AttributionScanner: A Visual Analytics System for Model Validation with Metadata-Free Slice Finding

0

Sign in to get full access
Overview
- This paper presents a visual analytics system called \systemname for validating machine learning models without relying on metadata.
- The system allows users to interactively explore and discover "data slices" - subsets of the data that reveal important insights about the model's behavior.
- \systemname employs novel techniques for data slice finding and visualization, enabling a more comprehensive understanding of model performance.
Plain English Explanation
\systemname is a tool that helps people understand how well a machine learning model is working, without needing to know a lot of background information about the data.
Traditional model validation often relies on metadata - extra information about the data, like what category each item belongs to. \systemname takes a different approach, allowing users to explore the data itself to find interesting "slices" or subsets that reveal important things about the model's strengths and weaknesses.
For example, the tool might help you discover that the model is doing a great job on images of dogs, but struggling with images of cats. This kind of insight can be really valuable for improving the model and making sure it works well across different types of data.
The key innovations in \systemname are the techniques it uses to efficiently find these informative data slices, and the visual interfaces that make it easy for users to explore and understand the model's behavior. By focusing on the data itself rather than metadata, \systemname provides a more comprehensive and insightful way to validate machine learning models.
Technical Explanation
The paper introduces a new visual analytics system called \systemname that enables model validation without relying on metadata. At the core of \systemname are novel techniques for data slice-finding and model interpretability visualization.
The data slice-finding algorithm works by efficiently searching the high-dimensional input space to identify subsets of the data (slices) that exhibit interesting model behavior, such as poor performance or high uncertainty. This is done in a "metadata-free" way, without requiring any external information about the data points.
To help users explore and understand these data slices, \systemname provides a range of interactive visualizations. These include individualized visual scanpath prediction techniques, which can highlight how the model is processing different parts of an input, as well as uncertainty-aware visualizations inspired by human-in-the-loop segmentation approaches.
The authors evaluate \systemname through a series of case studies, demonstrating its ability to uncover important insights about model behavior that would be difficult to obtain using traditional validation methods. For example, they show how \systemname can identify "blind spots" in a image classification model, where the model performs poorly on certain types of images despite high overall accuracy.
Critical Analysis
The \systemname approach represents an important step forward in model validation, addressing key limitations of existing techniques that rely heavily on metadata. By focusing on the data itself, the system can provide a more comprehensive and nuanced understanding of a model's strengths and weaknesses.
That said, the paper does not address some potential limitations of the data slice-finding algorithm. For example, the technique may struggle to identify meaningful slices in high-dimensional or sparse datasets, where the search space becomes exponentially larger. Additionally, the visualization techniques, while powerful, may not scale well to extremely large or complex models.
Further research is needed to address these challenges and explore ways to integrate \systemname with other XAI techniques for neural networks and knowledge-enhanced approaches for robust model validation. Nonetheless, the core ideas presented in this paper represent an important contribution to the field of machine learning interpretability and evaluation.
Conclusion
The \systemname system introduced in this paper provides a novel approach to model validation that overcomes the limitations of traditional metadata-based techniques. By focusing on the data itself, \systemname allows users to uncover important insights about a model's behavior that would be difficult to obtain otherwise.
The key innovations in \systemname - the data slice-finding algorithm and the interactive visualization tools - demonstrate the power of visual analytics for enhancing model understanding and guiding future improvements. As machine learning models become increasingly complex and ubiquitous, tools like \systemname will be essential for ensuring these models are transparent, trustworthy, and aligned with user needs.
