Automated and Holistic Co-design of Neural Networks and ASICs for Enabling In-Pixel Intelligence

0

Sign in to get full access
Overview
- This paper presents a novel approach for the automated and holistic co-design of neural networks and application-specific integrated circuits (ASICs) to enable in-pixel intelligence.
- The proposed method aims to jointly optimize the neural network architecture and the ASIC hardware design to achieve high performance and energy efficiency.
- The researchers demonstrate the effectiveness of their approach through experiments and case studies.
Plain English Explanation
The paper describes a new way to design neural networks and special computer chips called ASICs together, in order to create smart "in-pixel" systems. These systems can process data and make decisions right at the point where the data is collected, without needing to send the data elsewhere for processing.
The key idea is to design the neural network and the ASIC hardware in an integrated way, rather than designing them separately. This co-design approach allows the neural network and ASIC to be optimized together for high performance and energy efficiency.
The researchers demonstrate that their automated co-design method can create effective in-pixel systems, which can perform complex tasks like image recognition right at the pixel level without needing to send the data elsewhere.
Technical Explanation
The paper proposes an automated and holistic co-design framework for neural networks and ASICs to enable in-pixel intelligence. The key components of the framework include:
-
Neural network architecture search: The researchers use a multi-objective neural architecture search to explore the design space of neural networks, considering both accuracy and hardware efficiency.
-
ASIC design space exploration: The framework also explores the design space of ASIC hardware, considering factors like chip area, power consumption, and performance.
-
Co-optimization: The neural network architecture and ASIC hardware designs are jointly optimized to find the best combination that meets the target performance and efficiency goals.
The researchers demonstrate the effectiveness of their approach through various case studies, including image classification and object detection tasks. The results show that the co-designed neural network and ASIC can achieve significantly higher performance and energy efficiency compared to existing approaches.
Critical Analysis
The paper presents a compelling approach to the co-design of neural networks and ASICs, which is an important step towards enabling efficient in-pixel intelligence. However, the researchers acknowledge some limitations and areas for further research:
- The co-design framework relies on accurate modeling and simulation of both the neural network and ASIC hardware, which can be challenging to achieve in practice.
- The search space for the co-optimization is still quite large, and the researchers suggest exploring more efficient search algorithms to improve the scalability of the approach.
- The case studies in the paper focus on specific applications, and it would be valuable to see how the co-design framework performs on a wider range of tasks and domains.
Additionally, while the paper demonstrates the potential benefits of the co-design approach, it would be helpful to see a more thorough analysis of the tradeoffs and potential drawbacks, such as the impact on design complexity, time-to-market, or the ability to adapt to changing requirements.
Conclusion
The paper presents a novel approach for the automated and holistic co-design of neural networks and ASICs to enable efficient in-pixel intelligence. By jointly optimizing the neural network architecture and the ASIC hardware design, the researchers are able to achieve significant performance and energy efficiency improvements compared to existing methods.
The proposed framework has the potential to accelerate the development of smart, low-power in-pixel systems that can perform complex tasks like image recognition directly at the point of data collection, without the need for energy-intensive data transfer and remote processing. As the researchers continue to refine and expand their approach, this work could have important implications for a wide range of applications, from smart cameras and sensors to edge computing and Internet of Things devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Automated and Holistic Co-design of Neural Networks and ASICs for Enabling In-Pixel Intelligence
Shubha R. Kharel, Prashansa Mukim, Piotr Maj, Grzegorz W. Deptuch, Shinjae Yoo, Yihui Ren, Soumyajit Mandal
Extreme edge-AI systems, such as those in readout ASICs for radiation detection, must operate under stringent hardware constraints such as micron-level dimensions, sub-milliwatt power, and nanosecond-scale speed while providing clear accuracy advantages over traditional architectures. Finding ideal solutions means identifying optimal AI and ASIC design choices from a design space that has explosively expanded during the merger of these domains, creating non-trivial couplings which together act upon a small set of solutions as constraints tighten. It is impractical, if not impossible, to manually determine ideal choices among possibilities that easily exceed billions even in small-size problems. Existing methods to bridge this gap have leveraged theoretical understanding of hardware to f architecture search. However, the assumptions made in computing such theoretical metrics are too idealized to provide sufficient guidance during the difficult search for a practical implementation. Meanwhile, theoretical estimates for many other crucial metrics (like delay) do not even exist and are similarly variable, dependent on parameters of the process design kit (PDK). To address these challenges, we present a study that employs intelligent search using multi-objective Bayesian optimization, integrating both neural network search and ASIC synthesis in the loop. This approach provides reliable feedback on the collective impact of all cross-domain design choices. We showcase the effectiveness of our approach by finding several Pareto-optimal design choices for effective and efficient neural networks that perform real-time feature extraction from input pulses within the individual pixels of a readout ASIC.
Read more7/23/2024
0
Measurement-driven neural-network training for integrated magnetic tunnel junction arrays
William A. Borders, Advait Madhavan, Matthew W. Daniels, Vasileia Georgiou, Martin Lueker-Boden, Tiffany S. Santos, Patrick M. Braganca, Mark D. Stiles, Jabez J. McClelland, Brian D. Hoskins
The increasing scale of neural networks needed to support more complex applications has led to an increasing requirement for area- and energy-efficient hardware. One route to meeting the budget for these applications is to circumvent the von Neumann bottleneck by performing computation in or near memory. An inevitability of transferring neural networks onto hardware is that non-idealities such as device-to-device variations or poor device yield impact performance. Methods such as hardware-aware training, where substrate non-idealities are incorporated during network training, are one way to recover performance at the cost of solution generality. In this work, we demonstrate inference on hardware neural networks consisting of 20,000 magnetic tunnel junction arrays integrated on a complementary metal-oxide-semiconductor chips that closely resembles market-ready spin transfer-torque magnetoresistive random access memory technology. Using 36 dies, each containing a crossbar array with its own non-idealities, we show that even a small number of defects in physically mapped networks significantly degrades the performance of networks trained without defects and show that, at the cost of generality, hardware-aware training accounting for specific defects on each die can recover to comparable performance with ideal networks. We then demonstrate a robust training method that extends hardware-aware training to statistics-aware training, producing network weights that perform well on most defective dies regardless of their specific defect locations. When evaluated on the 36 physical dies, statistics-aware trained solutions can achieve a mean misclassification error on the MNIST dataset that differs from the software-baseline by only 2 %. This statistics-aware training method could be generalized to networks with many layers that are mapped to hardware suited for industry-ready applications.
Read more5/15/2024
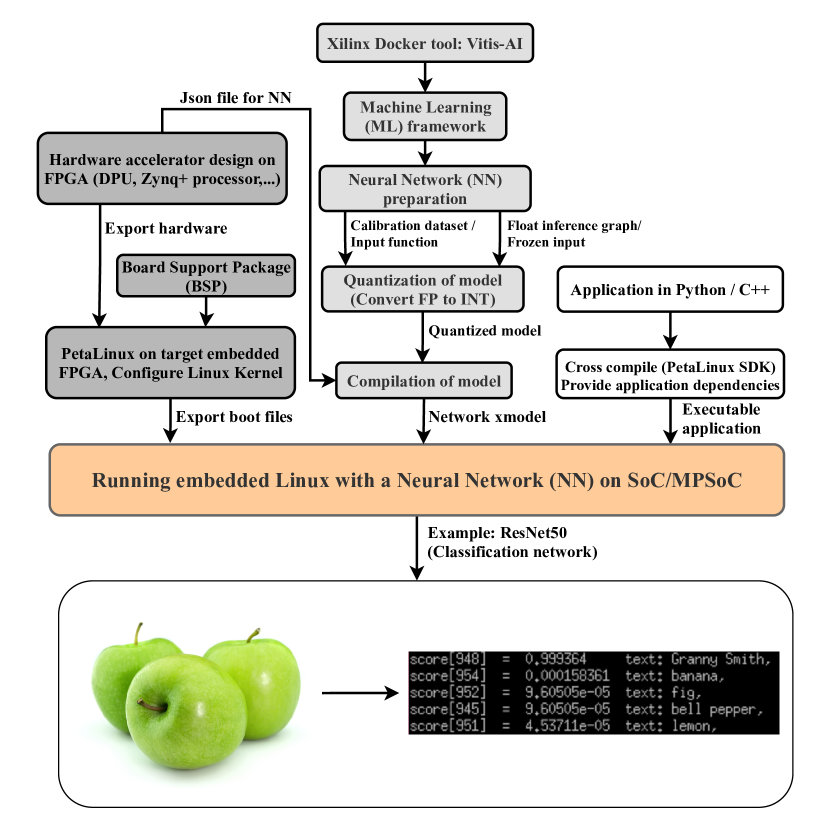
0
Latency optimized Deep Neural Networks (DNNs): An Artificial Intelligence approach at the Edge using Multiprocessor System on Chip (MPSoC)
Seyed Nima Omidsajedi, Rekha Reddy, Jianming Yi, Jan Herbst, Christoph Lipps, Hans Dieter Schotten
Almost in every heavily computation-dependent application, from 6G communication systems to autonomous driving platforms, a large portion of computing should be near to the client side. Edge computing (AI at Edge) in mobile devices is one of the optimized approaches for addressing this requirement. Therefore, in this work, the possibilities and challenges of implementing a low-latency and power-optimized smart mobile system are examined. Utilizing Field Programmable Gate Array (FPGA) based solutions at the edge will lead to bandwidth-optimized designs and as a consequence can boost the computational effectiveness at a system-level deadline. Moreover, various performance aspects and implementation feasibilities of Neural Networks (NNs) on both embedded FPGA edge devices (using Xilinx Multiprocessor System on Chip (MPSoC)) and Cloud are discussed throughout this research. The main goal of this work is to demonstrate a hybrid system that uses the deep learning programmable engine developed by Xilinx Inc. as the main component of the hardware accelerator. Then based on this design, an efficient system for mobile edge computing is represented by utilizing an embedded solution.
Read more7/29/2024

