Audio Conditioning for Music Generation via Discrete Bottleneck Features

0

Sign in to get full access
Overview
- This paper proposes a method for generating high-quality music conditioned on text prompts, leveraging discrete bottleneck features to bridge the gap between audio and text representations.
- The authors introduce a novel model architecture and training approach that enables the generation of coherent and expressive music aligned with semantic text descriptions.
- The research explores ways to integrate audio and textual conditioning signals to achieve more interpretable and controllable music generation, building on recent advancements in text-guided music generation and text-conditioned music generation.
Plain English Explanation
The paper presents a new way to generate music based on written descriptions. The key idea is to use a "discrete bottleneck" - a layer in the neural network that compresses the audio information into a more compact, discrete representation. This discrete representation acts as a bridge between the audio and the text, allowing the model to learn how to generate music that matches the semantic meaning of the text prompt.
For example, if you provide a text description like "a peaceful, melancholic piano piece," the model can use the discrete bottleneck features to generate piano music that evokes those emotional qualities. The discrete nature of the bottleneck features makes the model's decisions more interpretable, giving users more control over the generated music.
This approach builds on recent progress in text-guided music generation and text-conditioned music generation, aiming to create a more seamless integration between the textual and audio domains. By connecting the text to the underlying musical structure, the model can produce cohesive and expressive music that aligns with the semantic meaning of the input description.
Technical Explanation
The paper introduces a novel model architecture that incorporates a discrete bottleneck layer to bridge the gap between audio and text representations. This discrete bottleneck encodes the audio input into a compact, categorical representation, which is then used as a conditioning signal for the music generation process.
The model consists of an audio encoder that converts the input audio into the discrete bottleneck features, and a music generator that takes the discrete features and the text prompt as input to produce the final musical output. The discrete bottleneck features act as an intermediate representation that allows the model to learn how to translate between the audio and textual domains.
The authors also propose a new training approach that involves pre-training the audio encoder on a large corpus of music data, then fine-tuning the entire model on a dataset that pairs audio with corresponding text descriptions. This multi-stage training process helps the model learn robust audio-text associations, enabling it to generate music that is closely aligned with the semantics of the input text, as demonstrated in joint audio-symbolic conditioning for temporally controlled text-to-music generation.
The discrete bottleneck features provide a level of interpretability and control that is not present in traditional continuous latent representations, as explored in ICGAN: An Implicit Conditioning Method for Interpretable Feature Control. By making the audio representation more discrete and structured, the model can generate music that is more closely tied to the semantic meaning of the text prompt, as well as enable fine-grained control over the musical attributes, such as mood, genre, and instrumentation.
Critical Analysis
The paper presents a compelling approach to bridging the gap between text and music generation, but there are a few potential limitations and areas for further research:
-
The authors mention that the model is trained on a relatively small dataset of text-audio pairs, which may limit its ability to generalize to a wide range of musical styles and semantic concepts. Scaling up the training data could be an important next step.
-
The paper does not provide a detailed analysis of the interpretability and controllability of the discrete bottleneck features. Further investigation into how these features correspond to specific musical attributes would be valuable for understanding the model's inner workings and improving its usability.
-
The authors acknowledge that the generated music may still exhibit some inconsistencies or lack of coherence, particularly over longer time scales. Incorporating additional structural and temporal modeling techniques, as explored in fast timing-conditioned latent audio diffusion, could help address this limitation.
-
While the discrete bottleneck approach is promising, it is unclear how it compares to other strategies for integrating text and audio, such as the joint audio-symbolic conditioning or implicit conditioning methods. A more comprehensive comparison would help situate this work within the broader context of text-guided music generation.
Overall, the paper presents an innovative approach to text-guided music generation that leverages discrete bottleneck features to bridge the audio-text gap. Further research and refinement of the model could lead to significant advancements in the field of interpretable and controllable music generation.
Conclusion
This paper introduces a novel method for generating high-quality music conditioned on textual descriptions, using a discrete bottleneck feature representation to connect the audio and semantic domains. The proposed model architecture and training approach demonstrate the potential for creating more interpretable and controllable text-guided music generation systems, building on recent progress in the field.
