Bias of Stochastic Gradient Descent or the Architecture: Disentangling the Effects of Overparameterization of Neural Networks

0
🧠
Sign in to get full access
Overview
- Investigates whether the bias in neural network models is primarily due to the optimization process (stochastic gradient descent) or the architecture itself.
- Experiments with different architectures and optimization methods to disentangle these effects.
- Provides insights into the role of overparameterization in neural network generalization.
Plain English Explanation
The paper explores a fundamental question in machine learning: what is the primary driver of the biases that emerge in neural network models? Is it the optimization process, specifically the use of stochastic gradient descent (SGD), or is it the architecture of the neural network itself?
To investigate this, the researchers conduct a series of experiments that systematically vary the architecture and optimization method. They compare the performance of models trained using different combinations of architectures (e.g., wide vs. deep) and optimization approaches (e.g., SGD vs. batch gradient descent).
The key insight from this research is that the architecture of the neural network plays a crucial role in determining the biases that arise, even more so than the optimization method. In other words, the inherent structure and parameterization of the neural network have a significant influence on the types of solutions the model converges to, regardless of how it is trained.
This finding has important implications for the field of neural network design and understanding generalization. It suggests that the choice of network architecture is a critical factor in shaping the biases and behaviors of the trained model, beyond just the optimization approach used.
Technical Explanation
The paper investigates the relative contributions of the optimization process (specifically, stochastic gradient descent) and the neural network architecture in determining the biases that emerge during training.
To disentangle these effects, the researchers conducted experiments with different network architectures (e.g., wide vs. deep models) and optimization methods (e.g., SGD vs. batch gradient descent). They analyzed the performance and generalization behavior of these models, as well as the bias in the learned representations.
The key finding is that the architecture of the neural network plays a more significant role in shaping the biases than the optimization method. Even when using the same optimization approach (e.g., SGD), the researchers observed substantial differences in the biases that emerged, depending on the network architecture.
This suggests that the inherent structure and parameterization of the neural network have a profound impact on the types of solutions the model converges to, regardless of the optimization strategy employed. The degree of overparameterization in the network architecture appears to be a critical factor in determining the biases that arise during training.
Critical Analysis
The paper provides valuable insights into the relative contributions of optimization and architecture in shaping the biases of neural network models. However, it is essential to note some caveats and potential limitations of the research:
-
Experimental Scope: The experiments focused on a limited set of architectures and optimization methods. It would be helpful to expand the scope to include a wider range of network designs and training algorithms to further validate the findings.
-
Generalization to More Complex Tasks: The experiments were conducted on relatively simple datasets and tasks. It is unclear whether the same conclusions would hold for more challenging, real-world problems, where the interactions between architecture and optimization may be more complex.
-
Theoretical Underpinnings: The paper provides empirical evidence, but a more rigorous theoretical framework could help deepen the understanding of the underlying mechanisms driving the observed biases.
-
Practical Implications: While the findings emphasize the importance of architecture design, the paper does not offer specific guidelines or recommendations for how to leverage this knowledge to improve neural network performance and generalization.
Overall, this research represents an important step towards disentangling the effects of overparameterization and shedding light on the factors that shape the biases in neural network models. Further investigation and refinement of the ideas presented in this paper could lead to valuable insights for the design of more robust and generalizable machine learning systems.
Conclusion
The key takeaway from this research is that the architecture of a neural network plays a more significant role in shaping the biases that emerge during training than the optimization method used, such as stochastic gradient descent. This finding has important implications for the field of neural network design and understanding the factors that contribute to model generalization.
