Behavioral Testing: Can Large Language Models Implicitly Resolve Ambiguous Entities?

0

Sign in to get full access
Overview
- This paper investigates whether large language models (LLMs) can implicitly resolve ambiguous entities in behavioral testing.
- The researchers designed experiments to assess an LLM's ability to handle ambiguity and understand context.
- The findings provide insights into the cognitive capabilities of LLMs and their potential limitations.
Plain English Explanation
The paper explores whether large language models can intuitively make sense of ambiguous references in language, without being explicitly programmed to do so. Ambiguity is a common challenge in human communication, where a word or phrase could have multiple possible meanings depending on the context.
The researchers designed a series of experiments to test an LLM's ability to navigate ambiguous scenarios. For example, they might present the model with a sentence like "I saw the man with the telescope" and assess whether the model can correctly infer whether the man was holding the telescope or if the telescope was used to observe the man.
By observing how the LLM responds in these types of ambiguous situations, the researchers gained insights into the model's underlying cognitive capabilities and limitations. This helps us better understand the extent to which LLMs exhibit cognitive dissonance and the areas where they may need to be explicitly trained to handle ambiguity.
Technical Explanation
The paper describes a series of experiments designed to test whether large language models (LLMs) can implicitly resolve ambiguous entities. The researchers created a dataset of ambiguous sentences, where the correct interpretation depended on the context.
For example, in the sentence "I saw the man with the telescope," the telescope could either be referring to the man holding the telescope, or the telescope being used to observe the man. The researchers then presented these ambiguous sentences to an LLM and assessed the model's ability to correctly interpret the intended meaning.
The experiments involved multiple variations of the ambiguous sentences, with adjustments to the context to see how the LLM's interpretation would change. The researchers also tested the model's performance on explicitly handling ambiguity by providing additional cues or clarifying information.
By analyzing the LLM's responses, the researchers were able to gain insights into the model's cognitive capabilities and its ability to implicitly resolve ambiguous entities. The findings suggest that LLMs may have some inherent capacity to handle ambiguity, but there are also limitations that require further exploration.
Critical Analysis
The researchers acknowledge several caveats and limitations in their study. One key limitation is the use of a relatively small dataset of ambiguous sentences, which may not fully capture the breadth of ambiguity that can arise in natural language.
Additionally, the experiments were conducted on a single LLM, and it's unclear whether the findings would generalize to other models or architectures. The researchers suggest that further research is needed to understand how different LLMs handle ambiguity and whether there are systematic patterns or limitations.
Another potential issue is the reliance on the LLM's textual outputs as the primary measure of its understanding. While this provides valuable insights, it may not fully capture the model's internal reasoning or decision-making processes.
Despite these limitations, the study offers an important starting point for exploring the cognitive capabilities of LLMs and their ability to navigate ambiguous scenarios. The findings highlight the need for continued research and development in this area, as the ability to handle ambiguity is a critical aspect of human-like language understanding.
Conclusion
This paper presents a novel approach to investigating the implicit ambiguity-handling capabilities of large language models. The experimental results provide valuable insights into the cognitive capabilities and limitations of these models, suggesting that they have some inherent ability to navigate ambiguous scenarios but also face significant challenges.
The findings have important implications for the development of more robust and human-like language understanding systems. By better understanding the strengths and weaknesses of LLMs in handling ambiguity, researchers and developers can work towards aligning these models to more effectively resolve ambiguous references and communicate in a more natural, context-sensitive manner.
Overall, this paper contributes to the growing body of research exploring the cognitive capabilities of large language models and paves the way for further advancements in the field of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Behavioral Testing: Can Large Language Models Implicitly Resolve Ambiguous Entities?
