Deep Dependency Networks and Advanced Inference Schemes for Multi-Label Classification

0

Sign in to get full access
Overview
- This paper proposes a new approach called "Deep Dependency Networks" for multi-label classification tasks.
- The approach leverages the dependencies between labels to improve overall classification performance.
- It also introduces advanced inference schemes to efficiently predict multiple labels simultaneously.
Plain English Explanation
In many real-world applications, we need to classify an item or example into multiple categories at once. This is known as "multi-label classification." For example, when analyzing an image, we might want to identify not just one object, but several - like a cat, a couch, and a lamp.
The paper proposes a new approach called "Deep Dependency Networks" to tackle this multi-label classification problem. The key insight is that the different labels we're trying to predict often have dependencies between them. For instance, if we've identified a cat in an image, that makes it more likely there will also be a pet bed nearby.
By modeling these label dependencies explicitly, the Deep Dependency Networks approach can leverage that information to make more accurate overall predictions. The paper also introduces some advanced techniques, called "inference schemes," that allow the model to efficiently predict multiple labels at once, rather than having to make separate predictions for each label independently.
Overall, this work offers a more sophisticated and effective way to tackle complex multi-label classification tasks, with potential applications in areas like computer vision, text categorization, and beyond.
Technical Explanation
The paper introduces Deep Dependency Networks (DDNs), a novel neural network architecture for multi-label classification. DDNs model the dependencies between the different labels being predicted, in contrast to traditional approaches that treat each label independently.
The key components of the DDN architecture are:
- Embedding Layer: This maps the input features (e.g. image pixels) to a compact representation.
- Dependency Modeling Layer: This models the dependencies between the labels using a graph neural network.
- Output Layer: This predicts the probability of each label, informed by the learned label dependencies.
To train the DDN model, the authors propose a novel loss function that encourages the model to capture these label dependencies. They also introduce advanced inference schemes, like Gibbs sampling and belief propagation, to efficiently predict multiple labels at test time.
The authors evaluate DDNs on several multi-label classification benchmarks, including image tagging and text categorization tasks. They show that DDNs outperform traditional multi-label classifiers by a significant margin, demonstrating the value of explicitly modeling label dependencies.
Critical Analysis
The paper makes a compelling case for the benefits of Deep Dependency Networks in multi-label classification tasks. The authors provide a thorough theoretical and empirical analysis, highlighting the advantages of their approach over traditional methods.
One potential limitation is the computational complexity of the inference schemes proposed, particularly the Gibbs sampling approach. While the authors demonstrate its effectiveness, the iterative nature of Gibbs sampling may limit its scalability to very large-scale problems. It would be interesting to see how the performance and efficiency of DDNs compare to simpler, more efficient prediction strategies.
Additionally, the paper does not delve deeply into the interpretability of the learned label dependencies within the DDN model. Understanding these dependencies could provide valuable insights into the underlying relationships between the different labels, which could be of interest in many real-world applications.
Overall, the paper presents a well-designed and promising approach for multi-label classification. The authors have made a meaningful contribution to the field, and their work could inspire further research into leveraging label dependencies for more accurate and efficient multi-label prediction.
Conclusion
The Deep Dependency Networks paper introduces a novel architecture and training approach for multi-label classification tasks. By modeling the dependencies between the different labels, the proposed DDN model can leverage this relational information to make more accurate predictions.
The advanced inference schemes presented in the paper further enhance the efficiency of the DDN model, allowing it to simultaneously predict multiple labels. This work represents a significant advancement in the field of multi-label classification, with potential applications in areas such as computer vision, text analysis, and beyond.
While the computational complexity of the inference schemes may be a consideration for very large-scale problems, the overall approach demonstrates the value of explicitly modeling label dependencies in neural networks. This paper paves the way for further research into leveraging relational information to improve the performance and interpretability of multi-label classification systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deep Dependency Networks and Advanced Inference Schemes for Multi-Label Classification
Shivvrat Arya, Yu Xiang, Vibhav Gogate
We present a unified framework called deep dependency networks (DDNs) that combines dependency networks and deep learning architectures for multi-label classification, with a particular emphasis on image and video data. The primary advantage of dependency networks is their ease of training, in contrast to other probabilistic graphical models like Markov networks. In particular, when combined with deep learning architectures, they provide an intuitive, easy-to-use loss function for multi-label classification. A drawback of DDNs compared to Markov networks is their lack of advanced inference schemes, necessitating the use of Gibbs sampling. To address this challenge, we propose novel inference schemes based on local search and integer linear programming for computing the most likely assignment to the labels given observations. We evaluate our novel methods on three video datasets (Charades, TACoS, Wetlab) and three image datasets (MS-COCO, PASCAL VOC, NUS-WIDE), comparing their performance with (a) basic neural architectures and (b) neural architectures combined with Markov networks equipped with advanced inference and learning techniques. Our results demonstrate the superiority of our new DDN methods over the two competing approaches.
Read more4/19/2024

