Bias in LLMs as Annotators: The Effect of Party Cues on Labelling Decision by Large Language Models

0
Sign in to get full access
Overview
- This paper examines how political party cues can influence the labeling decisions of large language models (LLMs) when used as annotators.
- The researchers conducted experiments to see if LLMs would categorize social media posts differently based on the perceived political affiliation of the author.
- They found that LLMs were more likely to label posts negatively if they were associated with the opposing political party, suggesting the presence of partisan bias.
Plain English Explanation
The paper investigates how political biases can impact large language models (LLMs) when they are used to categorize or label text. The researchers conducted experiments where they showed LLMs social media posts and asked them to label the posts as positive or negative. However, the posts were artificially associated with either a Democratic or Republican political party.
The key finding was that the LLMs were more likely to label posts negatively if they were associated with the opposing political party. For example, an LLM might rate a post more negatively if it was associated with a Republican author, even if the content of the post was similar to one associated with a Democrat. This suggests the LLMs had developed some partisan biases in their decision-making.
This research is important because LLMs are increasingly being used as automated annotators or labelers of online content. If these systems exhibit political biases, it could lead to unfair or inaccurate categorization of information, with potential impacts on things like content moderation, information curation, and political discourse. Understanding and mitigating these biases is an important area of study.
Technical Explanation
The paper reports on a set of experiments that investigated the effects of political party cues on the labeling decisions of large language models (LLMs) acting as automated annotators. The researchers used three popular pre-trained LLMs - GPT-3, BERT, and RoBERTa - and presented them with social media posts that were artificially associated with either Democratic or Republican political affiliations.
The experimental design involved generating synthetic social media posts on various topics, then randomly assigning a Democratic or Republican party label to each post. The LLMs were then asked to classify each post as either positive or negative in sentiment. The key metric was whether the LLMs were more likely to label posts negatively if they were associated with the opposing political party, even if the content was similar.
The results showed a clear partisan bias effect, where the LLMs were significantly more likely to label posts negatively if they were associated with the opposing political party. This bias was observed across all three LLM models tested. The researchers also found that the degree of bias was correlated with the overall political leaning of the LLM, with more politically extreme models exhibiting stronger biases.
These findings underscore the importance of carefully evaluating the political biases that may be present in large language models, especially when they are used for tasks like content moderation or information curation. Unaddressed biases could lead to unfair or inaccurate labeling of information, with potentially serious societal consequences. Further research is needed to better understand the sources of these biases and develop techniques to mitigate them.
Critical Analysis
The paper provides a thoughtful and rigorous examination of the issue of political bias in large language models (LLMs) used as automated annotators. The experimental design is well-conceived, using synthetic social media posts and randomly assigned party labels to isolate the effect of political cues on the LLMs' labeling decisions.
One potential limitation is the use of only three pre-trained LLM models, which may not fully capture the diversity of models and their associated biases. It would be valuable to expand the analysis to a broader range of LLMs, including those with different training data, architectures, and intended use cases.
Additionally, while the paper demonstrates the presence of partisan bias, it does not delve deeply into the underlying mechanisms or sources of these biases. Further research could explore how factors like the LLMs' training data, fine-tuning procedures, and architectural choices contribute to the development of political biases.
Overall, this paper makes an important contribution to the growing body of research on the political biases present in large language models. The findings underscore the need for continued vigilance and rigorous evaluation of these systems, especially when they are deployed in high-stakes applications that could amplify or perpetuate societal biases.
Conclusion
This paper demonstrates that large language models (LLMs) can exhibit significant partisan biases when used as automated annotators, tending to label social media posts more negatively if they are associated with the opposing political party. These findings have important implications for the use of LLMs in content moderation, information curation, and other applications where fair and unbiased labeling is crucial.
