measure how well the models are able to bind the objects and their attributes. They also explore techniques to improve this binding, so the generated images better match the semantic information in the text prompt.
The main goals are to create better evaluation methods and find ways to give text-to-image models more control over correctly associating the objects and their characteristics described in the input text with the actual visuals generated.
Technical Explanation
The paper first reviews related work on evaluating and improving text-to-image generation, highlighting the challenge of object-attribute binding. The authors then propose a novel evaluation metric to measure this binding performance.
To improve binding, the authors experiment with attention calibration and an energy-based alignment model. They also introduce a severity-controlled generation approach to give users more control over the binding in the generated images.
Through extensive experiments, the paper provides insights into the factors affecting object-attribute binding, such as the complexity of the textual descriptions and the model architecture. The findings suggest opportunities to further enhance the alignment between text and image in T2I generation.
Critical Analysis
The paper makes a valuable contribution by systematically addressing the important issue of object-attribute binding in text-to-image generation. The proposed evaluation metric and techniques for improving binding performance are notable advancements.
However, the paper also acknowledges some limitations. The experiments are primarily conducted on a single dataset, so the generalizability of the findings to other domains or datasets is not fully established. Additionally, the paper does not explore the potential trade-offs between binding quality and other desirable properties of generated images, such as realism or diversity.
Further research could investigate the robustness of the proposed methods to different types of textual descriptions and model architectures. Exploring the interaction between binding and other aspects of text-to-image generation could also yield important insights.
Conclusion
This paper presents a comprehensive study of object-attribute binding in text-to-image generation. The authors introduce new evaluation metrics and techniques to improve the alignment between the semantic information in the input text and the visual outputs of T2I models.
The findings offer valuable insights into the factors affecting binding performance and demonstrate practical methods to give users more control over the binding in generated images. These advancements could contribute to the development of more semantically coherent and controllable text-to-image generation systems, with potential applications in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
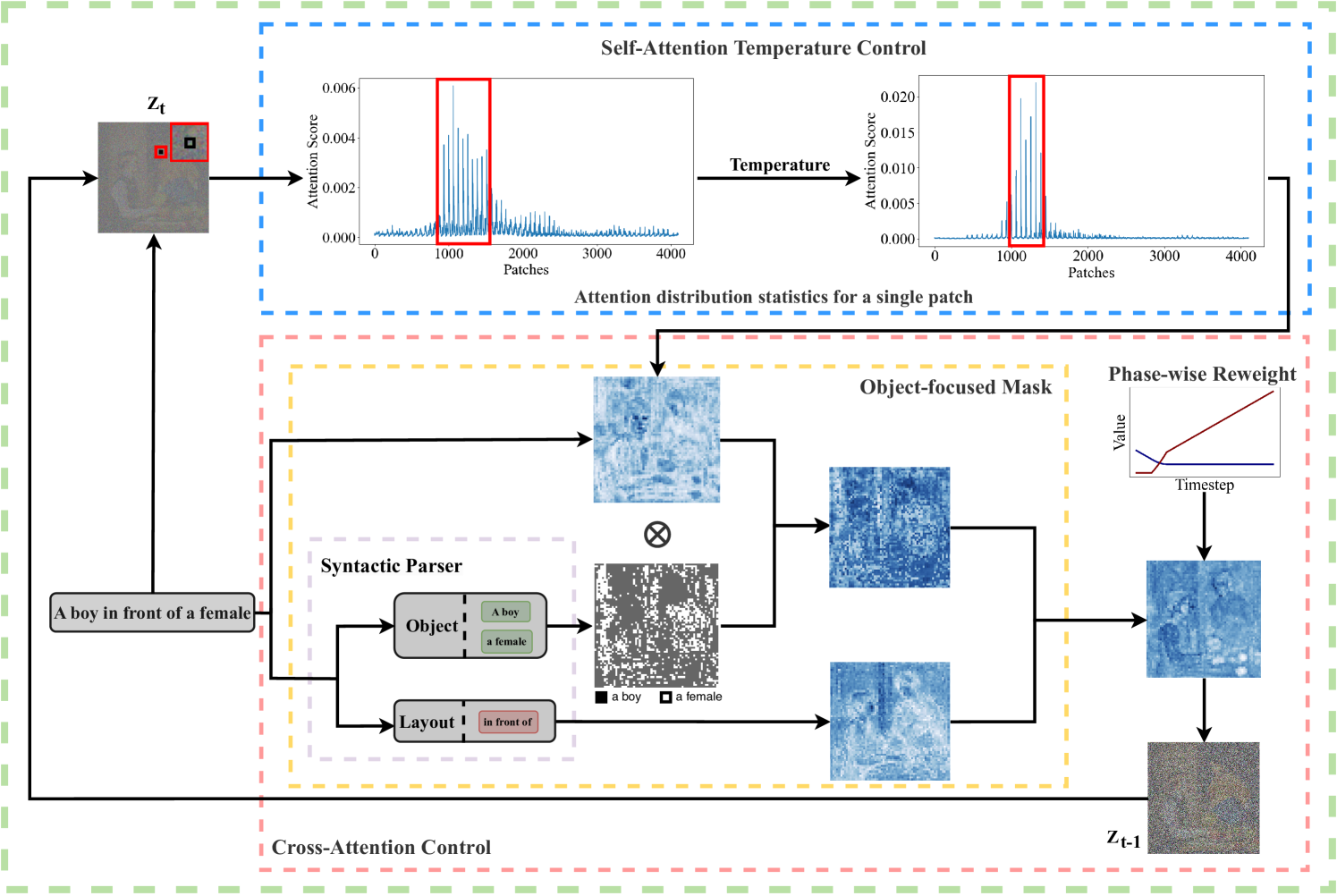
Towards Better Text-to-Image Generation Alignment via Attention Modulation
Yihang Wu, Xiao Cao, Kaixin Li, Zitan Chen, Haonan Wang, Lei Meng, Zhiyong Huang
0
0
In text-to-image generation tasks, the advancements of diffusion models have facilitated the fidelity of generated results. However, these models encounter challenges when processing text prompts containing multiple entities and attributes. The uneven distribution of attention results in the issues of entity leakage and attribute misalignment. Training from scratch to address this issue requires numerous labeled data and is resource-consuming. Motivated by this, we propose an attribution-focusing mechanism, a training-free phase-wise mechanism by modulation of attention for diffusion model. One of our core ideas is to guide the model to concentrate on the