0
Multi-Objective Hardware Aware Neural Architecture Search using Hardware Cost Diversity
Nilotpal Sinha, Peyman Rostami, Abd El Rahman Shabayek, Anis Kacem, Djamila Aouada
Hardware-aware Neural Architecture Search approaches (HW-NAS) automate the design of deep learning architectures, tailored specifically to a given target hardware platform. Yet, these techniques demand substantial computational resources, primarily due to the expensive process of assessing the performance of identified architectures. To alleviate this problem, a recent direction in the literature has employed representation similarity metric for efficiently evaluating architecture performance. Nonetheless, since it is inherently a single objective method, it requires multiple runs to identify the optimal architecture set satisfying the diverse hardware cost constraints, thereby increasing the search cost. Furthermore, simply converting the single objective into a multi-objective approach results in an under-explored architectural search space. In this study, we propose a Multi-Objective method to address the HW-NAS problem, called MO-HDNAS, to identify the trade-off set of architectures in a single run with low computational cost. This is achieved by optimizing three objectives: maximizing the representation similarity metric, minimizing hardware cost, and maximizing the hardware cost diversity. The third objective, i.e. hardware cost diversity, is used to facilitate a better exploration of the architecture search space. Experimental results demonstrate the effectiveness of our proposed method in efficiently addressing the HW-NAS problem across six edge devices for the image classification task.
Read more4/22/2024