Bias Correction in Machine Learning-based Classification of Rare Events

0
🏷️
Sign in to get full access
Overview
- Online platforms are a rare type of business that can be challenging to accurately identify using machine learning algorithms.
- This research paper describes a machine learning-based text classification approach that aims to reduce the number of false positives when predicting the presence of online platforms.
- The approach uses calibrated probabilities and ensemble methods to mitigate bias in the predictions.
Plain English Explanation
Online platforms, such as e-commerce marketplaces or social media sites, are a unique type of business that can be difficult to identify accurately using machine learning algorithms. This is because online platforms are relatively rare compared to other types of businesses, and the characteristics that define them can be subtle or complex.
To address this challenge, the researchers developed a machine learning-based text classification approach that aims to reduce the number of false positives, or instances where the algorithm incorrectly identifies a business as an online platform. The approach uses calibrated probabilities and ensemble methods to help mitigate the bias that can arise in these types of predictions.
By using these techniques, the researchers were able to improve the accuracy of their model in identifying online platforms, which can be important for event prediction and causality inference in areas like economic analysis or policy decision-making.
Technical Explanation
The researchers developed a machine learning-based text classification approach to identify online platforms from web-scraped text data. Online platforms are a rare type of business, so accurately predicting their presence is a challenging task that combines elements of natural language processing and rare event detection.
The researchers used calibrated probabilities and ensemble methods to address the bias that can arise when working with rare events. Calibrated probabilities help ensure that the model's output reflects the true likelihood of an event occurring, rather than being skewed by the rarity of the event. Ensemble methods, which combine the predictions of multiple models, can also help reduce bias and improve overall accuracy.
The researchers evaluated their approach on a dataset of web-scraped texts and found that it was able to significantly reduce the number of false positives compared to other classification methods. This is an important result, as minimizing false positives is crucial for applications where the accurate identification of online platforms is critical, such as economic analysis or policy decision-making.
Critical Analysis
The researchers acknowledge that their approach, while effective at reducing false positives, may still have some limitations. For example, the performance of the model may depend on the quality and representativeness of the training data, and the approach may not generalize well to different types of online platforms or business models.
Additionally, the researchers do not address the potential for the model to exhibit other forms of bias, such as demographic or algorithmic bias. This is an important consideration, as any bias in the model's predictions could have significant real-world consequences, particularly in applications where the identification of online platforms is used to inform policy decisions.
Further research could explore ways to mitigate unknown dataset bias and evaluate the robustness of the model to different types of inputs or perturbations. Additionally, the researchers could investigate the potential for their approach to be adapted to other rare event detection tasks.
Conclusion
This research paper presents a machine learning-based text classification approach that aims to improve the accurate identification of online platforms, a rare and challenging type of business to detect. By using calibrated probabilities and ensemble methods, the researchers were able to significantly reduce the number of false positives in their predictions, which is a crucial metric for applications where the accurate detection of online platforms is important.
While the approach has some limitations, the researchers' work highlights the value of developing specialized techniques for identifying rare events, particularly in domains where accurate predictions can have significant real-world implications. Further research in this area could lead to improvements in our ability to understand and monitor the online platform ecosystem, with potential benefits for economic analysis, policy decision-making, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Bias Correction in Machine Learning-based Classification of Rare Events
Luuk Gubbels, Marco Puts, Piet Daas
Online platform businesses can be identified by using web-scraped texts. This is a classification problem that combines elements of natural language processing and rare event detection. Because online platforms are rare, accurately identifying them with Machine Learning algorithms is challenging. Here, we describe the development of a Machine Learning-based text classification approach that reduces the number of false positives as much as possible. It greatly reduces the bias in the estimates obtained by using calibrated probabilities and ensembles.
Read more7/10/2024

0
Advancing Machine Learning in Industry 4.0: Benchmark Framework for Rare-event Prediction in Chemical Processes
Vikram Sudarshan, Warren D. Seider
Previously, using forward-flux sampling (FFS) and machine learning (ML), we developed multivariate alarm systems to counter rare un-postulated abnormal events. Our alarm systems utilized ML-based predictive models to quantify committer probabilities as functions of key process variables (e.g., temperature, concentrations, and the like), with these data obtained in FFS simulations. Herein, we introduce a novel and comprehensive benchmark framework for rare-event prediction, comparing ML algorithms of varying complexity, including Linear Support-Vector Regressor and k-Nearest Neighbors, to more sophisticated algorithms, such as Random Forests, XGBoost, LightGBM, CatBoost, Dense Neural Networks, and TabNet. This evaluation uses comprehensive performance metrics, such as: $textit{RMSE}$, model training, testing, hyperparameter tuning and deployment times, and number and efficiency of alarms. These balance model accuracy, computational efficiency, and alarm-system efficiency, identifying optimal ML strategies for predicting abnormal rare events, enabling operators to obtain safer and more reliable plant operations.
Read more9/4/2024

