Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws

0

Sign in to get full access
Overview
- This paper examines the relationship between the computational cost of training language models and their real-world performance, challenging the widely-accepted "Chinchilla-optimal" scaling law.
- The authors argue that the Chinchilla scaling law, which predicts the optimal performance-cost trade-off, does not fully account for the cost of inference (i.e., using the trained model to generate predictions).
- They propose a new framework that incorporates inference costs and show that the optimal model size and compute budget can be significantly larger than what the Chinchilla scaling law suggests.
Plain English Explanation
The paper looks at the relationship between the amount of computing power used to train large language models and how well those models perform in the real world. The widely-accepted "Chinchilla-optimal" scaling law suggests there is an optimal balance between model size, training compute, and performance.
However, the authors argue that this law doesn't fully account for the cost of actually using the trained model to generate new text (a process called "inference"). They develop a new framework that includes the cost of inference, and show that the optimal model size and computing budget can be much larger than what the Chinchilla scaling law predicts.
In other words, if you're willing to spend more on running the model, you can actually build a larger, more powerful model that performs better overall, even though it cost more to train initially. This challenges the conventional wisdom around the "sweet spot" for model size and compute.
Technical Explanation
The paper builds on previous work on language model scaling laws, which describe the empirical relationship between model size, training compute, and task performance. The widely-used "Chinchilla-optimal" scaling law suggests an optimal trade-off between these factors.
However, the authors argue that the Chinchilla framework does not account for the real-world cost of using the trained model to generate new text (inference), which can be significant. They propose a new "real-world cost optimality" framework that incorporates both training and inference costs.
Through extensive experiments, the authors show that the optimal model size and compute budget can be much larger than what the Chinchilla scaling law predicts. This is because the increased performance from a larger, more powerful model can outweigh the higher inference costs.
The authors demonstrate their framework on a range of language modeling tasks and datasets, including GPT-3 and GPT-J. They also discuss the implications of their findings for the future development of large language models and the importance of considering inference costs in model scaling.
Critical Analysis
The paper provides a compelling critique of the Chinchilla-optimal scaling law, highlighting an important limitation in its failure to account for inference costs. The authors' new framework offers a more comprehensive and realistic approach to understanding the optimal trade-offs between model size, training compute, and real-world performance.
However, the paper does not fully address some potential caveats and areas for further research. For example, the authors use a simplified model for inference costs that may not capture the full complexity of real-world deployment scenarios. Additionally, the experiments are limited to a relatively narrow set of language modeling tasks, and it's unclear how the findings would generalize to other domains or applications.
Furthermore, the paper does not delve into the broader societal implications of scaling language models beyond the Chinchilla-optimal regime. As these models become larger and more powerful, there may be concerns around their environmental impact, fairness, and potential misuse that warrant further investigation.
Overall, the paper makes a valuable contribution by challenging the conventional wisdom on language model scaling and offering a more nuanced framework for optimizing model development. However, there are still open questions and areas for future research to fully understand the trade-offs and implications of this approach.
Conclusion
This paper presents a compelling critique of the widely-accepted "Chinchilla-optimal" scaling law for large language models. By incorporating the cost of inference (using the trained model to generate new text) into their analysis, the authors show that the optimal model size and compute budget can be significantly larger than what the Chinchilla scaling law suggests.
Their new "real-world cost optimality" framework offers a more comprehensive and realistic approach to understanding the trade-offs between model size, training compute, and performance. This has important implications for the future development of large language models, as it suggests that investing in larger, more powerful models may be justified if the increased performance outweighs the higher inference costs.
While the paper raises important considerations, there are still open questions and areas for further research, such as the generalizability of the findings to other domains and the broader societal implications of scaling language models beyond the Chinchilla-optimal regime. Nonetheless, this work challenges the status quo and encourages a more nuanced and holistic perspective on the optimization of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws
Nikhil Sardana, Jacob Portes, Sasha Doubov, Jonathan Frankle
Large language model (LLM) scaling laws are empirical formulas that estimate changes in model quality as a result of increasing parameter count and training data. However, these formulas, including the popular Deepmind Chinchilla scaling laws, neglect to include the cost of inference. We modify the Chinchilla scaling laws to calculate the optimal LLM parameter count and pre-training data size to train and deploy a model of a given quality and inference demand. We conduct our analysis both in terms of a compute budget and real-world costs and find that LLM researchers expecting reasonably large inference demand (~1B requests) should train models smaller and longer than Chinchilla-optimal. Furthermore, we train 47 models of varying sizes and parameter counts to validate our formula and find that model quality continues to improve as we scale tokens per parameter to extreme ranges (up to 10,000). Finally, we ablate the procedure used to fit the Chinchilla scaling law coefficients and find that developing scaling laws only from data collected at typical token/parameter ratios overestimates the impact of additional tokens at these extreme ranges.
Read more7/19/2024
✅
0
More Compute Is What You Need
Zhen Guo
Large language model pre-training has become increasingly expensive, with most practitioners relying on scaling laws to allocate compute budgets for model size and training tokens, commonly referred to as Compute-Optimal or Chinchilla Optimal. In this paper, we hypothesize a new scaling law that suggests model performance depends mostly on the amount of compute spent for transformer-based models, independent of the specific allocation to model size and dataset size. Using this unified scaling law, we predict that (a) for inference efficiency, training should prioritize smaller model sizes and larger training datasets, and (b) assuming the exhaustion of available web datasets, scaling the model size might be the only way to further improve model performance.
Read more5/3/2024

