Evolutionary Reinforcement Learning via Cooperative Coevolution
2404.14763
0
0
🏅
Abstract
Recently, evolutionary reinforcement learning has obtained much attention in various domains. Maintaining a population of actors, evolutionary reinforcement learning utilises the collected experiences to improve the behaviour policy through efficient exploration. However, the poor scalability of genetic operators limits the efficiency of optimising high-dimensional neural networks. To address this issue, this paper proposes a novel cooperative coevolutionary reinforcement learning (CoERL) algorithm. Inspired by cooperative coevolution, CoERL periodically and adaptively decomposes the policy optimisation problem into multiple subproblems and evolves a population of neural networks for each of the subproblems. Instead of using genetic operators, CoERL directly searches for partial gradients to update the policy. Updating policy with partial gradients maintains consistency between the behaviour spaces of parents and offspring across generations. The experiences collected by the population are then used to improve the entire policy, which enhances the sampling efficiency. Experiments on six benchmark locomotion tasks demonstrate that CoERL outperforms seven state-of-the-art algorithms and baselines. Ablation study verifies the unique contribution of CoERL's core ingredients.
Create account to get full access
Overview
- Evolutionary reinforcement learning has gained attention for its ability to efficiently explore and improve behavior policies using a population of agents.
- However, the poor scalability of genetic operators limits the efficiency of optimizing high-dimensional neural networks.
- The paper proposes a novel cooperative coevolutionary reinforcement learning (CoERL) algorithm to address this issue.
Plain English Explanation
Evolutionary reinforcement learning is a technique that uses a population of agents, or actors, to explore and improve behavior policies. This is done by collecting experiences from the agents and using that information to refine the policies over time. However, the traditional genetic operators used in this approach don't work well for optimizing large, complex neural networks.
To solve this problem, the researchers developed a new algorithm called CoERL. Inspired by the concept of cooperative coevolution, CoERL periodically breaks down the policy optimization problem into smaller subproblems. It then evolves a population of neural networks to solve each subproblem, using partial gradients instead of genetic operators to update the policies.
This approach maintains consistency between the behavior spaces of parent and offspring policies, which enhances the sampling efficiency of the system. The experiences collected by the population are then used to improve the entire policy, further boosting the algorithm's performance.
Technical Explanation
The CoERL algorithm works by periodically and adaptively decomposing the policy optimization problem into multiple subproblems. It then evolves a population of neural networks to solve each of these subproblems, using partial gradients to update the policies instead of traditional genetic operators.
This approach has several key advantages:
-
Partial Gradient Updates: By using partial gradients to update the policies, CoERL maintains consistency between the behavior spaces of parent and offspring policies. This helps to improve the sampling efficiency of the system.
-
Subproblem Decomposition: Breaking down the optimization problem into smaller subproblems makes it easier for the algorithm to find high-performing solutions, especially for large, complex neural networks.
-
Population-Based Exploration: The use of a population of agents, rather than a single agent, allows CoERL to explore the search space more thoroughly and find better solutions.
The researchers evaluated CoERL on six benchmark locomotion tasks and found that it outperformed seven state-of-the-art algorithms and baselines. An ablation study also verified the unique contributions of CoERL's core components.
Critical Analysis
The paper presents a novel and promising approach to addressing the scalability limitations of traditional evolutionary reinforcement learning methods. The use of cooperative coevolution and partial gradient updates is a clever way to optimize high-dimensional neural networks while maintaining sampling efficiency.
However, the paper does not discuss the computational overhead associated with the subproblem decomposition and population-based optimization. It would be valuable to understand the trade-offs between the performance gains and the increased computational requirements.
Additionally, the paper focuses on locomotion tasks, which may not fully capture the breadth of challenges faced in real-world reinforcement learning problems. Further evaluation on a wider range of tasks, including more complex and dynamic environments, would help to better assess the generalizability of the CoERL approach.
Conclusion
The CoERL algorithm proposed in this paper represents a significant advance in the field of evolutionary reinforcement learning. By combining cooperative coevolution with partial gradient updates, the researchers have developed a scalable and efficient method for optimizing high-dimensional neural networks.
