HPAC-ML: A Programming Model for Embedding ML Surrogates in Scientific Applications

0

Sign in to get full access
Overview
- Presents a programming model called HPAC-ML for embedding machine learning (ML) surrogates in scientific applications
- Aims to simplify the integration of ML models into high-performance computing (HPC) applications
- Provides a framework for managing the execution and data flow between ML models and the main application
Plain English Explanation
The paper introduces a programming model called HPAC-ML that makes it easier to incorporate machine learning surrogates into scientific computing applications. In many fields, such as computational chemistry or climate modeling, the underlying physics-based simulations can be very computationally intensive. Machine learning models can be used as surrogate models to approximate these simulations more efficiently.
However, integrating these ML models into existing high-performance computing (HPC) applications can be challenging. HPAC-ML provides a framework to simplify this process. It allows researchers to define the data flow and execution of the ML models within their scientific applications, without having to worry about the low-level details of managing the ML models. This can make it easier for domain experts to leverage the benefits of ML in HPC applications.
Technical Explanation
The HPAC-ML programming model defines a set of abstractions and APIs that enable the seamless integration of ML surrogates into scientific applications. It provides a way to define the data flow between the ML models and the main application, as well as how the ML models are executed.
Key features of HPAC-ML include:
- Declarative interface: Researchers can specify the ML models and their integration with the application using a declarative interface, without needing to write low-level implementation details.
- Automatic data management: HPAC-ML handles the transfer of data between the ML models and the main application, relieving researchers from manual data management tasks.
- Accelerator support: The model supports the use of hardware accelerators, such as GPUs, for efficient execution of the ML models.
- Fault tolerance: HPAC-ML provides mechanisms for checkpointing and restarting the execution of ML models, enhancing the resilience of the overall application.
The paper presents the design and implementation of HPAC-ML, as well as case studies demonstrating its use in two scientific applications: a computational fluid dynamics simulation and a materials science problem.
Critical Analysis
The HPAC-ML programming model addresses an important challenge in the integration of ML models into HPC applications. By providing a higher-level abstraction, it can simplify the process for domain experts who may not have extensive expertise in machine learning or parallel programming.
However, the paper does not provide a detailed evaluation of the performance and scalability of HPAC-ML compared to alternative approaches. While the case studies demonstrate its use in specific applications, more comprehensive benchmarking would be needed to assess its broader applicability and advantages.
Additionally, the paper does not discuss potential limitations or challenges in using HPAC-ML, such as the overhead of the additional abstraction layer or the suitability of the model for different types of ML models or application domains. Further research and real-world deployments may uncover additional considerations that should be addressed.
Conclusion
The HPAC-ML programming model presents a promising approach to simplifying the integration of ML surrogates into scientific computing applications. By providing a declarative interface and automated data management, it can help domain experts leverage the benefits of ML without the burden of complex implementation details. While the paper demonstrates the feasibility of the approach, further research and evaluation will be needed to assess its broader impact and applicability in the field of high-performance computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HPAC-ML: A Programming Model for Embedding ML Surrogates in Scientific Applications
Zane Fink, Konstantinos Parasyris, Praneet Rathi, Giorgis Georgakoudis, Harshitha Menon, Peer-Timo Bremer
Recent advancements in Machine Learning (ML) have substantially improved its predictive and computational abilities, offering promising opportunities for surrogate modeling in scientific applications. By accurately approximating complex functions with low computational cost, ML-based surrogates can accelerate scientific applications by replacing computationally intensive components with faster model inference. However, integrating ML models into these applications remains a significant challenge, hindering the widespread adoption of ML surrogates as an approximation technique in modern scientific computing. We propose an easy-to-use directive-based programming model that enables developers to seamlessly describe the use of ML models in scientific applications. The runtime support, as instructed by the programming model, performs data assimilation using the original algorithm and can replace the algorithm with model inference. Our evaluation across five benchmarks, testing over 5000 ML models, shows up to 83.6x speed improvements with minimal accuracy loss (as low as 0.01 RMSE).
Read more8/28/2024
0
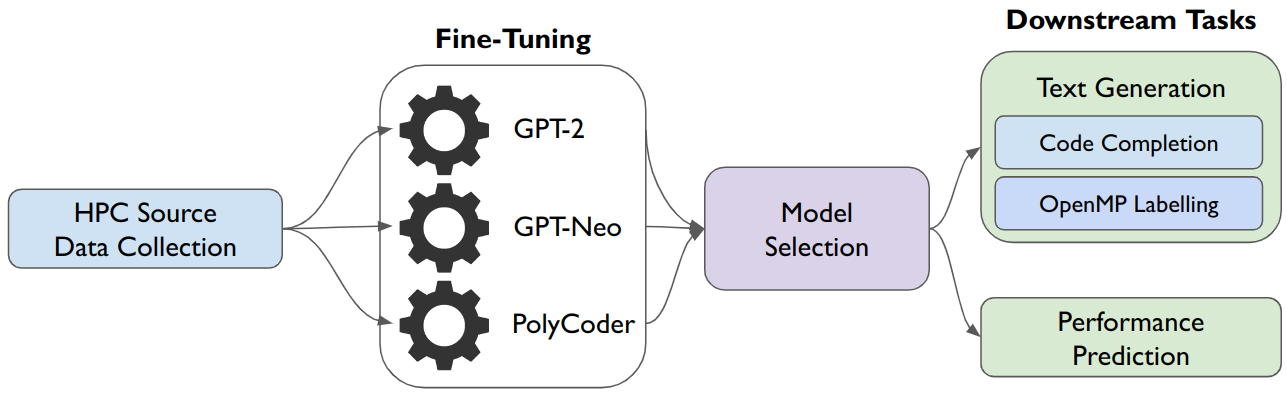
HPC-Coder: Modeling Parallel Programs using Large Language Models
Daniel Nichols, Aniruddha Marathe, Harshitha Menon, Todd Gamblin, Abhinav Bhatele
Parallel programs in high performance computing (HPC) continue to grow in complexity and scale in the exascale era. The diversity in hardware and parallel programming models make developing, optimizing, and maintaining parallel software even more burdensome for developers. One way to alleviate some of these burdens is with automated development and analysis tools. Such tools can perform complex and/or remedial tasks for developers that increase their productivity and decrease the chance for error. Until recently, such tools for code development and performance analysis have been limited in the complexity of tasks they can perform, especially for parallel programs. However, with recent advancements in language modeling, and the availability of large amounts of open-source code related data, these tools have started to utilize predictive language models to automate more complex tasks. In this paper, we show how large language models (LLMs) can be applied to tasks specific to high performance and scientific codes. We introduce a new dataset of HPC and scientific codes and use it to fine-tune several pre-trained models. We compare several pre-trained LLMs on HPC-related tasks and introduce a new model, HPC-Coder, fine-tuned on parallel codes. In our experiments, we show that this model can auto-complete HPC functions where generic models cannot, decorate for loops with OpenMP pragmas, and model performance changes in scientific application repositories as well as programming competition solutions.
Read more5/15/2024