Anastasiia Sedova, Robert Litschko, Diego Frassinelli, Benjamin Roth, Barbara Plank
One of the major aspects contributing to the striking performance of large language models (LLMs) is the vast amount of factual knowledge accumulated during pre-training. Yet, many LLMs suffer from self-inconsistency, which raises doubts about their trustworthiness and reliability. In this paper, we focus on entity type ambiguity and analyze current state-of-the-art LLMs for their proficiency and consistency in applying their factual knowledge when prompted for entities under ambiguity. To do so, we propose an evaluation protocol that disentangles knowing from applying knowledge, and test state-of-the-art LLMs on 49 entities. Our experiments reveal that LLMs perform poorly with ambiguous prompts, achieving only 80% accuracy. Our results further demonstrate systematic discrepancies in LLM behavior and their failure to consistently apply information, indicating that the models can exhibit knowledge without being able to utilize it, significant biases for preferred readings, as well as self inconsistencies. Our study highlights the importance of handling entity ambiguity in future for more trustworthy LLMs
Read more7/26/2024

0
Aligning Language Models to Explicitly Handle Ambiguity
Hyuhng Joon Kim, Youna Kim, Cheonbok Park, Junyeob Kim, Choonghyun Park, Kang Min Yoo, Sang-goo Lee, Taeuk Kim
In interactions between users and language model agents, user utterances frequently exhibit ellipsis (omission of words or phrases) or imprecision (lack of exactness) to prioritize efficiency. This can lead to varying interpretations of the same input based on different assumptions or background knowledge. It is thus crucial for agents to adeptly handle the inherent ambiguity in queries to ensure reliability. However, even state-of-the-art large language models (LLMs) still face challenges in such scenarios, primarily due to the following hurdles: (1) LLMs are not explicitly trained to deal with ambiguous utterances; (2) the degree of ambiguity perceived by the LLMs may vary depending on the possessed knowledge. To address these issues, we propose Alignment with Perceived Ambiguity (APA), a novel pipeline that aligns LLMs to manage ambiguous queries by leveraging their own assessment of ambiguity (i.e., perceived ambiguity). Experimental results on question-answering datasets demonstrate that APA empowers LLMs to explicitly detect and manage ambiguous queries while retaining the ability to answer clear questions. Furthermore, our finding proves that APA excels beyond training with gold-standard labels, especially in out-of-distribution scenarios.
Read more6/18/2024
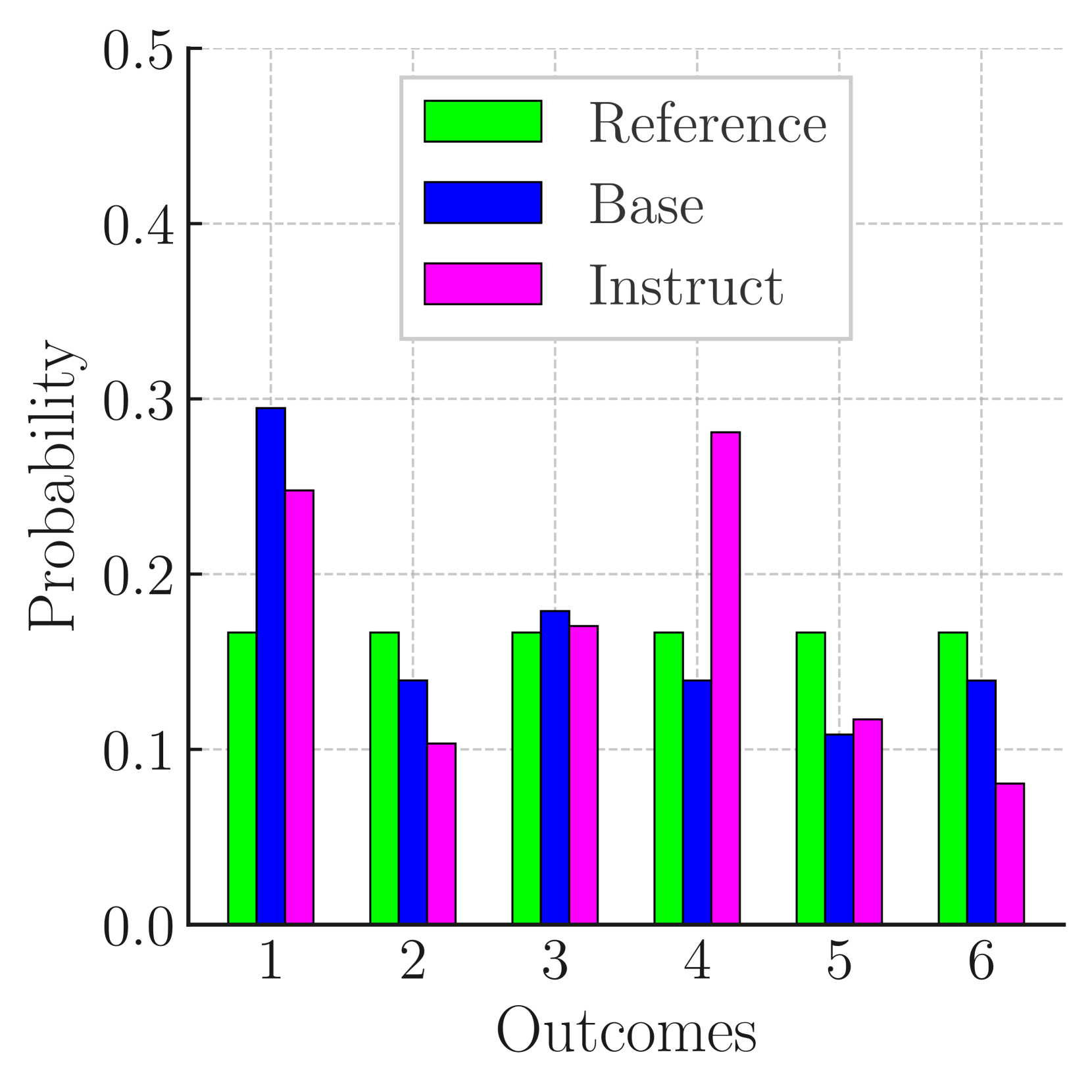
0