By disentangling the effects of optimization and architecture, this paper provides a valuable perspective on the fundamental drivers of biases in neural networks. These insights could inform the development of more effective and unbiased machine learning models, with far-reaching implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Bias of Stochastic Gradient Descent or the Architecture: Disentangling the Effects of Overparameterization of Neural Networks
Amit Peleg, Matthias Hein
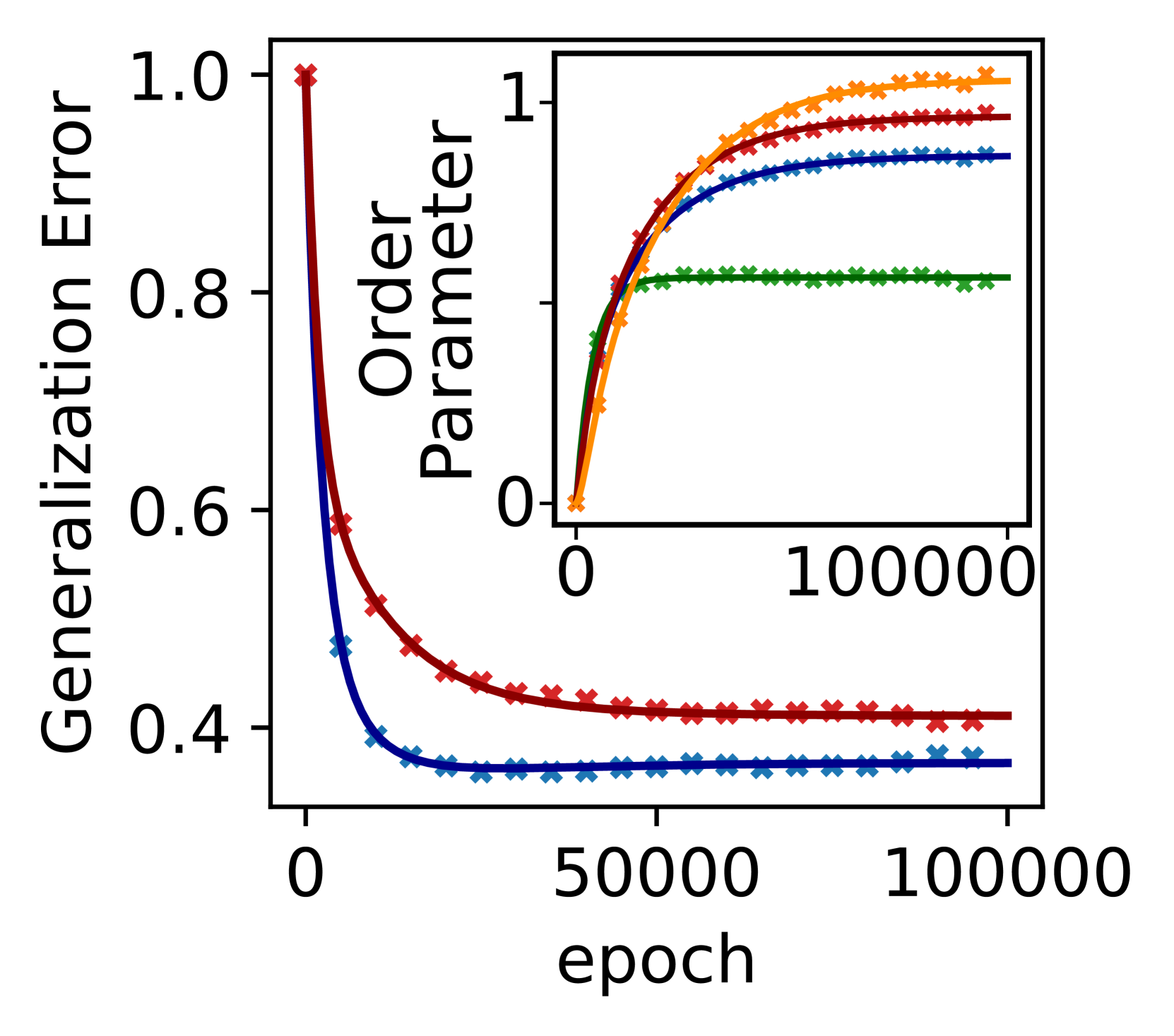
Neural networks typically generalize well when fitting the data perfectly, even though they are heavily overparameterized. Many factors have been pointed out as the reason for this phenomenon, including an implicit bias of stochastic gradient descent (SGD) and a possible simplicity bias arising from the neural network architecture. The goal of this paper is to disentangle the factors that influence generalization stemming from optimization and architectural choices by studying random and SGD-optimized networks that achieve zero training error. We experimentally show, in the low sample regime, that overparameterization in terms of increasing width is beneficial for generalization, and this benefit is due to the bias of SGD and not due to an architectural bias. In contrast, for increasing depth, overparameterization is detrimental for generalization, but random and SGD-optimized networks behave similarly, so this can be attributed to an architectural bias. For more information, see https://bias-sgd-or-architecture.github.io .