The promising results on benchmark locomotion tasks suggest that CoERL could have a wide range of applications in areas such as robotics, game AI, and autonomous systems. As the field of reinforcement learning continues to evolve, algorithms like CoERL will play an increasingly important role in enabling more sophisticated and capable artificial agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Bridging Evolutionary Algorithms and Reinforcement Learning: A Comprehensive Survey on Hybrid Algorithms
Pengyi Li, Jianye Hao, Hongyao Tang, Xian Fu, Yan Zheng, Ke Tang
0
0
Evolutionary Reinforcement Learning (ERL), which integrates Evolutionary Algorithms (EAs) and Reinforcement Learning (RL) for optimization, has demonstrated remarkable performance advancements. By fusing both approaches, ERL has emerged as a promising research direction. This survey offers a comprehensive overview of the diverse research branches in ERL. Specifically, we systematically summarize recent advancements in related algorithms and identify three primary research directions: EA-assisted Optimization of RL, RL-assisted Optimization of EA, and synergistic optimization of EA and RL. Following that, we conduct an in-depth analysis of each research direction, organizing multiple research branches. We elucidate the problems that each branch aims to tackle and how the integration of EAs and RL addresses these challenges. In conclusion, we discuss potential challenges and prospective future research directions across various research directions. To facilitate researchers in delving into ERL, we organize the algorithms and codes involved on https://github.com/yeshenpy/Awesome-Evolutionary-Reinforcement-Learning.
6/26/2024

Auto-configuring Exploration-Exploitation Tradeoff in Evolutionary Computation via Deep Reinforcement Learning
Zeyuan Ma, Jiacheng Chen, Hongshu Guo, Yining Ma, Yue-Jiao Gong
0
0
Evolutionary computation (EC) algorithms, renowned as powerful black-box optimizers, leverage a group of individuals to cooperatively search for the optimum. The exploration-exploitation tradeoff (EET) plays a crucial role in EC, which, however, has traditionally been governed by manually designed rules. In this paper, we propose a deep reinforcement learning-based framework that autonomously configures and adapts the EET throughout the EC search process. The framework allows different individuals of the population to selectively attend to the global and local exemplars based on the current search state, maximizing the cooperative search outcome. Our proposed framework is characterized by its simplicity, effectiveness, and generalizability, with the potential to enhance numerous existing EC algorithms. To validate its capabilities, we apply our framework to several representative EC algorithms and conduct extensive experiments on the augmented CEC2021 benchmark. The results demonstrate significant improvements in the performance of the backbone algorithms, as well as favorable generalization across diverse problem classes, dimensions, and population sizes. Additionally, we provide an in-depth analysis of the EET issue by interpreting the learned behaviors of EC.
4/15/2024
Efficient Reinforcement Learning via Decoupling Exploration and Utilization
Jingpu Yang, Helin Wang, Qirui Zhao, Zhecheng Shi, Zirui Song, Miao Fang
0
0
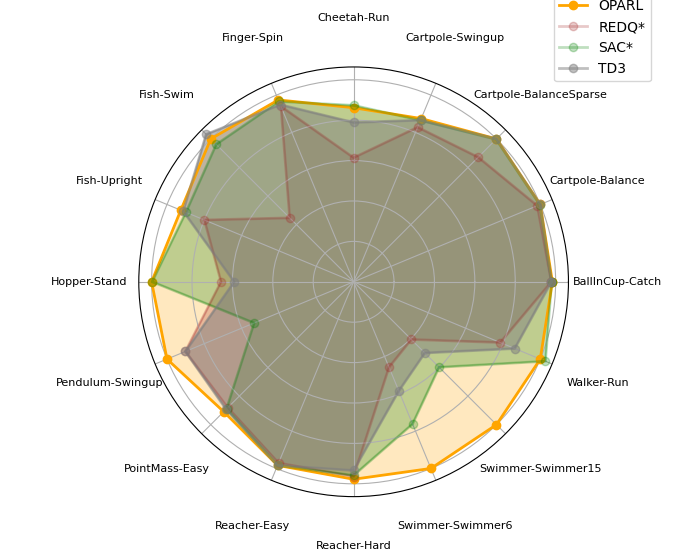