Overall, this paper makes a valuable contribution to the field of machine learning interpretability and evaluation, paving the way for more robust and comprehensive model validation techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AttributionScanner: A Visual Analytics System for Model Validation with Metadata-Free Slice Finding
Xiwei Xuan, Jorge Piazentin Ono, Liang Gou, Kwan-Liu Ma, Liu Ren
Data slice finding is an emerging technique for validating machine learning (ML) models by identifying and analyzing subgroups in a dataset that exhibit poor performance, often characterized by distinct feature sets or descriptive metadata. However, in the context of validating vision models involving unstructured image data, this approach faces significant challenges, including the laborious and costly requirement for additional metadata and the complex task of interpreting the root causes of underperformance. To address these challenges, we introduce AttributionScanner, an innovative human-in-the-loop Visual Analytics (VA) system, designed for metadata-free data slice finding. Our system identifies interpretable data slices that involve common model behaviors and visualizes these patterns through an Attribution Mosaic design. Our interactive interface provides straightforward guidance for users to detect, interpret, and annotate predominant model issues, such as spurious correlations (model biases) and mislabeled data, with minimal effort. Additionally, it employs a cutting-edge model regularization technique to mitigate the detected issues and enhance the model's performance. The efficacy of AttributionScanner is demonstrated through use cases involving two benchmark datasets, with qualitative and quantitative evaluations showcasing its substantial effectiveness in vision model validation, ultimately leading to more reliable and accurate models.
Read more5/7/2024
0
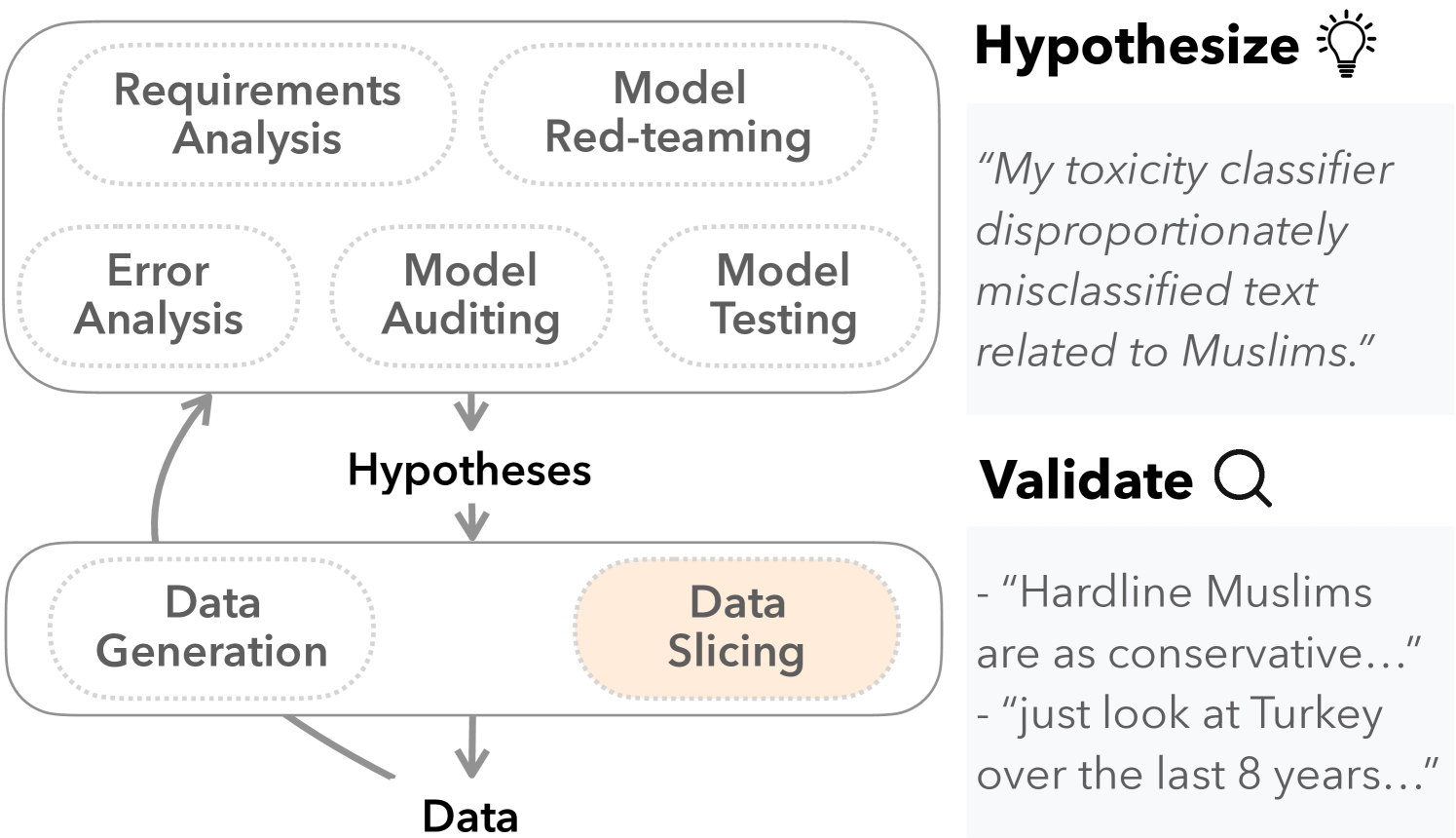
What Is Wrong with My Model? Identifying Systematic Problems with Semantic Data Slicing
