AutoBencher: Creating Salient, Novel, Difficult Datasets for Language Models

1

Sign in to get full access
Overview
- The paper introduces "AutoBencher," a system for automatically creating challenging datasets for evaluating language models.
- The key goals are to generate datasets that are salient (relevant to real-world needs), novel (not covered by existing benchmarks), and difficult (challenging for current models).
- AutoBencher leverages large language models and human feedback to iteratively refine dataset generation, aiming to push the boundaries of model capabilities.
Plain English Explanation
AutoBencher is a tool that can automatically create new datasets for testing language AI models. The goal is to make these datasets particularly challenging, so that they really push the limits of what current models can do.
The researchers wanted the datasets to be relevant to real-world needs (salient), cover new ground that existing benchmarks don't (novel), and be genuinely difficult for models to perform well on. To achieve this, they used large language models and human feedback in an iterative process to generate and refine the datasets over time.
The idea is that by constantly creating more challenging benchmarks, the research community can drive progress in language AI and uncover new frontiers for model capabilities. This builds on other work in automating dataset updates and understanding benchmark sensitivity.
Technical Explanation
The core of AutoBencher is a dataset generation pipeline that uses large language models to propose novel text samples, which are then filtered and refined based on feedback from human raters. The process iterates, with the model learning to generate increasingly challenging and salient examples over time.
Key steps include:
- Initializing the dataset with a small set of high-quality, manually curated examples
- Using a large language model to propose new candidate examples, conditioned on the existing dataset
- Gathering human ratings on the candidate examples along dimensions like difficulty, novelty, and relevance
- Updating the dataset and fine-tuning the generation model based on the feedback
The researchers experimented with different language models, prompting strategies, and human rating interfaces to optimize the dataset creation process. They also developed techniques to ensure the generated datasets remain diverse and representative, rather than collapsing into narrow or biased subsets.
Critical Analysis
The paper provides a compelling vision for advancing the state of language model benchmarking through automated, iterative dataset curation. By focusing on salient, novel, and difficult examples, AutoBencher has the potential to uncover new frontiers for model development.
That said, the approach does rely heavily on human ratings, which could introduce biases or inconsistencies. There are also open questions around how to best integrate AutoBencher with existing benchmark suites, and how to ensure the generated datasets remain representative of real-world language use over time.
Further research is needed to validate the generalizability of the AutoBencher approach, explore ways to reduce human labor, and investigate the long-term impacts on language model progress. Integrating AutoBencher with efforts like BIG-Bench could be a fruitful direction.
Conclusion
The AutoBencher paper introduces an innovative approach for automatically creating challenging datasets to push the boundaries of language model capabilities. By focusing on salience, novelty, and difficulty, the system aims to uncover new frontiers for model development and drive progress in the field of natural language processing.
While there are some open challenges and areas for further research, the core ideas behind AutoBencher represent an important step forward in benchmark curation and could have significant implications for the long-term advancement of language AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
AutoBencher: Creating Salient, Novel, Difficult Datasets for Language Models
Xiang Lisa Li, Evan Zheran Liu, Percy Liang, Tatsunori Hashimoto
Evaluation is critical for assessing capabilities, tracking scientific progress, and informing model selection. In this paper, we present three desiderata for a good benchmark for language models: (i) salience (e.g., knowledge about World War II is more salient than a random day in history), (ii) novelty (i.e., the benchmark reveals new trends in model rankings not shown by previous benchmarks), and (iii) difficulty (i.e., the benchmark should be difficult for existing models, leaving headroom for future improvement). We operationalize these three desiderata and cast benchmark creation as a search problem, that of finding benchmarks that that satisfy all three desiderata. To tackle this search problem, we present AutoBencher, which uses a language model to automatically search for datasets that meet the three desiderata. AutoBencher uses privileged information (e.g. relevant documents) to construct reliable datasets, and adaptivity with reranking to optimize for the search objective. We use AutoBencher to create datasets for math, multilingual, and knowledge-intensive question answering. The scalability of AutoBencher allows it to test fine-grained categories and tail knowledge, creating datasets that are on average 27% more novel and 22% more difficult than existing benchmarks. A closer investigation of our constructed datasets shows that we can identify specific gaps in LM knowledge in language models that are not captured by existing benchmarks, such as Gemini Pro performing much worse on question answering about the Permian Extinction and Fordism, while OpenAGI-7B performing surprisingly well on QA about COVID-19.