corresponding syntactic components of the prompt at distinct timesteps. To achieve this, we incorporate a temperature control mechanism within the early phases of the self-attention modules to mitigate entity leakage issues. An object-focused masking scheme and a phase-wise dynamic weight control mechanism are integrated into the cross-attention modules, enabling the model to discern the affiliation of semantic information between entities more effectively. The experimental results in various alignment scenarios demonstrate that our model attain better image-text alignment with minimal additional computational cost.
4/23/2024

Composing Object Relations and Attributes for Image-Text Matching
Khoi Pham, Chuong Huynh, Ser-Nam Lim, Abhinav Shrivastava
0
0
We study the visual semantic embedding problem for image-text matching. Most existing work utilizes a tailored cross-attention mechanism to perform local alignment across the two image and text modalities. This is computationally expensive, even though it is more powerful than the unimodal dual-encoder approach. This work introduces a dual-encoder image-text matching model, leveraging a scene graph to represent captions with nodes for objects and attributes interconnected by relational edges. Utilizing a graph attention network, our model efficiently encodes object-attribute and object-object semantic relations, resulting in a robust and fast-performing system. Representing caption as a scene graph offers the ability to utilize the strong relational inductive bias of graph neural networks to learn object-attribute and object-object relations effectively. To train the model, we propose losses that align the image and caption both at the holistic level (image-caption) and the local level (image-object entity), which we show is key to the success of the model. Our model is termed Composition model for Object Relations and Attributes, CORA. Experimental results on two prominent image-text retrieval benchmarks, Flickr30K and MSCOCO, demonstrate that CORA outperforms existing state-of-the-art computationally expensive cross-attention methods regarding recall score while achieving fast computation speed of the dual encoder.
6/18/2024
🛸
FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
Xuehai He, Jian Zheng, Jacob Zhiyuan Fang, Robinson Piramuthu, Mohit Bansal, Vicente Ordonez, Gunnar A Sigurdsson, Nanyun Peng, Xin Eric Wang
0
0
Controllable text-to-image (T2I) diffusion models generate images conditioned on both text prompts and semantic inputs of other modalities like edge maps. Nevertheless, current controllable T2I methods commonly face challenges related to efficiency and faithfulness, especially when conditioning on multiple inputs from either the same or diverse modalities. In this paper, we propose a novel Flexible and Efficient method, FlexEControl, for controllable T2I generation. At the core of FlexEControl is a unique weight decomposition strategy, which allows for streamlined integration of various input types. This approach not only enhances the faithfulness of the generated image to the control, but also significantly reduces the computational overhead typically associated with multimodal conditioning. Our approach achieves a reduction of 41% in trainable parameters and 30% in memory usage compared with Uni-ControlNet. Moreover, it doubles data efficiency and can flexibly generate images under the guidance of multiple input conditions of various modalities.
5/24/2024

Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Arman Zarei, Keivan Rezaei, Samyadeep Basu, Mehrdad Saberi, Mazda Moayeri, Priyatham Kattakinda, Soheil Feizi
0
0
Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
6/13/2024