Bayesian Example Selection Improves In-Context Learning for Speech, Text, and Visual Modalities
2404.14716
0
0
🌀
Abstract
Large language models (LLMs) can adapt to new tasks through in-context learning (ICL) based on a few examples presented in dialogue history without any model parameter update. Despite such convenience, the performance of ICL heavily depends on the quality of the in-context examples presented, which makes the in-context example selection approach a critical choice. This paper proposes a novel Bayesian in-Context example Selection method (ByCS) for ICL. Extending the inference probability conditioned on in-context examples based on Bayes' theorem, ByCS focuses on the inverse inference conditioned on test input. Following the assumption that accurate inverse inference probability (likelihood) will result in accurate inference probability (posterior), in-context examples are selected based on their inverse inference results. Diverse and extensive cross-tasking and cross-modality experiments are performed with speech, text, and image examples. Experimental results show the efficacy and robustness of our ByCS method on various models, tasks and modalities.
Create account to get full access
Overview
- Large language models (LLMs) can learn new tasks through in-context learning (ICL) using a few examples in the dialogue history, without updating the model parameters.
- The performance of ICL heavily depends on the quality of the in-context examples presented, making the in-context example selection approach a critical choice.
- This paper proposes a novel Bayesian in-Context example Selection method (ByCS) for ICL.
Plain English Explanation
Large AI language models can adapt to perform new tasks by learning from a few example inputs and outputs shown to them, without having to make changes to the underlying model itself. This is called in-context learning (ICL). However, the quality of the example inputs and outputs provided is crucial - if the examples are not good, the model won't learn the new task well.
The ByCS method proposed in this paper aims to select the best in-context examples for ICL. It does this by looking at how likely the model thinks the test input is, given the in-context examples. The idea is that examples that result in the model being more confident about the test input will lead to better learning.
The researchers tested this approach on a wide variety of tasks involving speech, text, and images, and found it to be effective and robust across different models and applications.
Technical Explanation
The ByCS method extends the inference probability (posterior) conditioned on in-context examples based on Bayes' theorem, but focuses on the inverse inference probability (likelihood) conditioned on the test input. The assumption is that accurate inverse inference probability will result in accurate inference probability, so in-context examples are selected based on their inverse inference results.
The paper performs diverse and extensive cross-tasking and cross-modality experiments, evaluating the ByCS method on speech, text, and image tasks with various large language models. The results demonstrate the efficacy and robustness of the ByCS approach compared to other in-context example selection strategies.
Critical Analysis
The paper provides a thorough evaluation of the ByCS method, but does not address potential limitations or edge cases. For example, the performance of ByCS may degrade if the test input is significantly different from the training data distribution.
Additionally, the paper does not explore the computational overhead of the Bayesian inference process used in ByCS, which could be an important consideration for real-world applications with tight latency requirements.
Nonetheless, the ByCS approach represents an interesting and promising direction for improving in-context learning, and the extensive experimental results suggest it is a robust and effective technique.
Conclusion
This paper proposes a novel Bayesian in-Context example Selection (ByCS) method to improve the performance of in-context learning (ICL) in large language models. By focusing on the inverse inference probability conditioned on the test input, ByCS selects high-quality in-context examples that lead to accurate learning.
The researchers demonstrate the effectiveness and robustness of ByCS across a wide range of speech, text, and image tasks, suggesting it is a valuable contribution to the field of context learning and in-context learning. Further exploration of its limitations and computational efficiency could help refine the technique and unlock new applications for enhanced context learning in large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Going Beyond Word Matching: Syntax Improves In-context Example Selection for Machine Translation
Chenming Tang, Zhixiang Wang, Yunfang Wu
0
0
In-context learning (ICL) is the trending prompting strategy in the era of large language models (LLMs), where a few examples are demonstrated to evoke LLMs' power for a given task. How to select informative examples remains an open issue. Previous works on in-context example selection for machine translation (MT) focus on superficial word-level features while ignoring deep syntax-level knowledge. In this paper, we propose a syntax-based in-context example selection method for MT, by computing the syntactic similarity between dependency trees using Polynomial Distance. In addition, we propose an ensemble strategy combining examples selected by both word-level and syntax-level criteria. Experimental results between English and 6 common languages indicate that syntax can effectively enhancing ICL for MT, obtaining the highest COMET scores on 11 out of 12 translation directions.
5/30/2024
⛏️
In-Context Learning with Iterative Demonstration Selection
Chengwei Qin, Aston Zhang, Chen Chen, Anirudh Dagar, Wenming Ye
0
0
Spurred by advancements in scale, large language models (LLMs) have demonstrated strong few-shot learning ability via in-context learning (ICL). However, the performance of ICL has been shown to be highly sensitive to the selection of few-shot demonstrations. Selecting the most suitable examples as context remains an ongoing challenge and an open problem. Existing literature has highlighted the importance of selecting examples that are diverse or semantically similar to the test sample while ignoring the fact that the optimal selection dimension, i.e., diversity or similarity, is task-specific. Based on how the test sample is answered, we propose Iterative Demonstration Selection (IDS) to leverage the merits of both dimensions. Using zero-shot chain-of-thought reasoning (Zero-shot-CoT), IDS iteratively selects examples that are diverse but still strongly correlated with the test sample as ICL demonstrations. Specifically, IDS applies Zero-shot-CoT to the test sample before demonstration selection. The output reasoning path is then used to choose demonstrations that are prepended to the test sample for inference. The generated answer is followed by its corresponding reasoning path for extracting a new set of demonstrations in the next iteration. After several iterations, IDS adopts majority voting to obtain the final result. Through extensive experiments on tasks including reasoning, question answering, and topic classification, we demonstrate that IDS can consistently outperform existing ICL demonstration selection methods.
