Auto-configuring Exploration-Exploitation Tradeoff in Evolutionary Computation via Deep Reinforcement Learning
2404.08239
0
0

Abstract
Evolutionary computation (EC) algorithms, renowned as powerful black-box optimizers, leverage a group of individuals to cooperatively search for the optimum. The exploration-exploitation tradeoff (EET) plays a crucial role in EC, which, however, has traditionally been governed by manually designed rules. In this paper, we propose a deep reinforcement learning-based framework that autonomously configures and adapts the EET throughout the EC search process. The framework allows different individuals of the population to selectively attend to the global and local exemplars based on the current search state, maximizing the cooperative search outcome. Our proposed framework is characterized by its simplicity, effectiveness, and generalizability, with the potential to enhance numerous existing EC algorithms. To validate its capabilities, we apply our framework to several representative EC algorithms and conduct extensive experiments on the augmented CEC2021 benchmark. The results demonstrate significant improvements in the performance of the backbone algorithms, as well as favorable generalization across diverse problem classes, dimensions, and population sizes. Additionally, we provide an in-depth analysis of the EET issue by interpreting the learned behaviors of EC.
Create account to get full access
Overview
- This paper proposes a deep reinforcement learning approach to automatically configure the exploration-exploitation tradeoff in evolutionary computation algorithms.
- The method aims to dynamically adjust the balance between exploration (searching for new solutions) and exploitation (optimizing known good solutions) during the optimization process.
- This is an important challenge in evolutionary computation, as getting the right balance can significantly impact algorithm performance.
Plain English Explanation
The paper is about a new way to help evolutionary computation algorithms work better. Evolutionary algorithms are a type of optimization technique that takes inspiration from natural selection and evolution. They work by generating a population of candidate solutions, and then iteratively selecting and modifying the best ones to gradually improve the solutions over time.
A key challenge in evolutionary algorithms is finding the right balance between
The researchers in this paper propose using deep reinforcement learning to automatically configure this exploration-exploitation tradeoff. Reinforcement learning is a type of machine learning where an agent learns to make good decisions by trying different actions and getting feedback on how well they work. By applying reinforcement learning to the exploration-exploitation problem, the algorithm can learn how to dynamically adjust the balance based on the current state of the optimization process.
The key idea is to train a deep neural network model that takes in information about the current state of the evolutionary algorithm (e.g. the diversity of the population, the quality of the best solutions so far) and outputs a recommended exploration-exploitation setting. This allows the algorithm to adapt its behavior on the fly, rather than using a fixed, pre-determined setting.
The paper demonstrates the effectiveness of this approach through experiments on standard benchmark problems, showing that the self-configuring algorithm can outperform traditional evolutionary algorithms with manually tuned settings.
Technical Explanation
The paper proposes a deep reinforcement learning (DRL) approach to automatically configure the exploration-exploitation tradeoff in evolutionary computation algorithms like differential evolution and particle swarm optimization.
The key components are:
-
State Representation: The current state of the evolutionary algorithm is represented by features like the diversity of the population, the quality of the best solutions found so far, and the current exploration-exploitation setting.
-
Action Space: The action space consists of different exploration-exploitation settings that can be applied, such as the mutation rate, crossover probability, and selection pressure.
-
Reward Function: The reward function encourages the DRL agent to find settings that lead to faster convergence and better final solutions on the optimization problem.
-
DRL Agent: A deep neural network is trained as the DRL agent, taking the current state as input and outputting the recommended exploration-exploitation setting.
During optimization, the evolutionary algorithm periodically queries the DRL agent for the recommended settings, which are then applied. This allows the exploration-exploitation tradeoff to be adjusted dynamically based on the current state of the search process.
The paper evaluates this approach on standard benchmark problems for differential evolution and particle swarm optimization, comparing it to manually tuned algorithms. The results show that the self-configuring DRL-based approach can outperform the manual tuning, demonstrating the value of automatically adapting the exploration-exploitation balance.
Critical Analysis
The paper presents a novel and promising approach to a long-standing challenge in evolutionary computation. By leveraging deep reinforcement learning, the method can dynamically adjust the exploration-exploitation tradeoff in a way that outperforms manually tuned algorithms.