The research highlights the need for continued study and mitigation of political biases in LLMs, as well as the importance of carefully evaluating the reliability and consistency of these models when deployed in real-world settings. By better understanding the sources and manifestations of these biases, the research community can work towards developing more equitable and trustworthy AI systems that serve the public interest.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bias in LLMs as Annotators: The Effect of Party Cues on Labelling Decision by Large Language Models
Sebastian Vallejo Vera, Hunter Driggers
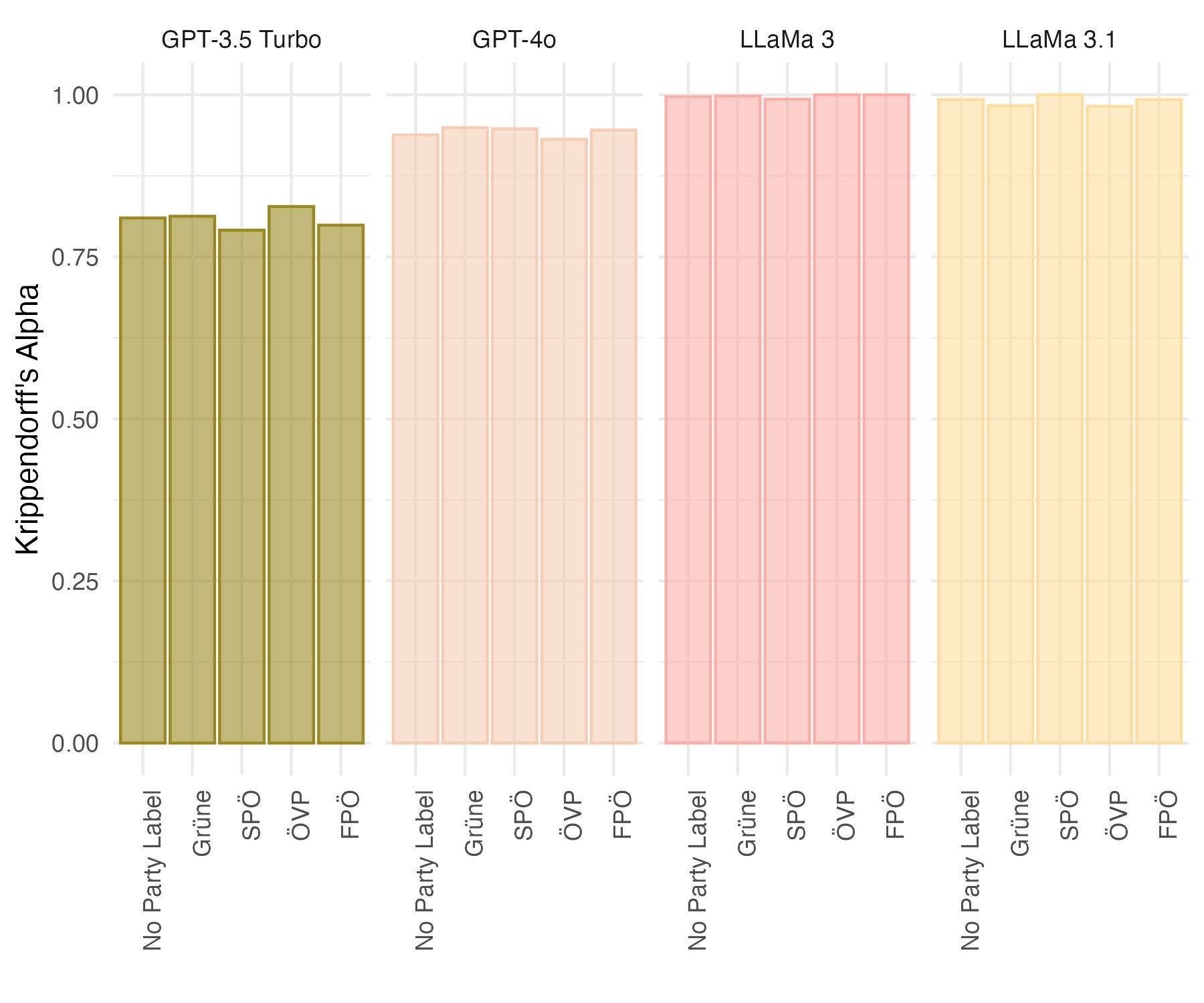
Human coders are biased. We test similar biases in Large Language Models (LLMs) as annotators. By replicating an experiment run by Ennser-Jedenastik and Meyer (2018), we find evidence that LLMs use political information, and specifically party cues, to judge political statements. Not only do LLMs use relevant information to contextualize whether a statement is positive, negative, or neutral based on the party cue, they also reflect the biases of the human-generated data upon which they have been trained. We also find that unlike humans, who are only biased when faced with statements from extreme parties, LLMs exhibit significant bias even when prompted with statements from center-left and center-right parties. The implications of our findings are discussed in the conclusion.