Chenyang Yang, Yining Hong, Grace A. Lewis, Tongshuang Wu, Christian Kastner
Machine learning models make mistakes, yet sometimes it is difficult to identify the systematic problems behind the mistakes. Practitioners engage in various activities, including error analysis, testing, auditing, and red-teaming, to form hypotheses of what can go (or has gone) wrong with their models. To validate these hypotheses, practitioners employ data slicing to identify relevant examples. However, traditional data slicing is limited by available features and programmatic slicing functions. In this work, we propose SemSlicer, a framework that supports semantic data slicing, which identifies a semantically coherent slice, without the need for existing features. SemSlicer uses Large Language Models to annotate datasets and generate slices from any user-defined slicing criteria. We show that SemSlicer generates accurate slices with low cost, allows flexible trade-offs between different design dimensions, reliably identifies under-performing data slices, and helps practitioners identify useful data slices that reflect systematic problems.
Read more9/17/2024
0
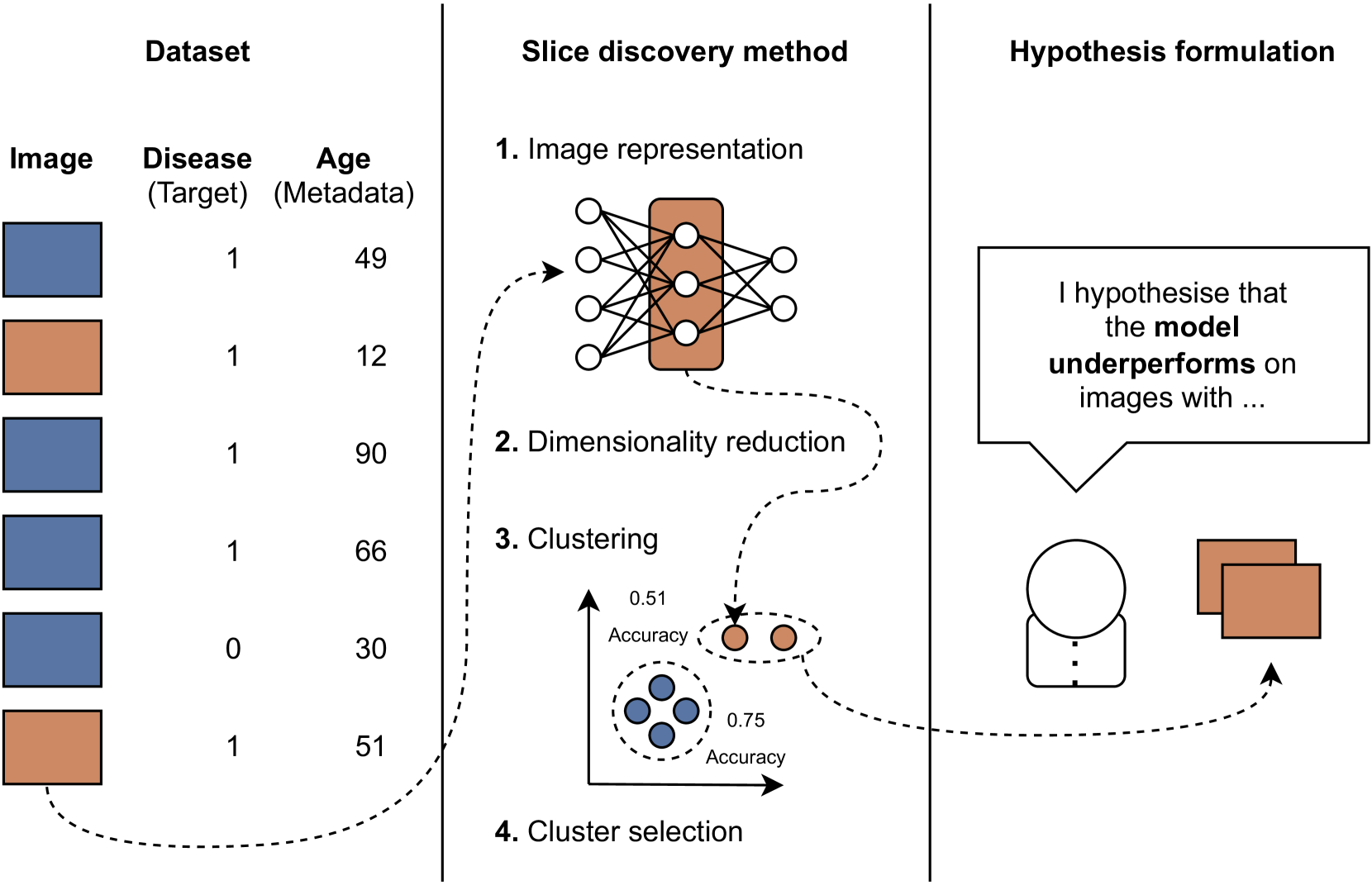
Slicing Through Bias: Explaining Performance Gaps in Medical Image Analysis using Slice Discovery Methods
Vincent Olesen, Nina Weng, Aasa Feragen, Eike Petersen
Machine learning models have achieved high overall accuracy in medical image analysis. However, performance disparities on specific patient groups pose challenges to their clinical utility, safety, and fairness. This can affect known patient groups - such as those based on sex, age, or disease subtype - as well as previously unknown and unlabeled groups. Furthermore, the root cause of such observed performance disparities is often challenging to uncover, hindering mitigation efforts. In this paper, to address these issues, we leverage Slice Discovery Methods (SDMs) to identify interpretable underperforming subsets of data and formulate hypotheses