Reconciling Kaplan and Chinchilla Scaling Laws

0
Sign in to get full access
Overview
- This paper reconciles two influential scaling laws in machine learning: the Kaplan scaling law and the Chinchilla scaling law.
- The Kaplan scaling law suggests that model performance scales as a power law with respect to model size and compute.
- The Chinchilla scaling law suggests that model performance scales more efficiently by tuning the compute and dataset size together.
- The paper aims to resolve the apparent contradiction between these two scaling laws and provide a unified framework for understanding model scaling.
Plain English Explanation
The paper explores how the performance of large machine learning models, like language models, improves as they get bigger and train on more data. There are two main theories, or "scaling laws," that try to explain this relationship:
-
The Kaplan scaling law says that model performance scales as a power law - in other words, doubling the model size and compute leads to a predictable increase in performance.
-
The Chinchilla scaling law suggests that to get the most efficient scaling, you need to tune both the model size and the amount of training data together.
These two scaling laws seem to contradict each other. This paper tries to reconcile them and provide a unified way of understanding how large models scale. It does this through a careful analysis and some experiments that help explain the relationship between model size, compute, and dataset size.
Understanding scaling laws is important because it allows us to predict how much compute and data we'll need to achieve certain performance targets as we build ever-larger machine learning models. This helps guide the development of future AI systems.
Technical Explanation
The paper first reviews the Kaplan scaling law and the Chinchilla scaling law. It then presents an analysis that shows how these two scaling laws can be reconciled.
The key insight is that the Kaplan scaling law describes a short-term or "transient" scaling regime, where performance scales as a power law with respect to model size and compute. But as training progresses and the model becomes more data-efficient, the scaling transitions to the Chinchilla regime, where tuning both model size and dataset size together leads to more efficient scaling.
The paper supports this analysis with experiments on language modeling tasks. It shows that early in training, performance follows the Kaplan scaling law, but later in training it transitions to the Chinchilla scaling regime. The authors also demonstrate that the transition point depends on factors like model architecture and task difficulty.
Overall, the paper provides a unifying framework for understanding scaling laws in machine learning. It suggests that different scaling regimes may apply at different stages of training, and that jointly optimizing model size and dataset size is key to achieving the most efficient scaling.
Critical Analysis
The paper provides a thoughtful analysis that helps resolve the apparent contradiction between the Kaplan and Chinchilla scaling laws. However, it's important to note a few caveats and limitations:
-
The analysis and experiments are focused on language modeling tasks. It's not clear how well the findings would generalize to other types of machine learning problems.
-
The paper doesn't explore the underlying reasons why the scaling transitions from the Kaplan to the Chinchilla regime. Further research would be needed to fully explain the mechanisms driving this transition.
-
The paper doesn't address potential issues with the Chinchilla scaling law, such as the challenges of obtaining massive datasets for training large models. Gzip has shown that data-dependent scaling laws can be difficult to generalize.
-
The paper could have provided a more in-depth discussion of the implications of this research for the development of future AI systems. How might it influence the way researchers and engineers approach model scaling and resource allocation?
Overall, the paper makes an important contribution to our understanding of scaling laws in machine learning. However, as with any research, there are still open questions and areas for further exploration.
Conclusion
This paper reconciles two influential scaling laws in machine learning - the Kaplan scaling law and the Chinchilla scaling law. It proposes a unifying framework that explains how different scaling regimes may apply at different stages of training.
The key insight is that early in training, performance follows the Kaplan scaling law, where it scales as a power law with respect to model size and compute. But as training progresses, the scaling transitions to the Chinchilla regime, where jointly optimizing model size and dataset size leads to more efficient scaling.
This research helps resolve the apparent contradiction between these two scaling laws and provides a more comprehensive understanding of how large machine learning models scale. It has important implications for the development of future AI systems, as it can help guide decisions about resource allocation and model architecture design.