Read more8/29/2024

0
Examining the Influence of Political Bias on Large Language Model Performance in Stance Classification
Lynnette Hui Xian Ng, Iain Cruickshank, Roy Ka-Wei Lee
Large Language Models (LLMs) have demonstrated remarkable capabilities in executing tasks based on natural language queries. However, these models, trained on curated datasets, inherently embody biases ranging from racial to national and gender biases. It remains uncertain whether these biases impact the performance of LLMs for certain tasks. In this study, we investigate the political biases of LLMs within the stance classification task, specifically examining whether these models exhibit a tendency to more accurately classify politically-charged stances. Utilizing three datasets, seven LLMs, and four distinct prompting schemes, we analyze the performance of LLMs on politically oriented statements and targets. Our findings reveal a statistically significant difference in the performance of LLMs across various politically oriented stance classification tasks. Furthermore, we observe that this difference primarily manifests at the dataset level, with models and prompting schemes showing statistically similar performances across different stance classification datasets. Lastly, we observe that when there is greater ambiguity in the target the statement is directed towards, LLMs have poorer stance classification accuracy. Code & Dataset: http://doi.org/10.5281/zenodo.12938478
Read more7/29/2024
💬
0
Assessing Political Bias in Large Language Models
Luca Rettenberger, Markus Reischl, Mark Schutera
The assessment of bias within Large Language Models (LLMs) has emerged as a critical concern in the contemporary discourse surrounding Artificial Intelligence (AI) in the context of their potential impact on societal dynamics. Recognizing and considering political bias within LLM applications is especially important when closing in on the tipping point toward performative prediction. Then, being educated about potential effects and the societal behavior LLMs can drive at scale due to their interplay with human operators. In this way, the upcoming elections of the European Parliament will not remain unaffected by LLMs. We evaluate the political bias of the currently most popular open-source LLMs (instruct or assistant models) concerning political issues within the European Union (EU) from a German voter's perspective. To do so, we use the Wahl-O-Mat, a voting advice application used in Germany. From the voting advice of the Wahl-O-Mat we quantize the degree of alignment of LLMs with German political parties. We show that larger models, such as Llama3-70B, tend to align more closely with left-leaning political parties, while smaller models often remain neutral, particularly when prompted in English. The central finding is that LLMs are similarly biased, with low variances in the alignment concerning a specific party. Our findings underline the importance of rigorously assessing and making bias transparent in LLMs to safeguard the integrity and trustworthiness of applications that employ the capabilities of performative prediction and the invisible hand of machine learning prediction and language generation.
Read more6/6/2024
0
Beyond prompt brittleness: Evaluating the reliability and consistency of political worldviews in LLMs
Tanise Ceron, Neele Falk, Ana Bari'c, Dmitry Nikolaev, Sebastian Pad'o
Due to the widespread use of large language models (LLMs), we need to understand whether they embed a specific worldview and what these views reflect. Recent studies report that, prompted with political questionnaires, LLMs show left-liberal leanings (Feng et al., 2023; Motoki et al., 2024). However, it is as yet unclear whether these leanings are reliable (robust to prompt variations) and whether the leaning is consistent across policies and political leaning. We propose a series of tests which assess the reliability and consistency of LLMs' stances on political statements based on a dataset of voting-advice questionnaires collected from seven EU countries and annotated for policy issues. We study LLMs ranging in size from 7B to 70B parameters and find that their reliability increases with parameter count. Larger models show overall stronger alignment with left-leaning parties but differ among policy programs: They show a (left-wing) positive stance towards environment protection, social welfare state and liberal society but also (right-wing) law and order, with no consistent preferences in the areas of foreign policy and migration.
Read more8/12/2024