Read more7/12/2024
0
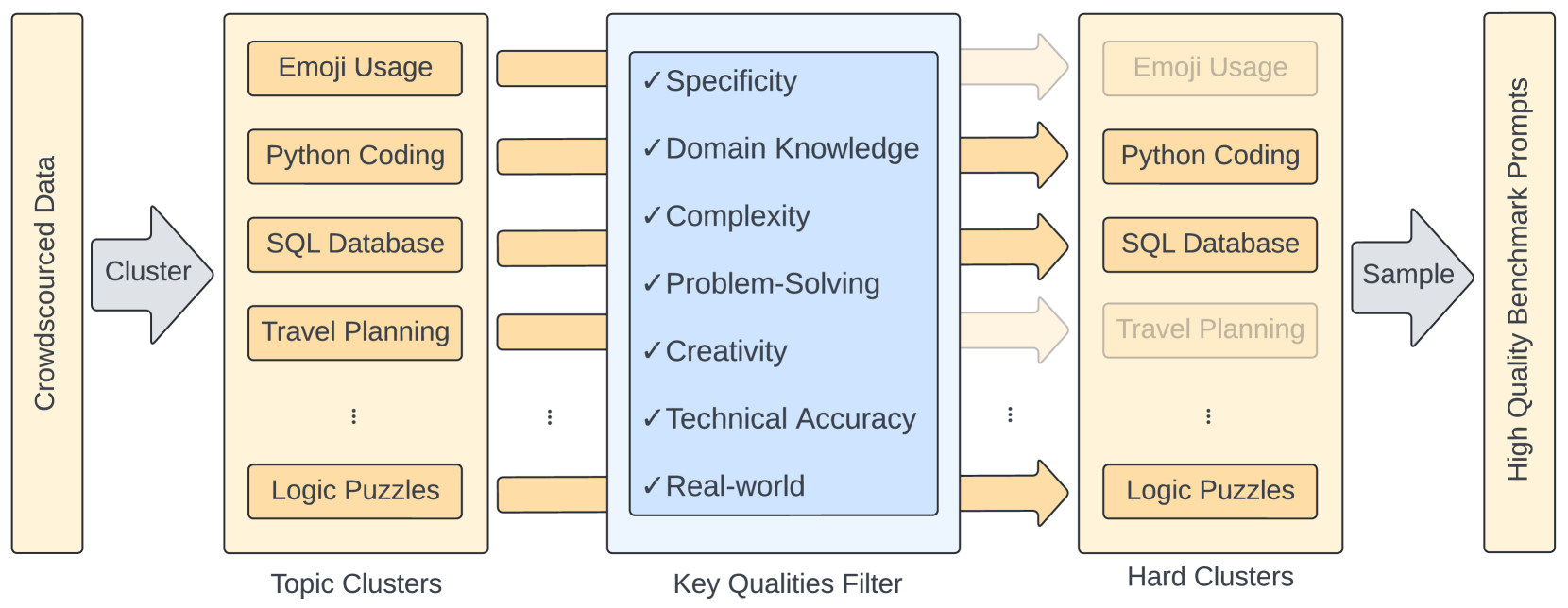
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, Ion Stoica
The rapid evolution of language models has necessitated the development of more challenging benchmarks. Current static benchmarks often struggle to consistently distinguish between the capabilities of different models and fail to align with real-world user preferences. On the other hand, live crowd-sourced platforms like the Chatbot Arena collect a wide range of natural prompts and user feedback. However, these prompts vary in sophistication and the feedback cannot be applied offline to new models. In order to ensure that benchmarks keep up with the pace of LLM development, we address how one can evaluate benchmarks on their ability to confidently separate models and their alignment with human preference. Under these principles, we developed BenchBuilder, a living benchmark that filters high-quality prompts from live data sources to enable offline evaluation on fresh, challenging prompts. BenchBuilder identifies seven indicators of a high-quality prompt, such as the requirement for domain knowledge, and utilizes an LLM annotator to select a high-quality subset of prompts from various topic clusters. The LLM evaluation process employs an LLM judge to ensure a fully automated, high-quality, and constantly updating benchmark. We apply BenchBuilder on prompts from the Chatbot Arena to create Arena-Hard-Auto v0.1: 500 challenging user prompts from a wide range of tasks. Arena-Hard-Auto v0.1 offers 3x tighter confidence intervals than MT-Bench and achieves a state-of-the-art 89.1% agreement with human preference rankings, all at a cost of only $25 and without human labelers. The BenchBuilder pipeline enhances evaluation benchmarks and provides a valuable tool for developers, enabling them to extract high-quality benchmarks from extensive data with minimal effort.