While the paper focuses on language modeling tasks, the principles it establishes could potentially be applied to a wide range of machine learning problems. Further research would be needed to fully explore the generalizability of these findings and address some of the remaining open questions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reconciling Kaplan and Chinchilla Scaling Laws
Tim Pearce, Jinyeop Song
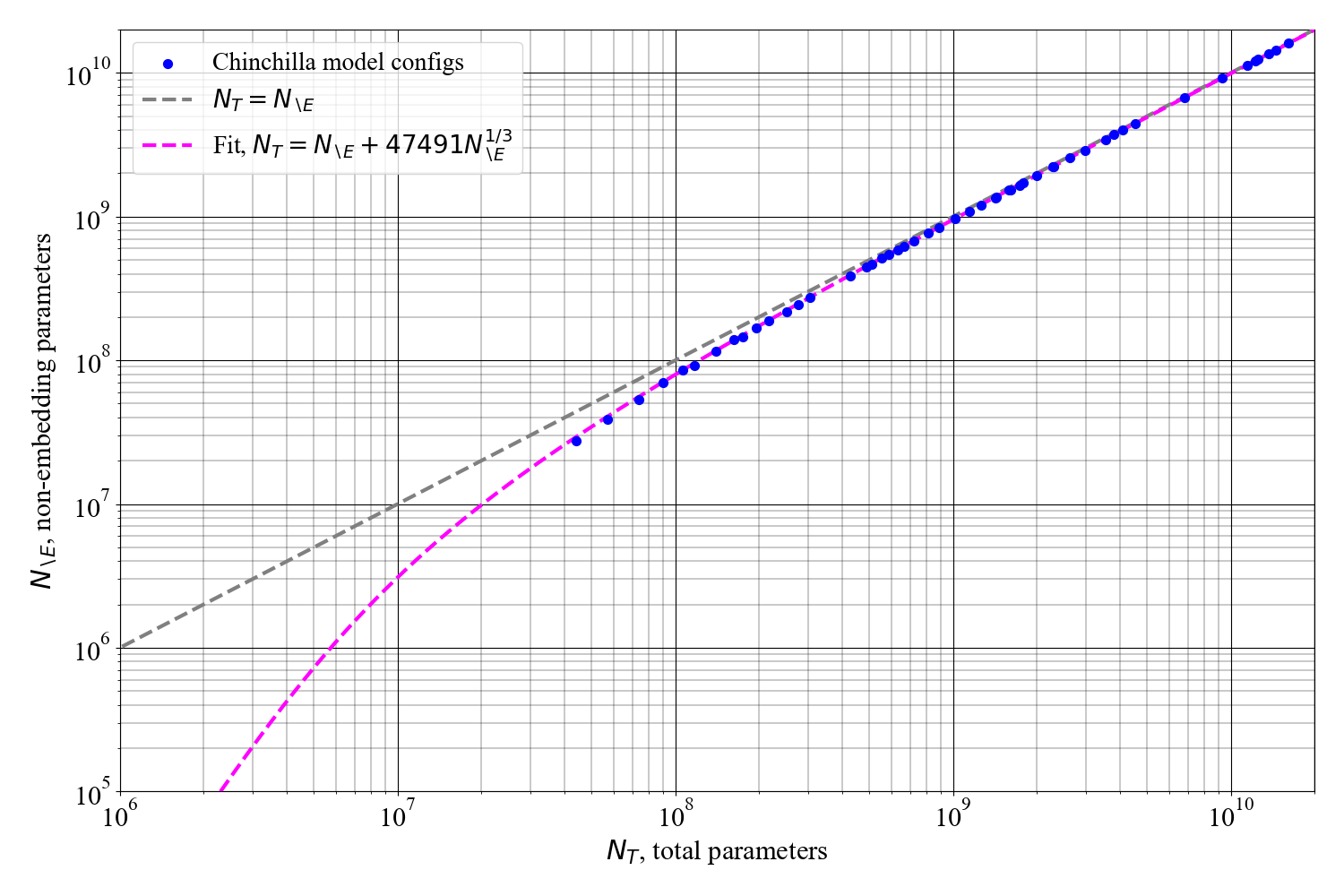
Kaplan et al. [2020] (`Kaplan') and Hoffmann et al. [2022] (`Chinchilla') studied the scaling behavior of transformers trained on next-token language prediction. These studies produced different estimates for how the number of parameters ($N$) and training tokens ($D$) should be set to achieve the lowest possible loss for a given compute budget ($C$). Kaplan: $N_text{optimal} propto C^{0.73}$, Chinchilla: $N_text{optimal} propto C^{0.50}$. This note finds that much of this discrepancy can be attributed to Kaplan counting non-embedding rather than total parameters, combined with their analysis being performed at small scale. Simulating the Chinchilla study under these conditions produces biased scaling coefficients close to Kaplan's. Hence, this note reaffirms Chinchilla's scaling coefficients, by explaining the cause of Kaplan's original overestimation.