Read more7/8/2024
🔗
0
Stochastic Collapse: How Gradient Noise Attracts SGD Dynamics Towards Simpler Subnetworks
Feng Chen, Daniel Kunin, Atsushi Yamamura, Surya Ganguli
In this work, we reveal a strong implicit bias of stochastic gradient descent (SGD) that drives overly expressive networks to much simpler subnetworks, thereby dramatically reducing the number of independent parameters, and improving generalization. To reveal this bias, we identify invariant sets, or subsets of parameter space that remain unmodified by SGD. We focus on two classes of invariant sets that correspond to simpler (sparse or low-rank) subnetworks and commonly appear in modern architectures. Our analysis uncovers that SGD exhibits a property of stochastic attractivity towards these simpler invariant sets. We establish a sufficient condition for stochastic attractivity based on a competition between the loss landscape's curvature around the invariant set and the noise introduced by stochastic gradients. Remarkably, we find that an increased level of noise strengthens attractivity, leading to the emergence of attractive invariant sets associated with saddle-points or local maxima of the train loss. We observe empirically the existence of attractive invariant sets in trained deep neural networks, implying that SGD dynamics often collapses to simple subnetworks with either vanishing or redundant neurons. We further demonstrate how this simplifying process of stochastic collapse benefits generalization in a linear teacher-student framework. Finally, through this analysis, we mechanistically explain why early training with large learning rates for extended periods benefits subsequent generalization.
Read more5/30/2024
0
Bias in Motion: Theoretical Insights into the Dynamics of Bias in SGD Training
Anchit Jain, Rozhin Nobahari, Aristide Baratin, Stefano Sarao Mannelli
Machine learning systems often acquire biases by leveraging undesired features in the data, impacting accuracy variably across different sub-populations. Current understanding of bias formation mostly focuses on the initial and final stages of learning, leaving a gap in knowledge regarding the transient dynamics. To address this gap, this paper explores the evolution of bias in a teacher-student setup modeling different data sub-populations with a Gaussian-mixture model. We provide an analytical description of the stochastic gradient descent dynamics of a linear classifier in this setting, which we prove to be exact in high dimension. Notably, our analysis reveals how different properties of sub-populations influence bias at different timescales, showing a shifting preference of the classifier during training. Applying our findings to fairness and robustness, we delineate how and when heterogeneous data and spurious features can generate and amplify bias. We empirically validate our results in more complex scenarios by training deeper networks on synthetic and real datasets, including CIFAR10, MNIST, and CelebA.
Read more5/29/2024

0
How Uniform Random Weights Induce Non-uniform Bias: Typical Interpolating Neural Networks Generalize with Narrow Teachers
Gon Buzaglo, Itamar Harel, Mor Shpigel Nacson, Alon Brutzkus, Nathan Srebro, Daniel Soudry
Background. A main theoretical puzzle is why over-parameterized Neural Networks (NNs) generalize well when trained to zero loss (i.e., so they interpolate the data). Usually, the NN is trained with Stochastic Gradient Descent (SGD) or one of its variants. However, recent empirical work examined the generalization of a random NN that interpolates the data: the NN was sampled from a seemingly uniform prior over the parameters, conditioned on that the NN perfectly classifies the training set. Interestingly, such a NN sample typically generalized as well as SGD-trained NNs. Contributions. We prove that such a random NN interpolator typically generalizes well if there exists an underlying narrow ``teacher NN'' that agrees with the labels. Specifically, we show that such a `flat' prior over the NN parameterization induces a rich prior over the NN functions, due to the redundancy in the NN structure. In particular, this creates a bias towards simpler functions, which require less relevant parameters to represent -- enabling learning with a sample complexity approximately proportional to the complexity of the teacher (roughly, the number of non-redundant parameters), rather than the student's.
Read more6/11/2024