By using a discrete bottleneck as an intermediate representation, the model is able to learn robust associations between text prompts and the underlying musical structure, enabling the generation of coherent and expressive music that aligns with the semantic meaning of the input. This work represents an important step towards bridging the gap between text and music generation, with potential applications in creative assistants, music composition, and interactive entertainment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Audio Conditioning for Music Generation via Discrete Bottleneck Features
Simon Rouard, Yossi Adi, Jade Copet, Axel Roebel, Alexandre D'efossez
While most music generation models use textual or parametric conditioning (e.g. tempo, harmony, musical genre), we propose to condition a language model based music generation system with audio input. Our exploration involves two distinct strategies. The first strategy, termed textual inversion, leverages a pre-trained text-to-music model to map audio input to corresponding pseudowords in the textual embedding space. For the second model we train a music language model from scratch jointly with a text conditioner and a quantized audio feature extractor. At inference time, we can mix textual and audio conditioning and balance them thanks to a novel double classifier free guidance method. We conduct automatic and human studies that validates our approach. We will release the code and we provide music samples on https://musicgenstyle.github.io in order to show the quality of our model.
Read more7/31/2024

0
Generating Sample-Based Musical Instruments Using Neural Audio Codec Language Models
Shahan Nercessian, Johannes Imort, Ninon Devis, Frederik Blang
In this paper, we propose and investigate the use of neural audio codec language models for the automatic generation of sample-based musical instruments based on text or reference audio prompts. Our approach extends a generative audio framework to condition on pitch across an 88-key spectrum, velocity, and a combined text/audio embedding. We identify maintaining timbral consistency within the generated instruments as a major challenge. To tackle this issue, we introduce three distinct conditioning schemes. We analyze our methods through objective metrics and human listening tests, demonstrating that our approach can produce compelling musical instruments. Specifically, we introduce a new objective metric to evaluate the timbral consistency of the generated instruments and adapt the average Contrastive Language-Audio Pretraining (CLAP) score for the text-to-instrument case, noting that its naive application is unsuitable for assessing this task. Our findings reveal a complex interplay between timbral consistency, the quality of generated samples, and their correspondence to the input prompt.