0
A Large-Scale Study of Model Integration in ML-Enabled Software Systems
Yorick Sens, Henriette Knopp, Sven Peldszus, Thorsten Berger
The rise of machine learning (ML) and its embedding in systems has drastically changed the engineering of software-intensive systems. Traditionally, software engineering focuses on manually created artifacts such as source code and the process of creating them, as well as best practices for integrating them, i.e., software architectures. In contrast, the development of ML artifacts, i.e. ML models, comes from data science and focuses on the ML models and their training data. However, to deliver value to end users, these ML models must be embedded in traditional software, often forming complex topologies. In fact, ML-enabled software can easily incorporate many different ML models. While the challenges and practices of building ML-enabled systems have been studied to some extent, beyond isolated examples, little is known about the characteristics of real-world ML-enabled systems. Properly embedding ML models in systems so that they can be easily maintained or reused is far from trivial. We need to improve our empirical understanding of such systems, which we address by presenting the first large-scale study of real ML-enabled software systems, covering over 2,928 open source systems on GitHub. We classified and analyzed them to determine their characteristics, as well as their practices for reusing ML models and related code, and the architecture of these systems. Our findings provide practitioners and researchers with insight into practices for embedding and integrating ML models, bringing data science and software engineering closer together.
Read more8/13/2024

0
CubicML: Automated ML for Distributed ML Systems Co-design with ML Prediction of Performance
Wei Wen, Quanyu Zhu, Weiwei Chu, Wen-Yen Chen, Jiyan Yang
Scaling up deep learning models has been proven effective to improve intelligence of machine learning (ML) models, especially for industry recommendation models and large language models. The co-design of distributed ML systems and algorithms (to maximize training performance) plays a pivotal role for its success. As it scales, the number of co-design hyper-parameters grows rapidly which brings challenges to feasibly find the optimal setup for system performance maximization. In this paper, we propose CubicML which uses ML to automatically optimize training performance of distributed ML systems. In CubicML, we use a ML model as a proxy to predict the training performance for search efficiency and performance modeling flexibility. We proved that CubicML can effectively optimize training speed of in-house ads recommendation models and large language models at Meta.
Read more9/10/2024