Do Large Language Models Exhibit Cognitive Dissonance? Studying the Difference Between Revealed Beliefs and Stated Answers
Manuel Mondal, Ljiljana Dolamic, G'er^ome Bovet, Philippe Cudr'e-Mauroux
Prompting and Multiple Choices Questions (MCQ) have become the preferred approach to assess the capabilities of Large Language Models (LLMs), due to their ease of manipulation and evaluation. Such experimental appraisals have pointed toward the LLMs' apparent ability to perform causal reasoning or to grasp uncertainty. In this paper, we investigate whether these abilities are measurable outside of tailored prompting and MCQ by reformulating these issues as direct text completion - the foundation of LLMs. To achieve this goal, we define scenarios with multiple possible outcomes and we compare the prediction made by the LLM through prompting (their Stated Answer) to the probability distributions they compute over these outcomes during next token prediction (their Revealed Belief). Our findings suggest that the Revealed Belief of LLMs significantly differs from their Stated Answer and hint at multiple biases and misrepresentations that their beliefs may yield in many scenarios and outcomes. As text completion is at the core of LLMs, these results suggest that common evaluation methods may only provide a partial picture and that more research is needed to assess the extent and nature of their capabilities.
Read more6/24/2024

0
Large Language Models Must Be Taught to Know What They Don't Know
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, Andrew Gordon Wilson
When using large language models (LLMs) in high-stakes applications, we need to know when we can trust their predictions. Some works argue that prompting high-performance LLMs is sufficient to produce calibrated uncertainties, while others introduce sampling methods that can be prohibitively expensive. In this work, we first argue that prompting on its own is insufficient to achieve good calibration and then show that fine-tuning on a small dataset of correct and incorrect answers can create an uncertainty estimate with good generalization and small computational overhead. We show that a thousand graded examples are sufficient to outperform baseline methods and that training through the features of a model is necessary for good performance and tractable for large open-source models when using LoRA. We also investigate the mechanisms that enable reliable LLM uncertainty estimation, finding that many models can be used as general-purpose uncertainty estimators, applicable not just to their own uncertainties but also the uncertainty of other models. Lastly, we show that uncertainty estimates inform human use of LLMs in human-AI collaborative settings through a user study.
Read more6/13/2024