Read more7/23/2024
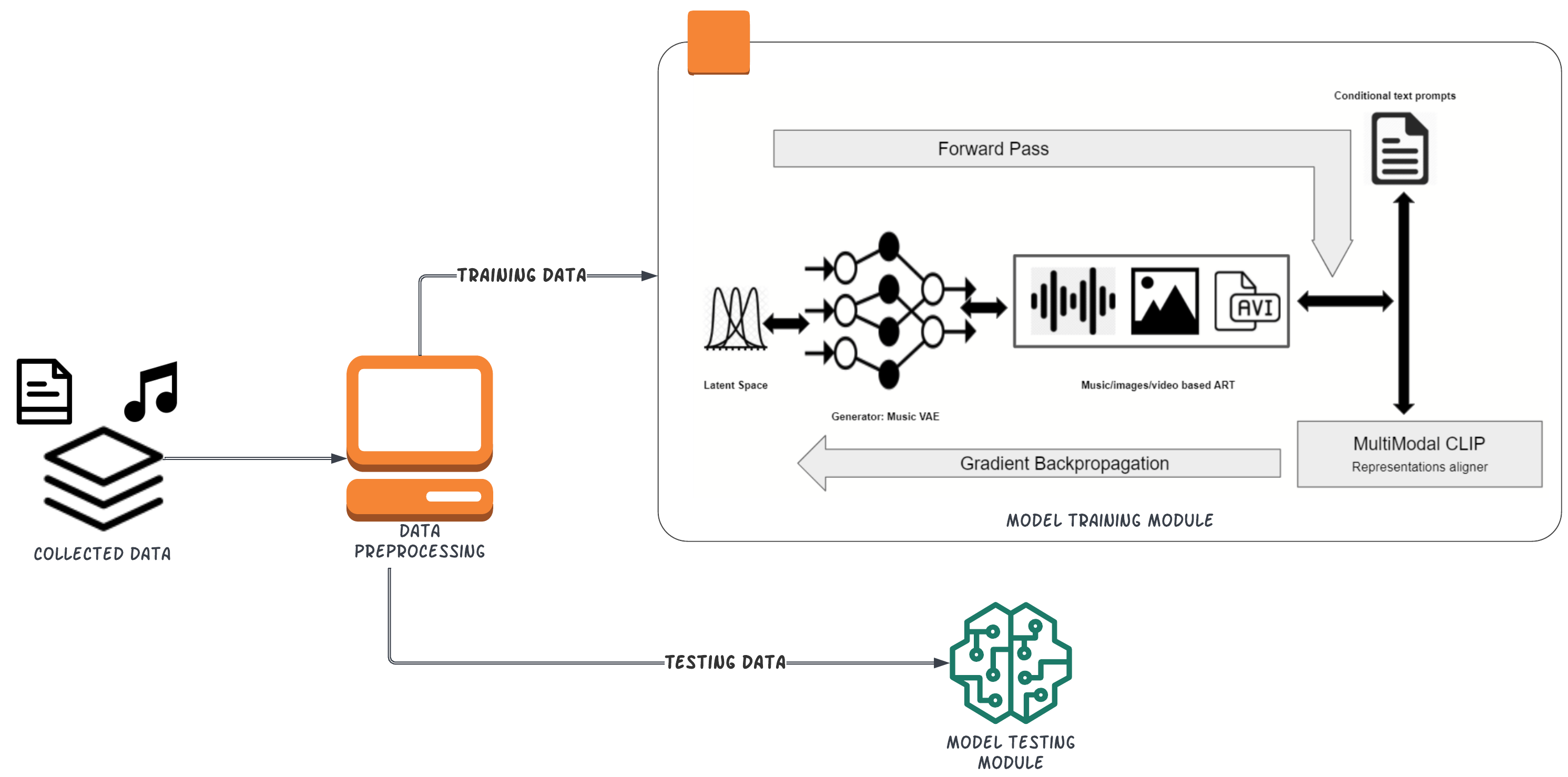
0
Intelligent Text-Conditioned Music Generation
Zhouyao Xie, Nikhil Yadala, Xinyi Chen, Jing Xi Liu
CLIP (Contrastive Language-Image Pre-Training) is a multimodal neural network trained on (text, image) pairs to predict the most relevant text caption given an image. It has been used extensively in image generation by connecting its output with a generative model such as VQGAN, with the most notable example being OpenAI's DALLE-2. In this project, we apply a similar approach to bridge the gap between natural language and music. Our model is split into two steps: first, we train a CLIP-like model on pairs of text and music over contrastive loss to align a piece of music with its most probable text caption. Then, we combine the alignment model with a music decoder to generate music. To the best of our knowledge, this is the first attempt at text-conditioned deep music generation. Our experiments show that it is possible to train the text-music alignment model using contrastive loss and train a decoder to generate music from text prompts.
Read more6/4/2024

0
High Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching
Gael Le Lan, Bowen Shi, Zhaoheng Ni, Sidd Srinivasan, Anurag Kumar, Brian Ellis, David Kant, Varun Nagaraja, Ernie Chang, Wei-Ning Hsu, Yangyang Shi, Vikas Chandra
We introduce a simple and efficient text-controllable high-fidelity music generation and editing model. It operates on sequences of continuous latent representations from a low frame rate 48 kHz stereo variational auto encoder codec that eliminates the information loss drawback of discrete representations. Based on a diffusion transformer architecture trained on a flow-matching objective the model can generate and edit diverse high quality stereo samples of variable duration, with simple text descriptions. We also explore a new regularized latent inversion method for zero-shot test-time text-guided editing and demonstrate its superior performance over naive denoising diffusion implicit model (DDIM) inversion for variety of music editing prompts. Evaluations are conducted on both objective and subjective metrics and demonstrate that the proposed model is not only competitive to the evaluated baselines on a standard text-to-music benchmark - quality and efficiency-wise - but also outperforms previous state of the art for music editing when combined with our proposed latent inversion. Samples are available at https://melodyflow.github.io.
Read more7/8/2024