regarding the cause of observed performance disparities. We introduce a novel SDM and apply it in a case study on the classification of pneumothorax and atelectasis from chest x-rays. Our study demonstrates the effectiveness of SDMs in hypothesis formulation and yields an explanation of previously observed but unexplained performance disparities between male and female patients in widely used chest X-ray datasets and models. Our findings indicate shortcut learning in both classification tasks, through the presence of chest drains and ECG wires, respectively. Sex-based differences in the prevalence of these shortcut features appear to cause the observed classification performance gap, representing a previously underappreciated interaction between shortcut learning and model fairness analyses.
Read more6/19/2024
👀
0
Benchmarking the Attribution Quality of Vision Models
Robin Hesse, Simone Schaub-Meyer, Stefan Roth
Attribution maps are one of the most established tools to explain the functioning of computer vision models. They assign importance scores to input features, indicating how relevant each feature is for the prediction of a deep neural network. While much research has gone into proposing new attribution methods, their proper evaluation remains a difficult challenge. In this work, we propose a novel evaluation protocol that overcomes two fundamental limitations of the widely used incremental-deletion protocol, i.e., the out-of-domain issue and lacking inter-model comparisons. This allows us to evaluate 23 attribution methods and how eight different design choices of popular vision models affect their attribution quality. We find that intrinsically explainable models outperform standard models and that raw attribution values exhibit a higher attribution quality than what is known from previous work. Further, we show consistent changes in the attribution quality when varying the network design, indicating that some standard design choices promote attribution quality.
Read more7/17/2024