0
A Study on Bias Detection and Classification in Natural Language Processing
Ana Sofia Evans, Helena Moniz, Lu'isa Coheur
Human biases have been shown to influence the performance of models and algorithms in various fields, including Natural Language Processing. While the study of this phenomenon is garnering focus in recent years, the available resources are still relatively scarce, often focusing on different forms or manifestations of biases. The aim of our work is twofold: 1) gather publicly-available datasets and determine how to better combine them to effectively train models in the task of hate speech detection and classification; 2) analyse the main issues with these datasets, such as scarcity, skewed resources, and reliance on non-persistent data. We discuss these issues in tandem with the development of our experiments, in which we show that the combinations of different datasets greatly impact the models' performance.
Read more8/15/2024
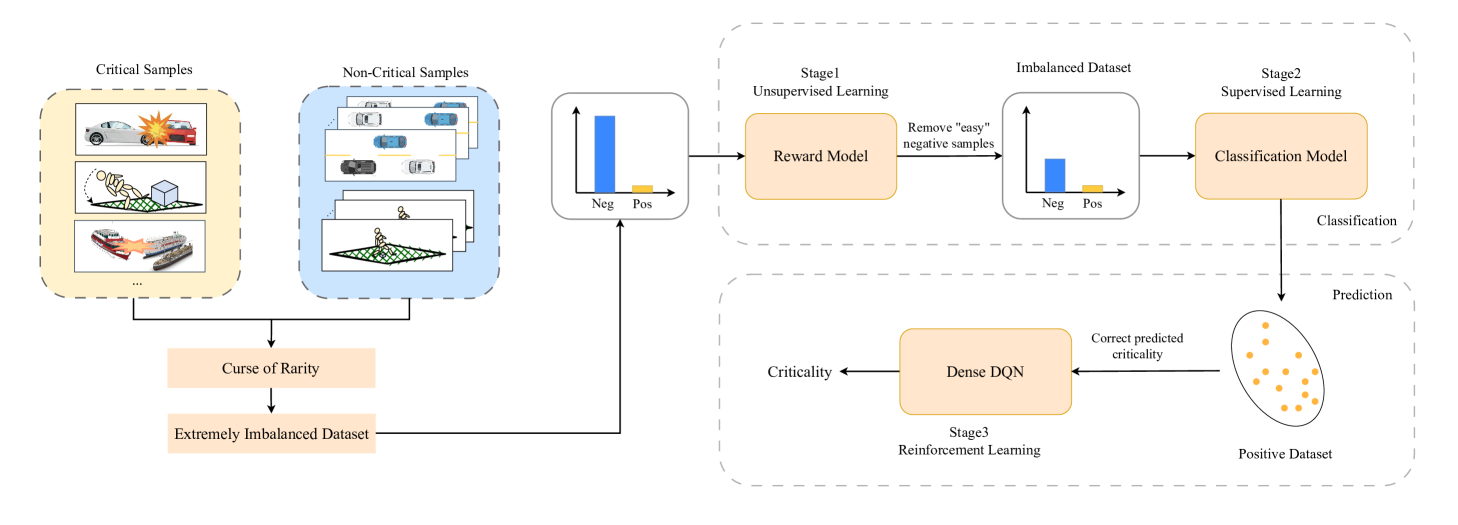
0
Accurately Predicting Probabilities of Safety-Critical Rare Events for Intelligent Systems
Ruoxuan Bai, Jingxuan Yang, Weiduo Gong, Yi Zhang, Qiujing Lu, Shuo Feng
Intelligent systems are increasingly integral to our daily lives, yet rare safety-critical events present significant latent threats to their practical deployment. Addressing this challenge hinges on accurately predicting the probability of safety-critical events occurring within a given time step from the current state, a metric we define as 'criticality'. The complexity of predicting criticality arises from the extreme data imbalance caused by rare events in high dimensional variables associated with the rare events, a challenge we refer to as the curse of rarity. Existing methods tend to be either overly conservative or prone to overlooking safety-critical events, thus struggling to achieve both high precision and recall rates, which severely limits their applicability. This study endeavors to develop a criticality prediction model that excels in both precision and recall rates for evaluating the criticality of safety-critical autonomous systems. We propose a multi-stage learning framework designed to progressively densify the dataset, mitigating the curse of rarity across stages. To validate our approach, we evaluate it in two cases: lunar lander and bipedal walker scenarios. The results demonstrate that our method surpasses traditional approaches, providing a more accurate and dependable assessment of criticality in intelligent systems.
Read more4/8/2024