0
Language models scale reliably with over-training and on downstream tasks
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Luca Soldaini, Alexandros G. Dimakis, Gabriel Ilharco, Pang Wei Koh, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Niklas Muennighoff, Ludwig Schmidt
Scaling laws are useful guides for derisking expensive training runs, as they predict performance of large models using cheaper, small-scale experiments. However, there remain gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., Chinchilla optimal regime). In contrast, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but models are usually compared on downstream task performance. To address both shortcomings, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we fit scaling laws that extrapolate in both the amount of over-training and the number of model parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$times$ over-trained) and a 6.9B parameter, 138B token run (i.e., a compute-optimal run)$unicode{x2014}$each from experiments that take 300$times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance by proposing a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models, using experiments that take 20$times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
Read more6/18/2024
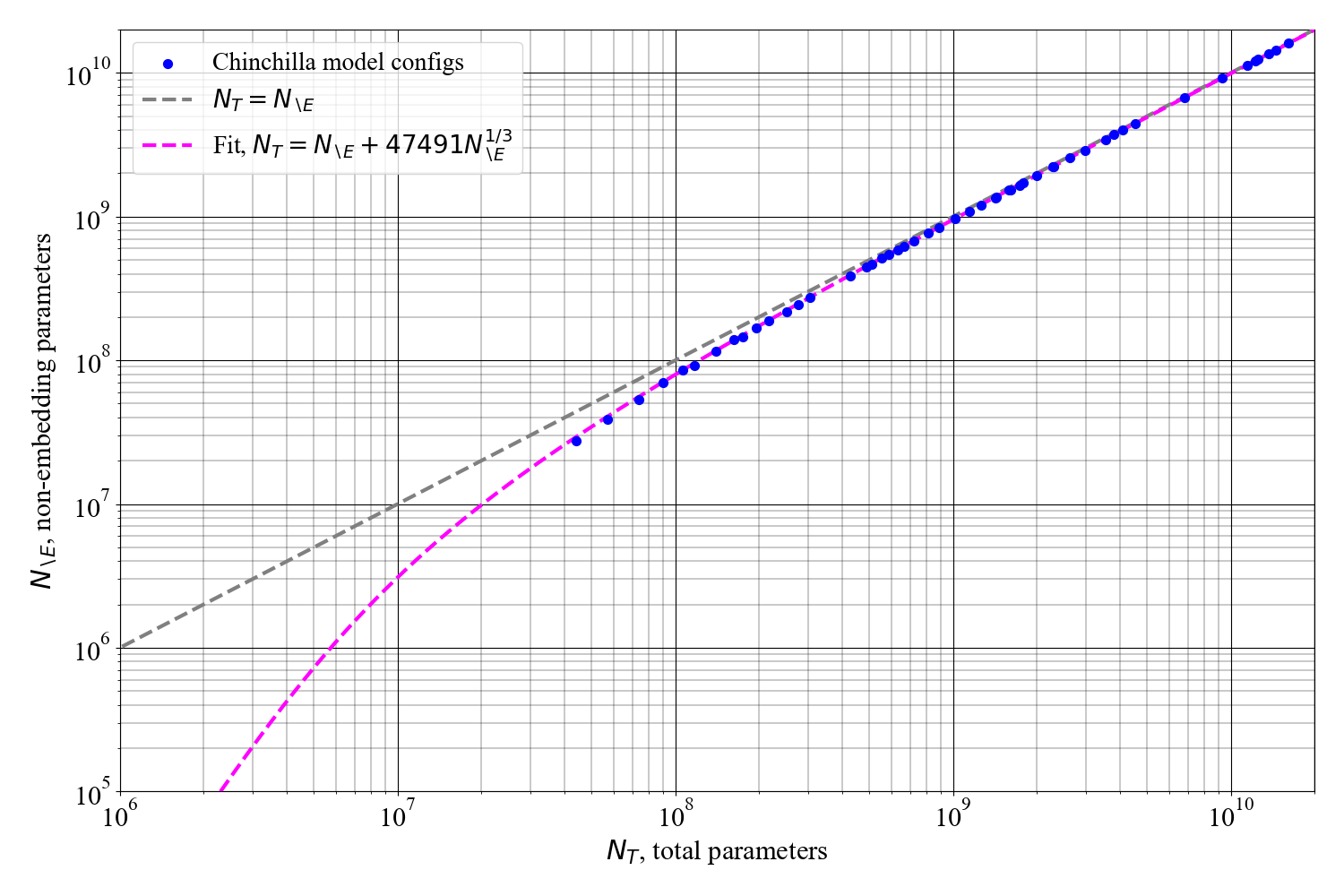
0
Reconciling Kaplan and Chinchilla Scaling Laws
Tim Pearce, Jinyeop Song
Kaplan et al. [2020] (`Kaplan') and Hoffmann et al. [2022] (`Chinchilla') studied the scaling behavior of transformers trained on next-token language prediction. These studies produced different estimates for how the number of parameters ($N$) and training tokens ($D$) should be set to achieve the lowest possible loss for a given compute budget ($C$). Kaplan: $N_text{optimal} propto C^{0.73}$, Chinchilla: $N_text{optimal} propto C^{0.50}$. This note finds that much of this discrepancy can be attributed to Kaplan counting non-embedding rather than total parameters, combined with their analysis being performed at small scale. Simulating the Chinchilla study under these conditions produces biased scaling coefficients close to Kaplan's. Hence, this note reaffirms Chinchilla's scaling coefficients, by explaining the cause of Kaplan's original overestimation.
Read more6/21/2024