Read more6/19/2024

1
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards
Norah Alzahrani, Hisham Abdullah Alyahya, Yazeed Alnumay, Sultan Alrashed, Shaykhah Alsubaie, Yusef Almushaykeh, Faisal Mirza, Nouf Alotaibi, Nora Altwairesh, Areeb Alowisheq, M Saiful Bari, Haidar Khan
Large Language Model (LLM) leaderboards based on benchmark rankings are regularly used to guide practitioners in model selection. Often, the published leaderboard rankings are taken at face value - we show this is a (potentially costly) mistake. Under existing leaderboards, the relative performance of LLMs is highly sensitive to (often minute) details. We show that for popular multiple-choice question benchmarks (e.g., MMLU), minor perturbations to the benchmark, such as changing the order of choices or the method of answer selection, result in changes in rankings up to 8 positions. We explain this phenomenon by conducting systematic experiments over three broad categories of benchmark perturbations and identifying the sources of this behavior. Our analysis results in several best-practice recommendations, including the advantage of a hybrid scoring method for answer selection. Our study highlights the dangers of relying on simple benchmark evaluations and charts the path for more robust evaluation schemes on the existing benchmarks. The code for this paper is available at https://github.com/National-Center-for-AI-Saudi-Arabia/lm-evaluation-harness.
Read more7/4/2024
💬
0
Automating Dataset Updates Towards Reliable and Timely Evaluation of Large Language Models
Jiahao Ying, Yixin Cao, Yushi Bai, Qianru Sun, Bo Wang, Wei Tang, Zhaojun Ding, Yizhe Yang, Xuanjing Huang, Shuicheng Yan
Large language models (LLMs) have achieved impressive performance across various natural language benchmarks, prompting a continual need to curate more difficult datasets for larger LLMs, which is costly and time-consuming. In this paper, we propose to automate dataset updating and provide systematic analysis regarding its effectiveness in dealing with benchmark leakage issue, difficulty control, and stability. Thus, once the current benchmark has been mastered or leaked, we can update it for timely and reliable evaluation. There are two updating strategies: 1) mimicking strategy to generate similar samples based on original data, preserving stylistic and contextual essence, and 2) extending strategy that further expands existing samples at varying cognitive levels by adapting Bloom's taxonomy of educational objectives. Extensive experiments on updated MMLU and BIG-Bench demonstrate the stability of the proposed strategies and find that the mimicking strategy can effectively alleviate issues of overestimation from benchmark leakage. In cases where the efficient mimicking strategy fails, our extending strategy still shows promising results. Additionally, by controlling the difficulty, we can better discern the models' performance and enable fine-grained analysis neither too difficult nor too easy an exam can fairly judge students' learning status. To the best of our knowledge, we are the first to automate updating benchmarks for reliable and timely evaluation. Our demo leaderboard can be found at https://yingjiahao14.github.io/Automating-DatasetUpdates/.
Read more6/7/2024