Read more6/21/2024
86
Chinchilla Scaling: A replication attempt
Tamay Besiroglu, Ege Erdil, Matthew Barnett, Josh You
Hoffmann et al. (2022) propose three methods for estimating a compute-optimal scaling law. We attempt to replicate their third estimation procedure, which involves fitting a parametric loss function to a reconstruction of data from their plots. We find that the reported estimates are inconsistent with their first two estimation methods, fail at fitting the extracted data, and report implausibly narrow confidence intervals--intervals this narrow would require over 600,000 experiments, while they likely only ran fewer than 500. In contrast, our rederivation of the scaling law using the third approach yields results that are compatible with the findings from the first two estimation procedures described by Hoffmann et al.
Read more5/16/2024

0
Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws
Nikhil Sardana, Jacob Portes, Sasha Doubov, Jonathan Frankle
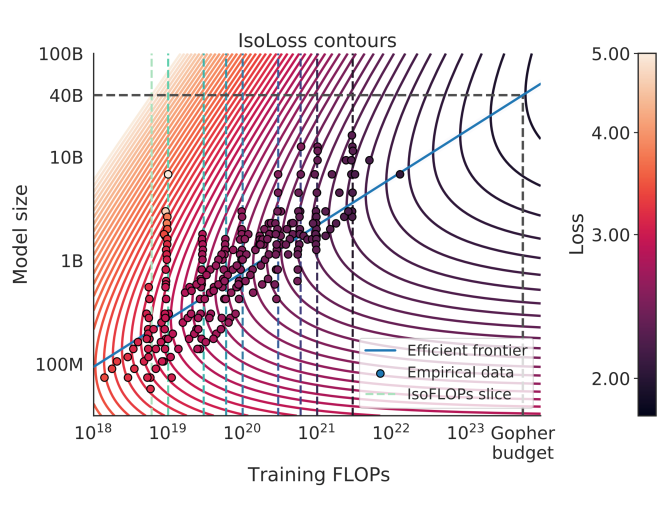
Large language model (LLM) scaling laws are empirical formulas that estimate changes in model quality as a result of increasing parameter count and training data. However, these formulas, including the popular Deepmind Chinchilla scaling laws, neglect to include the cost of inference. We modify the Chinchilla scaling laws to calculate the optimal LLM parameter count and pre-training data size to train and deploy a model of a given quality and inference demand. We conduct our analysis both in terms of a compute budget and real-world costs and find that LLM researchers expecting reasonably large inference demand (~1B requests) should train models smaller and longer than Chinchilla-optimal. Furthermore, we train 47 models of varying sizes and parameter counts to validate our formula and find that model quality continues to improve as we scale tokens per parameter to extreme ranges (up to 10,000). Finally, we ablate the procedure used to fit the Chinchilla scaling law coefficients and find that developing scaling laws only from data collected at typical token/parameter ratios overestimates the impact of additional tokens at these extreme ranges.
Read more7/19/2024

0
Resolving Discrepancies in Compute-Optimal Scaling of Language Models
Tomer Porian, Mitchell Wortsman, Jenia Jitsev, Ludwig Schmidt, Yair Carmon
Kaplan et al. and Hoffmann et al. developed influential scaling laws for the optimal model size as a function of the compute budget, but these laws yield substantially different predictions. We explain the discrepancy by reproducing the Kaplan scaling law on two datasets (OpenWebText2 and RefinedWeb) and identifying three factors causing the difference: last layer computational cost, warmup duration, and scale-dependent optimizer tuning. With these factors corrected, we obtain excellent agreement with the Hoffmann et al. (i.e., Chinchilla) scaling law. Counter to a hypothesis of Hoffmann et al., we find that careful learning rate decay is not essential for the validity of their scaling law. As a secondary result, we derive scaling laws for the optimal learning rate and batch size, finding that tuning the AdamW $beta_2$ parameter is essential at lower batch sizes.
Read more7/26/2024