One potential limitation is the complexity of training the DRL agent, which may require significant computational resources and careful hyperparameter tuning. The authors do not provide detailed information about the training process or the computational cost of their approach.
Additionally, the paper only evaluates the method on benchmark problems, which may not fully capture the diversity of real-world optimization challenges. Further research is needed to understand how well the approach generalizes to more complex, domain-specific optimization tasks.
Another area for further investigation is the interpretability of the DRL agent's decision-making process. While the method is effective, it operates as a black box, making it difficult to understand why particular exploration-exploitation settings are recommended. Incorporating more interpretable techniques could enhance the transparency and trust in the system.
Overall, the paper presents an innovative and promising approach to a fundamental challenge in evolutionary computation. The use of deep reinforcement learning to automatically configure the exploration-exploitation tradeoff is a significant contribution to the field, and the results demonstrate the potential benefits of this technique. Further research to address the limitations and explore real-world applications would be valuable.
Conclusion
This paper introduces a deep reinforcement learning approach to automatically configure the exploration-exploitation tradeoff in evolutionary computation algorithms. By training a DRL agent to dynamically adjust the balance between exploration and exploitation, the method can outperform traditional algorithms with manually tuned settings.
The key innovation is the use of deep learning to learn the optimal exploration-exploitation strategy directly from the optimization process, rather than relying on predefined, static settings. This allows the algorithm to adapt its behavior to the current state of the search, leading to faster convergence and better final solutions.
The results on benchmark problems are promising and demonstrate the potential of this approach to enhance the performance of evolutionary computation techniques. Further research is needed to address the complexity of training the DRL agent, explore the interpretability of the decision-making process, and evaluate the method on a wider range of real-world optimization challenges.
Overall, this paper represents an important step forward in the field of evolutionary computation, showcasing the power of adaptive and self-configuring techniques to improve the optimization performance of nature-inspired algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Evolutionary Reinforcement Learning via Cooperative Coevolution
Chengpeng Hu, Jialin Liu, Xin Yao
0
0
Recently, evolutionary reinforcement learning has obtained much attention in various domains. Maintaining a population of actors, evolutionary reinforcement learning utilises the collected experiences to improve the behaviour policy through efficient exploration. However, the poor scalability of genetic operators limits the efficiency of optimising high-dimensional neural networks. To address this issue, this paper proposes a novel cooperative coevolutionary reinforcement learning (CoERL) algorithm. Inspired by cooperative coevolution, CoERL periodically and adaptively decomposes the policy optimisation problem into multiple subproblems and evolves a population of neural networks for each of the subproblems. Instead of using genetic operators, CoERL directly searches for partial gradients to update the policy. Updating policy with partial gradients maintains consistency between the behaviour spaces of parents and offspring across generations. The experiences collected by the population are then used to improve the entire policy, which enhances the sampling efficiency. Experiments on six benchmark locomotion tasks demonstrate that CoERL outperforms seven state-of-the-art algorithms and baselines. Ablation study verifies the unique contribution of CoERL's core ingredients.
4/30/2024

Hard-Thresholding Meets Evolution Strategies in Reinforcement Learning
Chengqian Gao, William de Vazelhes, Hualin Zhang, Bin Gu, Zhiqiang Xu
0
0
Evolution Strategies (ES) have emerged as a competitive alternative for model-free reinforcement learning, showcasing exemplary performance in tasks like Mujoco and Atari. Notably, they shine in scenarios with imperfect reward functions, making them invaluable for real-world applications where dense reward signals may be elusive. Yet, an inherent assumption in ES, that all input features are task-relevant, poses challenges, especially when confronted with irrelevant features common in real-world problems. This work scrutinizes this limitation, particularly focusing on the Natural Evolution Strategies (NES) variant. We propose NESHT, a novel approach that integrates Hard-Thresholding (HT) with NES to champion sparsity, ensuring only pertinent features are employed. Backed by rigorous analysis and empirical tests, NESHT demonstrates its promise in mitigating the pitfalls of irrelevant features and shines in complex decision-making problems like noisy Mujoco and Atari tasks.
