Automatic Odometry-Less OpenDRIVE Generation From Sparse Point Clouds
2405.07544
0
0
🛸
Abstract
High-resolution road representations are a key factor for the success of (highly) automated driving functions. These representations, for example, high-definition (HD) maps, contain accurate information on a multitude of factors, among others: road geometry, lane information, and traffic signs. Through the growing complexity and functionality of automated driving functions, also the requirements on testing and evaluation grow continuously. This leads to an increasing interest in virtual test drives for evaluation purposes. As roads play a crucial role in traffic flow, accurate real-world representations are needed, especially when deriving realistic driving behavior data. This paper proposes a novel approach to generate realistic road representations based solely on point cloud information, independent of the LiDAR sensor, mounting position, and without the need for odometry data, multi-sensor fusion, machine learning, or highly-accurate calibration. As the primary use case is simulation, we use the OpenDRIVE format for evaluation.
Create account to get full access
Overview
- High-resolution road representations are crucial for the success of automated driving functions
- These representations, such as high-definition (HD) maps, contain accurate information on factors like road geometry, lane information, and traffic signs
- The growing complexity of automated driving functions has increased the need for virtual test drives to evaluate them
- Accurate real-world road representations are required to derive realistic driving behavior data for these simulations
Plain English Explanation
High-resolution maps and digital models of roads are essential for the success of self-driving cars and other highly automated driving technologies. These detailed representations, called "high-definition (HD) maps," provide accurate information about the physical characteristics of roads, including their shape, the layout of lanes, and the locations of traffic signs and signals. As automated driving functions become more advanced, the need for thorough testing and evaluation has grown. This has led to increased interest in using virtual simulations, where cars can be tested in digital replicas of the real world.
To make these virtual test drives as realistic as possible, the digital road models need to accurately reflect the actual roads. This is particularly important for understanding how cars will behave in traffic. The paper proposes a new way to generate these realistic road representations using only information from laser-based "LiDAR" sensors, without needing additional data sources like GPS or complex calibration. The goal is to make it easier to create the detailed digital road maps required for effective simulation of automated driving.
Technical Explanation
The paper presents a novel approach to generating realistic road representations solely from LiDAR point cloud data, without relying on sensor metadata, odometry, or machine learning. This is particularly useful for creating digital road models for simulation purposes, where the authors use the OpenDRIVE format for evaluation.
The key aspects of the proposed method are:
- Independence from sensor setup: The approach works regardless of the specific LiDAR sensor used or its mounting position on the vehicle.
- No need for odometry or sensor fusion: The road representation is generated directly from the point cloud data, without requiring additional information sources like GPS or other sensors.
- Lack of heavy preprocessing: The method avoids complex preprocessing steps like detailed 3D object detection or machine learning-based point cloud segmentation.
The authors demonstrate the effectiveness of their approach through experiments and comparisons to ground truth data, showing that it can generate accurate road representations suitable for simulation purposes.
Critical Analysis
The paper presents a promising approach for generating realistic road representations from LiDAR data alone, which can be valuable for automating the creation of virtual environments for testing and evaluating autonomous driving systems. However, the authors acknowledge that the method has certain limitations:
- The approach may struggle with accurately capturing complex road geometries, such as intersections or curved roads, which could impact the realism of the simulated environments.
- The reliance on LiDAR data alone means that the method may not be able to capture some important road features, such as traffic signs or lane markings, that could be better detected using other sensor modalities or more advanced perception techniques.
- The authors do not provide a comprehensive evaluation of the performance and accuracy of their method across a diverse range of real-world road environments, which would be necessary to fully assess its capabilities and limitations.
Further research and development may be needed to address these potential issues and enhance the robustness and versatility of the proposed approach.