0
Causal inference through multi-stage learning and doubly robust deep neural networks
Yuqian Zhang, Jelena Bradic
Deep neural networks (DNNs) have demonstrated remarkable empirical performance in large-scale supervised learning problems, particularly in scenarios where both the sample size $n$ and the dimension of covariates $p$ are large. This study delves into the application of DNNs across a wide spectrum of intricate causal inference tasks, where direct estimation falls short and necessitates multi-stage learning. Examples include estimating the conditional average treatment effect and dynamic treatment effect. In this framework, DNNs are constructed sequentially, with subsequent stages building upon preceding ones. To mitigate the impact of estimation errors from early stages on subsequent ones, we integrate DNNs in a doubly robust manner. In contrast to previous research, our study offers theoretical assurances regarding the effectiveness of DNNs in settings where the dimensionality $p$ expands with the sample size. These findings are significant independently and extend to degenerate single-stage learning problems.
Read more7/12/2024
🏷️
0
Article Classification with Graph Neural Networks and Multigraphs
Khang Ly, Yury Kashnitsky, Savvas Chamezopoulos, Valeria Krzhizhanovskaya
Classifying research output into context-specific label taxonomies is a challenging and relevant downstream task, given the volume of existing and newly published articles. We propose a method to enhance the performance of article classification by enriching simple Graph Neural Network (GNN) pipelines with multi-graph representations that simultaneously encode multiple signals of article relatedness, e.g. references, co-authorship, shared publication source, shared subject headings, as distinct edge types. Fully supervised transductive node classification experiments are conducted on the Open Graph Benchmark OGBN-arXiv dataset and the PubMed diabetes dataset, augmented with additional metadata from Microsoft Academic Graph and PubMed Central, respectively. The results demonstrate that multi-graphs consistently improve the performance of a variety of GNN models compared to the default graphs. When deployed with SOTA textual node embedding methods, the transformed multi-graphs enable simple and shallow 2-layer GNN pipelines to achieve results on par with more complex architectures.
Read more5/29/2024
0
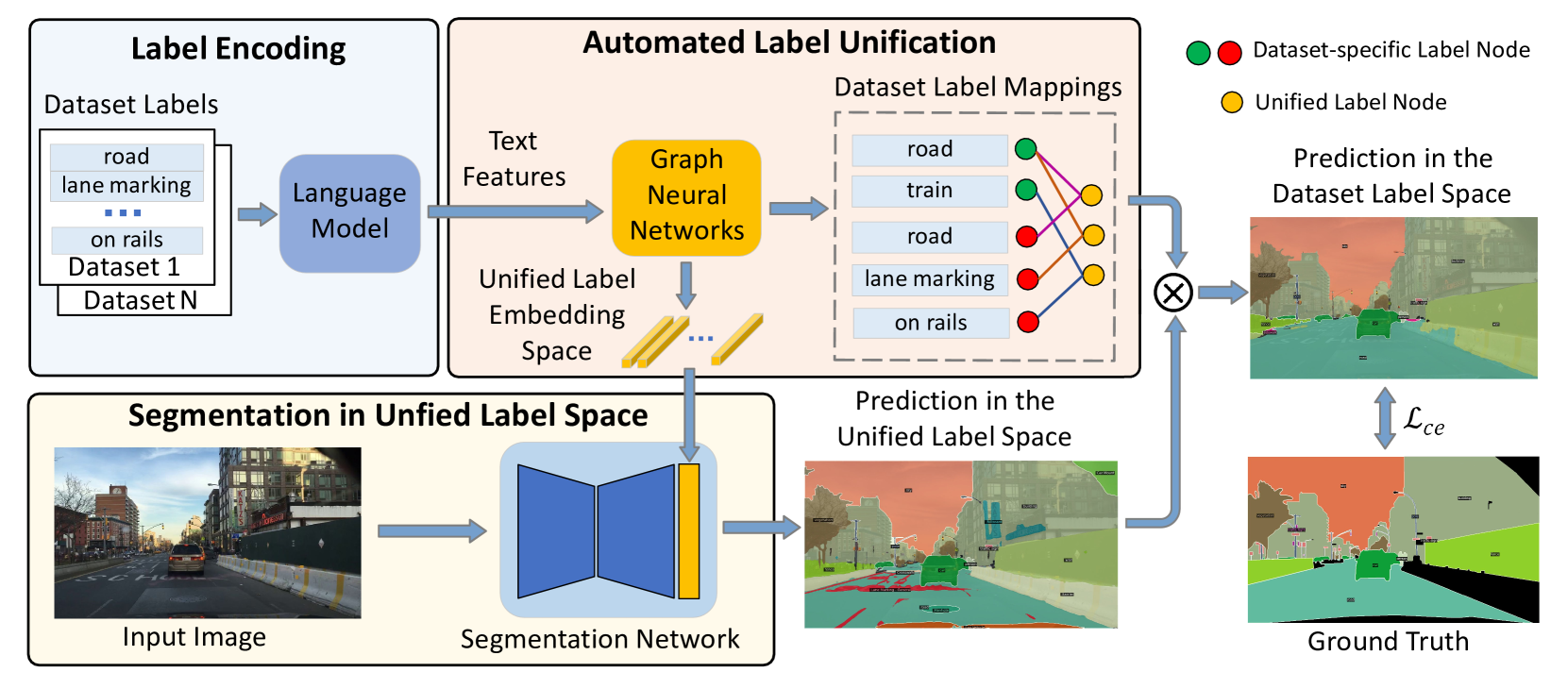
Automated Label Unification for Multi-Dataset Semantic Segmentation with GNNs
Rong Ma, Jie Chen, Xiangyang Xue, Jian Pu
Deep supervised models possess significant capability to assimilate extensive training data, thereby presenting an opportunity to enhance model performance through training on multiple datasets. However, conflicts arising from different label spaces among datasets may adversely affect model performance. In this paper, we propose a novel approach to automatically construct a unified label space across multiple datasets using graph neural networks. This enables semantic segmentation models to be trained simultaneously on multiple datasets, resulting in performance improvements. Unlike existing methods, our approach facilitates seamless training without the need for additional manual reannotation or taxonomy reconciliation. This significantly enhances the efficiency and effectiveness of multi-dataset segmentation model training. The results demonstrate that our method significantly outperforms other multi-dataset training methods when trained on seven datasets simultaneously, and achieves state-of-the-art performance on the WildDash 2 benchmark.
Read more8/29/2024