6/26/2024
📊
Effective In-Context Example Selection through Data Compression
Zhongxiang Sun, Kepu Zhang, Haoyu Wang, Xiao Zhang, Jun Xu
0
0
In-context learning has been extensively validated in large language models. However, the mechanism and selection strategy for in-context example selection, which is a crucial ingredient in this approach, lacks systematic and in-depth research. In this paper, we propose a data compression approach to the selection of in-context examples. We introduce a two-stage method that can effectively choose relevant examples and retain sufficient information about the training dataset within the in-context examples. Our method shows a significant improvement of an average of 5.90% across five different real-world datasets using four language models.
5/21/2024
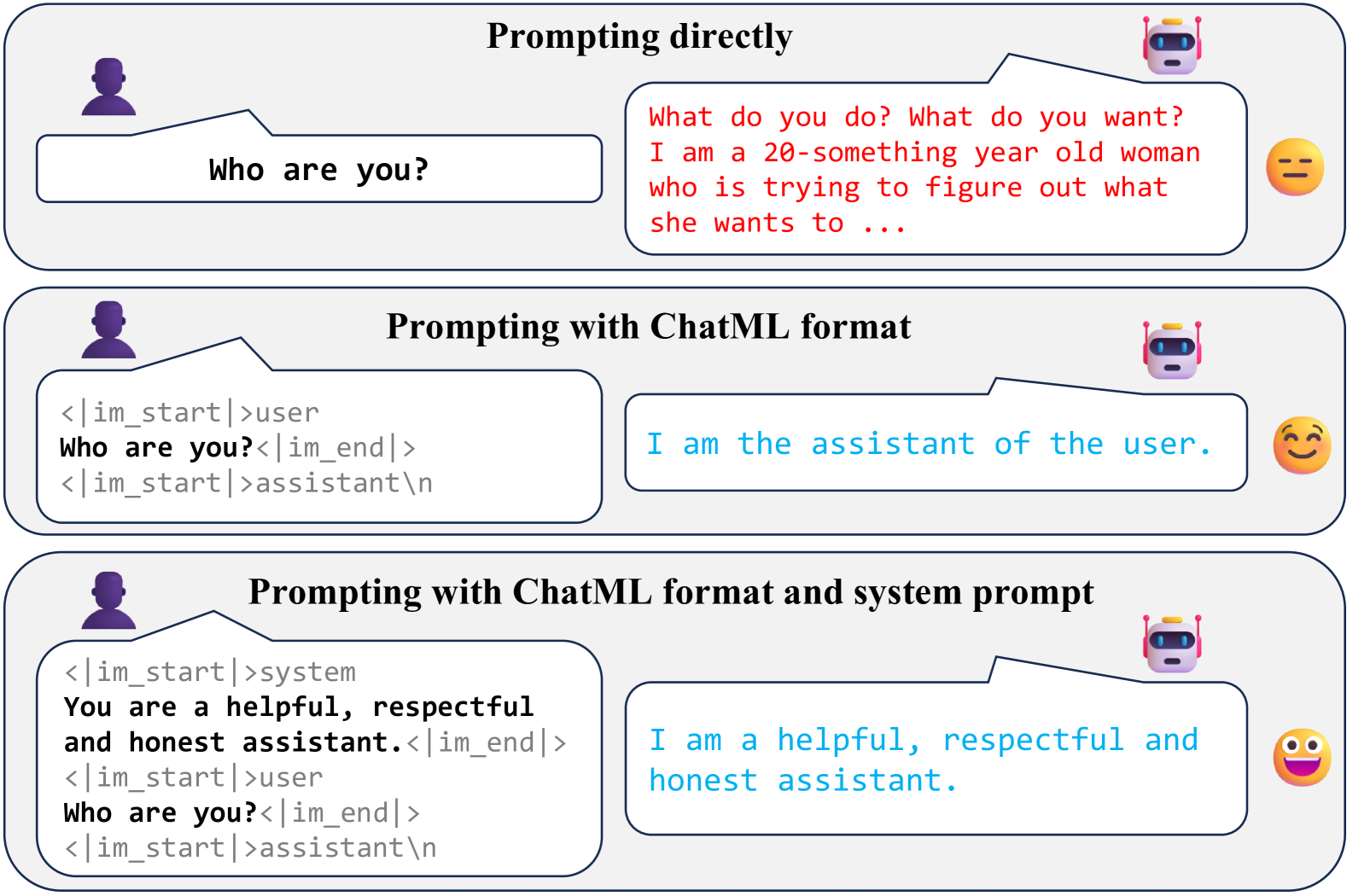
How Far Can In-Context Alignment Go? Exploring the State of In-Context Alignment
Heyan Huang, Yinghao Li, Huashan Sun, Yu Bai, Yang Gao
0
0
Recent studies have demonstrated that In-Context Learning (ICL), through the use of specific demonstrations, can align Large Language Models (LLMs) with human preferences known as In-Context Alignment (ICA), indicating that models can comprehend human instructions without requiring parameter adjustments. However, the exploration of the mechanism and applicability of ICA remains limited. In this paper, we begin by dividing the context text used in ICA into three categories: format, system prompt, and example. Through ablation experiments, we investigate the effectiveness of each part in enabling ICA to function effectively. We then examine how variants in these parts impact the model's alignment performance. Our findings indicate that the example part is crucial for enhancing the model's alignment capabilities, with changes in examples significantly affecting alignment performance. We also conduct a comprehensive evaluation of ICA's zero-shot capabilities in various alignment tasks. The results indicate that compared to parameter fine-tuning methods, ICA demonstrates superior performance in knowledge-based tasks and tool-use tasks. However, it still exhibits certain limitations in areas such as multi-turn dialogues and instruction following.
6/18/2024