Benchmarking for Deep Uplift Modeling in Online Marketing

0
Sign in to get full access
Overview
- This paper presents a benchmarking framework for evaluating deep uplift modeling in online marketing.
- Uplift modeling is a machine learning technique that aims to identify individuals who are most likely to respond positively to a marketing intervention.
- The researchers propose a set of open-source benchmarking tasks and datasets to enable reproducible research and fair comparisons of deep uplift modeling approaches.
Plain English Explanation
Online marketing often involves targeting specific individuals with personalized offers or promotions in the hope of getting them to take a desired action, such as making a purchase. Uplift modeling is a technique that helps marketers identify the people who are most likely to respond positively to these interventions.
The key idea behind uplift modeling is to predict not just whether someone will take the desired action, but whether they are more likely to do so because of the marketing intervention. This is different from traditional predictive modeling, which simply tries to forecast the outcome without considering the impact of the intervention.
Deep learning, a powerful machine learning approach, has shown promise for improving the accuracy of uplift modeling. However, there has been a lack of standardized benchmarks and datasets to compare different deep uplift modeling techniques. This paper aims to address that gap by proposing a set of open-source benchmarking tasks and datasets that researchers can use to evaluate and compare their deep uplift modeling approaches in a fair and reproducible way.
By having a common set of benchmarks, the researchers hope to accelerate progress in this area and help marketers make more informed decisions about which deep uplift modeling techniques to use in their online campaigns.
Technical Explanation
The paper first provides an overview of deep uplift modeling, explaining how it differs from traditional predictive modeling and the potential benefits of using deep learning for this task. The researchers then describe the key components of their proposed benchmarking framework:
-
Benchmark Tasks: The framework includes several benchmarking tasks that capture different aspects of online marketing, such as predicting user response to email campaigns, website promotions, and product recommendations.
-
Benchmark Datasets: The researchers have curated several open-source datasets that can be used to evaluate deep uplift modeling approaches on the benchmark tasks. These datasets cover a range of industries and marketing scenarios.
-
Evaluation Metrics: To assess the performance of deep uplift modeling techniques, the framework defines a set of evaluation metrics, such as qini coefficient and EMR, which are specifically designed to capture the true impact of the marketing interventions.
The researchers also discuss the challenges of benchmarking deep uplift modeling, such as the need for careful experimental design to account for potential confounding factors and the importance of considering fairness and uncertainty in the model outputs.
Critical Analysis
The proposed benchmarking framework is a valuable contribution to the field of deep uplift modeling, as it addresses the lack of standardized evaluation methods and datasets that has hindered progress in this area. By providing a common set of benchmarks, the researchers aim to enable more reproducible research and fair comparisons of different deep uplift modeling approaches.
However, the framework does have some limitations. The curated datasets may not capture the full complexity and diversity of real-world online marketing scenarios, and the evaluation metrics, while tailored for uplift modeling, may not fully capture all the nuances of a marketer's decision-making process. Additionally, the framework does not address the potential ethical and societal implications of deep uplift modeling, such as the risk of perpetuating biases or exploiting vulnerable populations.