Conclusion
This paper presents a novel method for generating realistic road representations based solely on LiDAR point cloud data, without requiring additional sensors, odometry, or complex preprocessing. This approach can be particularly useful for creating detailed digital models of roads for use in simulation environments for testing and evaluating autonomous driving systems. While the method shows promise, the authors acknowledge certain limitations, and further research may be needed to address these and expand the capabilities of this type of road modeling technique.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
Zhongyu Yang, Mai Liu, Jinluo Xie, Yueming Zhang, Chen Shen, Wei Shao, Jichao Jiao, Tengfei Xing, Runbo Hu, Pengfei Xu
0
0
Autonomous driving without high-definition (HD) maps demands a higher level of active scene understanding. In this competition, the organizers provided the multi-perspective camera images and standard-definition (SD) maps to explore the boundaries of scene reasoning capabilities. We found that most existing algorithms construct Bird's Eye View (BEV) features from these multi-perspective images and use multi-task heads to delineate road centerlines, boundary lines, pedestrian crossings, and other areas. However, these algorithms perform poorly at the far end of roads and struggle when the primary subject in the image is occluded. Therefore, in this competition, we not only used multi-perspective images as input but also incorporated SD maps to address this issue. We employed map encoder pre-training to enhance the network's geometric encoding capabilities and utilized YOLOX to improve traffic element detection precision. Additionally, for area detection, we innovatively introduced LDTR and auxiliary tasks to achieve higher precision. As a result, our final OLUS score is 0.58.
6/17/2024
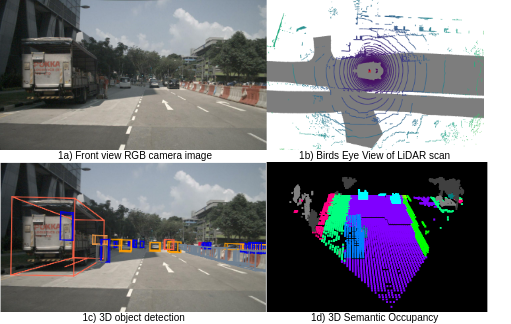
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Samuel Sze, Lars Kunze
0
0
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
5/21/2024
🌐
Brightearth roads: Towards fully automatic road network extraction from satellite imagery
Liuyun Duan (LCT), Willard Mapurisa (LCT), Maxime Leras (LCT), Leigh Lotter (LCT), Yuliya Tarabalka (LCT)
0
0
The modern road network topology comprises intricately designed structures that introduce complexity when automatically reconstructing road networks. While open resources like OpenStreetMap (OSM) offer road networks with well-defined topology, they may not always be up to date worldwide. In this paper, we propose a fully automated pipeline for extracting road networks from very-high-resolution (VHR) satellite imagery. Our approach directly generates road line-strings that are seamlessly connected and precisely positioned. The process involves three key modules: a CNN-based neural network for road segmentation, a graph optimization algorithm to convert road predictions into vector line-strings, and a machine learning model for classifying road materials. Compared to OSM data, our results demonstrate significant potential for providing the latest road layouts and precise positions of road segments.
6/24/2024

Rendering-Enhanced Automatic Image-to-Point Cloud Registration for Roadside Scenes
Yu Sheng, Lu Zhang, Xingchen Li, Yifan Duan, Yanyong Zhang, Yu Zhang, Jianmin Ji
0
0
Prior point cloud provides 3D environmental context, which enhances the capabilities of monocular camera in downstream vision tasks, such as 3D object detection, via data fusion. However, the absence of accurate and automated registration methods for estimating camera extrinsic parameters in roadside scene point clouds notably constrains the potential applications of roadside cameras. This paper proposes a novel approach for the automatic registration between prior point clouds and images from roadside scenes. The main idea involves rendering photorealistic grayscale views taken at specific perspectives from the prior point cloud with the help of their features like RGB or intensity values. These generated views can reduce the modality differences between images and prior point clouds, thereby improve the robustness and accuracy of the registration results. Particularly, we specify an efficient algorithm, named neighbor rendering, for the rendering process. Then we introduce a method for automatically estimating the initial guess using only rough guesses of camera's position. At last, we propose a procedure for iteratively refining the extrinsic parameters by minimizing the reprojection error for line features extracted from both generated and camera images using Segment Anything Model (SAM). We assess our method using a self-collected dataset, comprising eight cameras strategically positioned throughout the university campus. Experiments demonstrate our method's capability to automatically align prior point cloud with roadside camera image, achieving a rotation accuracy of 0.202 degrees and a translation precision of 0.079m. Furthermore, we validate our approach's effectiveness in visual applications by substantially improving monocular 3D object detection performance.
4/9/2024