5/6/2024
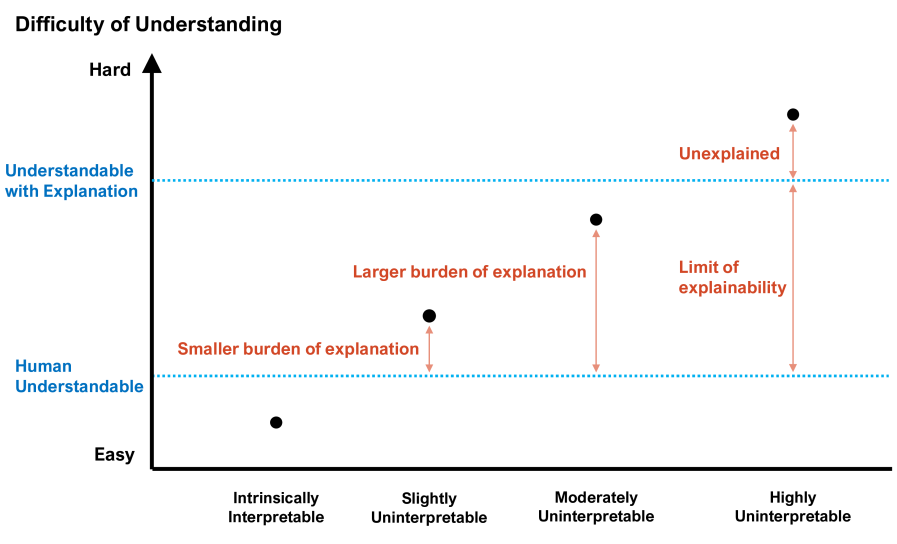
Evolutionary Computation and Explainable AI: A Roadmap to Transparent Intelligent Systems
Ryan Zhou, Jaume Bacardit, Alexander Brownlee, Stefano Cagnoni, Martin Fyvie, Giovanni Iacca, John McCall, Niki van Stein, David Walker, Ting Hu
0
0
AI methods are finding an increasing number of applications, but their often black-box nature has raised concerns about accountability and trust. The field of explainable artificial intelligence (XAI) has emerged in response to the need for human understanding of AI models. Evolutionary computation (EC), as a family of powerful optimization and learning tools, has significant potential to contribute to XAI. In this paper, we provide an introduction to XAI and review various techniques in current use for explaining machine learning (ML) models. We then focus on how EC can be used in XAI, and review some XAI approaches which incorporate EC techniques. Additionally, we discuss the application of XAI principles within EC itself, examining how these principles can shed some light on the behavior and outcomes of EC algorithms in general, on the (automatic) configuration of these algorithms, and on the underlying problem landscapes that these algorithms optimize. Finally, we discuss some open challenges in XAI and opportunities for future research in this field using EC. Our aim is to demonstrate that EC is well-suited for addressing current problems in explainability and to encourage further exploration of these methods to contribute to the development of more transparent and trustworthy ML models and EC algorithms.
6/13/2024
👀
Intrinsic Rewards for Exploration without Harm from Observational Noise: A Simulation Study Based on the Free Energy Principle
Theodore Jerome Tinker, Kenji Doya, Jun Tani
0
0
In Reinforcement Learning (RL), artificial agents are trained to maximize numerical rewards by performing tasks. Exploration is essential in RL because agents must discover information before exploiting it. Two rewards encouraging efficient exploration are the entropy of action policy and curiosity for information gain. Entropy is well-established in literature, promoting randomized action selection. Curiosity is defined in a broad variety of ways in literature, promoting discovery of novel experiences. One example, prediction error curiosity, rewards agents for discovering observations they cannot accurately predict. However, such agents may be distracted by unpredictable observational noises known as curiosity traps. Based on the Free Energy Principle (FEP), this paper proposes hidden state curiosity, which rewards agents by the KL divergence between the predictive prior and posterior probabilities of latent variables. We trained six types of agents to navigate mazes: baseline agents without rewards for entropy or curiosity, and agents rewarded for entropy and/or either prediction error curiosity or hidden state curiosity. We find entropy and curiosity result in efficient exploration, especially both employed together. Notably, agents with hidden state curiosity demonstrate resilience against curiosity traps, which hinder agents with prediction error curiosity. This suggests implementing the FEP may enhance the robustness and generalization of RL models, potentially aligning the learning processes of artificial and biological agents.
5/14/2024