Conclusion
This paper presents a valuable benchmarking framework for evaluating deep uplift modeling in online marketing. By providing a standardized set of tasks, datasets, and evaluation metrics, the researchers aim to facilitate more reproducible and meaningful comparisons of different deep uplift modeling techniques. While the framework has some limitations, it represents an important step towards advancing the state of the art in this field and helping marketers make more informed decisions about the use of deep learning in their campaigns.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking for Deep Uplift Modeling in Online Marketing
Dugang Liu, Xing Tang, Yang Qiao, Miao Liu, Zexu Sun, Xiuqiang He, Zhong Ming
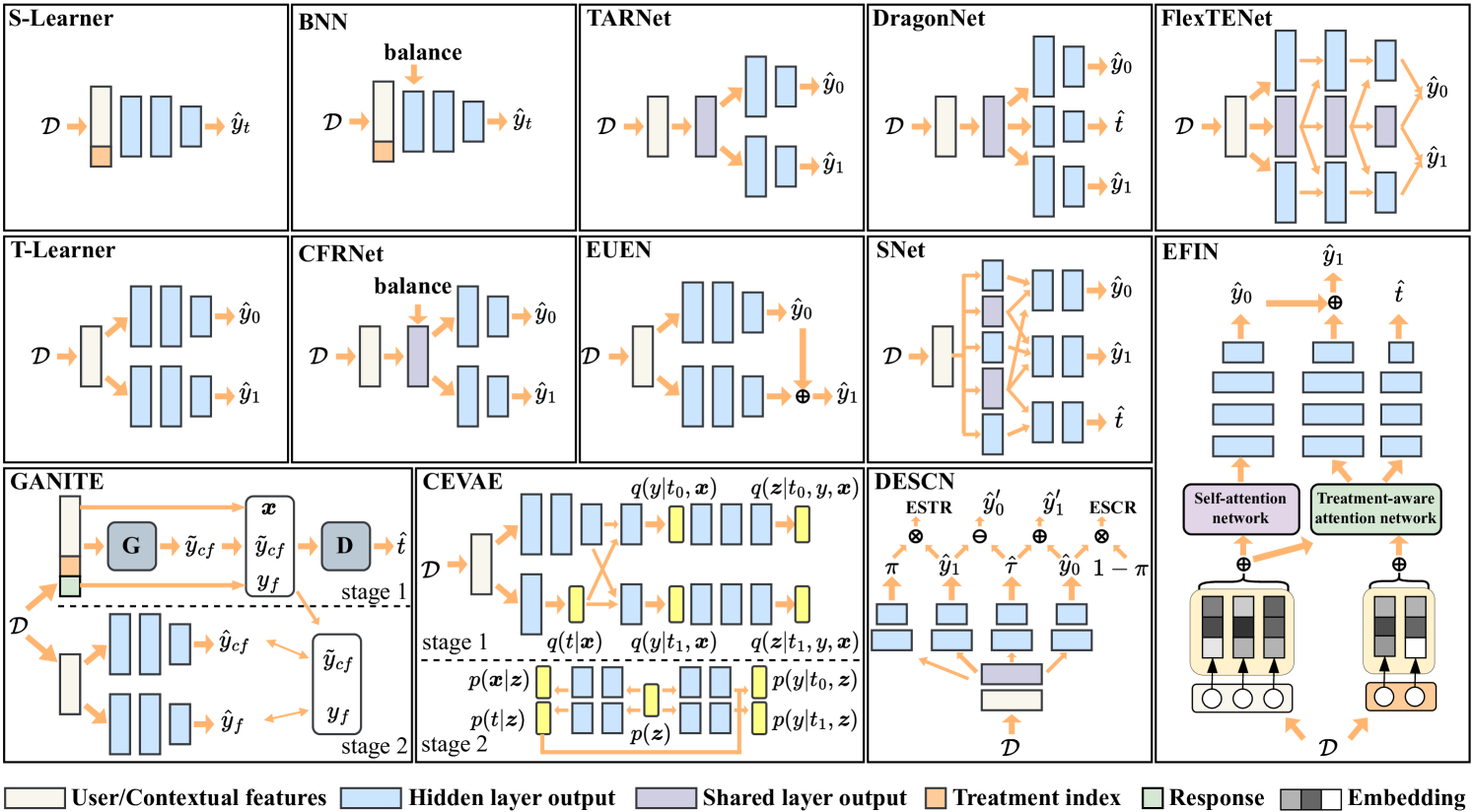
Online marketing is critical for many industrial platforms and business applications, aiming to increase user engagement and platform revenue by identifying corresponding delivery-sensitive groups for specific incentives, such as coupons and bonuses. As the scale and complexity of features in industrial scenarios increase, deep uplift modeling (DUM) as a promising technique has attracted increased research from academia and industry, resulting in various predictive models. However, current DUM still lacks some standardized benchmarks and unified evaluation protocols, which limit the reproducibility of experimental results in existing studies and the practical value and potential impact in this direction. In this paper, we provide an open benchmark for DUM and present comparison results of existing models in a reproducible and uniform manner. To this end, we conduct extensive experiments on two representative industrial datasets with different preprocessing settings to re-evaluate 13 existing models. Surprisingly, our experimental results show that the most recent work differs less than expected from traditional work in many cases. In addition, our experiments also reveal the limitations of DUM in generalization, especially for different preprocessing and test distributions. Our benchmarking work allows researchers to evaluate the performance of new models quickly but also reasonably demonstrates fair comparison results with existing models. It also gives practitioners valuable insights into often overlooked considerations when deploying DUM. We will make this benchmarking library, evaluation protocol, and experimental setup available on GitHub.