Reinforcement Learning (RL), recognized as an efficient learning approach, has achieved remarkable success across multiple fields and applications, including gaming, robotics, and autonomous vehicles. Classical single-agent reinforcement learning grapples with the imbalance of exploration and exploitation as well as limited generalization abilities. This methodology frequently leads to algorithms settling for suboptimal solutions that are tailored only to specific datasets. In this work, our aim is to train agent with efficient learning by decoupling exploration and utilization, so that agent can escaping the conundrum of suboptimal Solutions. In reinforcement learning, the previously imposed pessimistic punitive measures have deprived the model of its exploratory potential, resulting in diminished exploration capabilities. To address this, we have introduced an additional optimistic Actor to enhance the model's exploration ability, while employing a more constrained pessimistic Actor for performance evaluation. The above idea is implemented in the proposed OPARL (Optimistic and Pessimistic Actor Reinforcement Learning) algorithm. This unique amalgamation within the reinforcement learning paradigm fosters a more balanced and efficient approach. It facilitates the optimization of policies that concentrate on high-reward actions via pessimistic exploitation strategies while concurrently ensuring extensive state coverage through optimistic exploration. Empirical and theoretical investigations demonstrate that OPARL enhances agent capabilities in both utilization and exploration. In the most tasks of DMControl benchmark and Mujoco environment, OPARL performed better than state-of-the-art methods. Our code has released on https://github.com/yydsok/OPARL
5/13/2024
Enhancing Cooperation through Selective Interaction and Long-term Experiences in Multi-Agent Reinforcement Learning
Tianyu Ren, Xiao-Jun Zeng
0
0
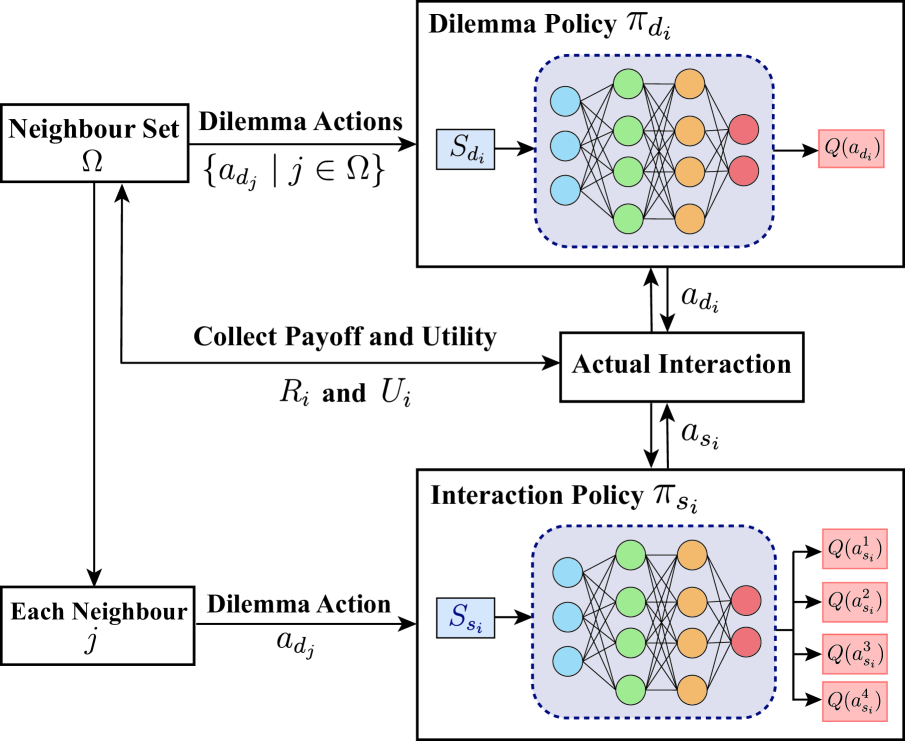
The significance of network structures in promoting group cooperation within social dilemmas has been widely recognized. Prior studies attribute this facilitation to the assortment of strategies driven by spatial interactions. Although reinforcement learning has been employed to investigate the impact of dynamic interaction on the evolution of cooperation, there remains a lack of understanding about how agents develop neighbour selection behaviours and the formation of strategic assortment within an explicit interaction structure. To address this, our study introduces a computational framework based on multi-agent reinforcement learning in the spatial Prisoner's Dilemma game. This framework allows agents to select dilemma strategies and interacting neighbours based on their long-term experiences, differing from existing research that relies on preset social norms or external incentives. By modelling each agent using two distinct Q-networks, we disentangle the coevolutionary dynamics between cooperation and interaction. The results indicate that long-term experience enables agents to develop the ability to identify non-cooperative neighbours and exhibit a preference for interaction with cooperative ones. This emergent self-organizing behaviour leads to the clustering of agents with similar strategies, thereby increasing network reciprocity and enhancing group cooperation.
5/7/2024