Read more6/4/2024

0
Rankability-enhanced Revenue Uplift Modeling Framework for Online Marketing
Bowei He, Yunpeng Weng, Xing Tang, Ziqiang Cui, Zexu Sun, Liang Chen, Xiuqiang He, Chen Ma
Uplift modeling has been widely employed in online marketing by predicting the response difference between the treatment and control groups, so as to identify the sensitive individuals toward interventions like coupons or discounts. Compared with traditional textit{conversion uplift modeling}, textit{revenue uplift modeling} exhibits higher potential due to its direct connection with the corporate income. However, previous works can hardly handle the continuous long-tail response distribution in revenue uplift modeling. Moreover, they have neglected to optimize the uplift ranking among different individuals, which is actually the core of uplift modeling. To address such issues, in this paper, we first utilize the zero-inflated lognormal (ZILN) loss to regress the responses and customize the corresponding modeling network, which can be adapted to different existing uplift models. Then, we study the ranking-related uplift modeling error from the theoretical perspective and propose two tighter error bounds as the additional loss terms to the conventional response regression loss. Finally, we directly model the uplift ranking error for the entire population with a listwise uplift ranking loss. The experiment results on offline public and industrial datasets validate the effectiveness of our method for revenue uplift modeling. Furthermore, we conduct large-scale experiments on a prominent online fintech marketing platform, Tencent FiT, which further demonstrates the superiority of our method in real-world applications.
Read more6/13/2024
↗️
0
Enhancing Uplift Modeling in Multi-Treatment Marketing Campaigns: Leveraging Score Ranking and Calibration Techniques
Yoon Tae Park, Ting Xu, Mohamed Anany
Uplift modeling is essential for optimizing marketing strategies by selecting individuals likely to respond positively to specific marketing campaigns. This importance escalates in multi-treatment marketing campaigns, where diverse treatment is available and we may want to assign the customers to treatment that can make the most impact. While there are existing approaches with convenient frameworks like Causalml, there are potential spaces to enhance the effect of uplift modeling in multi treatment cases. This paper introduces a novel approach to uplift modeling in multi-treatment campaigns, leveraging score ranking and calibration techniques to improve overall performance of the marketing campaign. We review existing uplift models, including Meta Learner frameworks (S, T, X), and their application in real-world scenarios. Additionally, we delve into insights from multi-treatment studies to highlight the complexities and potential advancements in the field. Our methodology incorporates Meta-Learner calibration and a scoring rank-based offer selection strategy. Extensive experiment results with real-world datasets demonstrate the practical benefits and superior performance of our approach. The findings underscore the critical role of integrating score ranking and calibration techniques in refining the performance and reliability of uplift predictions, thereby advancing predictive modeling in marketing analytics and providing actionable insights for practitioners seeking to optimize their campaign strategies.
Read more8/28/2024

0
A Comprehensive Benchmark of Machine and Deep Learning Across Diverse Tabular Datasets
Assaf Shmuel, Oren Glickman, Teddy Lazebnik
The analysis of tabular datasets is highly prevalent both in scientific research and real-world applications of Machine Learning (ML). Unlike many other ML tasks, Deep Learning (DL) models often do not outperform traditional methods in this area. Previous comparative benchmarks have shown that DL performance is frequently equivalent or even inferior to models such as Gradient Boosting Machines (GBMs). In this study, we introduce a comprehensive benchmark aimed at better characterizing the types of datasets where DL models excel. Although several important benchmarks for tabular datasets already exist, our contribution lies in the variety and depth of our comparison: we evaluate 111 datasets with 20 different models, including both regression and classification tasks. These datasets vary in scale and include both those with and without categorical variables. Importantly, our benchmark contains a sufficient number of datasets where DL models perform best, allowing for a thorough analysis of the conditions under which DL models excel. Building on the results of this benchmark, we train a model that predicts scenarios where DL models outperform alternative methods with 86.1% accuracy (AUC 0.78). We present insights derived from this characterization and compare these findings to previous benchmarks.
Read more8/28/2024