BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains

0

Sign in to get full access
Overview
- BioMistral is a collection of open-source, pre-trained large language models for medical domains.
- The models are trained on a diverse set of medical literature and can be used for various natural language processing tasks in the healthcare and biomedical fields.
- The paper introduces the BioMistral models, provides details on their training, and presents the results of benchmark evaluations.
Plain English Explanation
BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains is a research project that has developed a set of powerful language models specifically designed for medical and healthcare applications. These models, known as BioMistral, have been trained on a vast amount of medical literature, including scientific papers, clinical notes, and other relevant texts.
The key advantage of the BioMistral models is their ability to understand and generate human-like text within the medical domain. This can be extremely useful for a wide range of tasks, such as summarizing medical research papers, translating medical documents into different languages, and even engaging in medical conversations with patients.
By making these models openly available to the research community and healthcare professionals, the authors hope to accelerate the development of innovative applications that can improve patient outcomes, streamline clinical workflows, and advance medical research.
Technical Explanation
The BioMistral models are based on the popular Transformer architecture, which has proven to be highly effective for a wide range of natural language processing tasks. The models were trained on a diverse corpus of medical literature, including scientific papers, clinical notes, and other relevant texts from various sources.
The training process involved several steps, including data collection, preprocessing, and fine-tuning. The authors used advanced techniques, such as multilingual language modeling and transfer learning, to enhance the models' performance and versatility.
To evaluate the BioMistral models, the researchers conducted a series of benchmark tests, examining their performance on tasks such as medical text summarization, medical question answering, and medical named entity recognition. The results demonstrate the models' strong capabilities in understanding and generating medical-related text, outperforming several existing state-of-the-art models.
Critical Analysis
The BioMistral models represent a significant step forward in the development of large language models for the medical and healthcare domains. However, as with any research, there are some limitations and areas for further exploration.
One potential concern is the diversity and representativeness of the training data. While the authors have made efforts to include a wide range of medical literature, there may be biases or gaps in the data that could affect the models' performance on certain tasks or in specific medical specialties.
Additionally, the ethical and privacy implications of using large language models in healthcare settings must be carefully considered. The models may inadvertently learn and reproduce biases or sensitive information, which could raise concerns about patient confidentiality and equitable access to healthcare services.
Further research is needed to address these issues, as well as to explore the potential applications of the BioMistral models in real-world healthcare settings. Collaboration between researchers, clinicians, and policymakers will be crucial to ensure that these powerful tools are developed and deployed responsibly and ethically.
Conclusion
The BioMistral models represent a significant advancement in the field of medical natural language processing. By providing open-source, pre-trained models that can be fine-tuned for a variety of healthcare-related tasks, the researchers have laid the groundwork for the development of innovative applications that can improve patient outcomes, streamline clinical workflows, and accelerate medical research.
As the use of large language models in the healthcare sector continues to grow, it will be important to address the ethical and privacy concerns associated with these technologies. However, the potential benefits of the BioMistral models, including their ability to understand and generate human-like medical text, make them a promising tool for transforming the way we approach healthcare challenges in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
Yanis Labrak, Adrien Bazoge, Emmanuel Morin, Pierre-Antoine Gourraud, Mickael Rouvier, Richard Dufour
Large Language Models (LLMs) have demonstrated remarkable versatility in recent years, offering potential applications across specialized domains such as healthcare and medicine. Despite the availability of various open-source LLMs tailored for health contexts, adapting general-purpose LLMs to the medical domain presents significant challenges. In this paper, we introduce BioMistral, an open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central. We conduct a comprehensive evaluation of BioMistral on a benchmark comprising 10 established medical question-answering (QA) tasks in English. We also explore lightweight models obtained through quantization and model merging approaches. Our results demonstrate BioMistral's superior performance compared to existing open-source medical models and its competitive edge against proprietary counterparts. Finally, to address the limited availability of data beyond English and to assess the multilingual generalization of medical LLMs, we automatically translated and evaluated this benchmark into 7 other languages. This marks the first large-scale multilingual evaluation of LLMs in the medical domain. Datasets, multilingual evaluation benchmarks, scripts, and all the models obtained during our experiments are freely released.
Read more7/18/2024
0
Towards Building Multilingual Language Model for Medicine
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, Weidi Xie
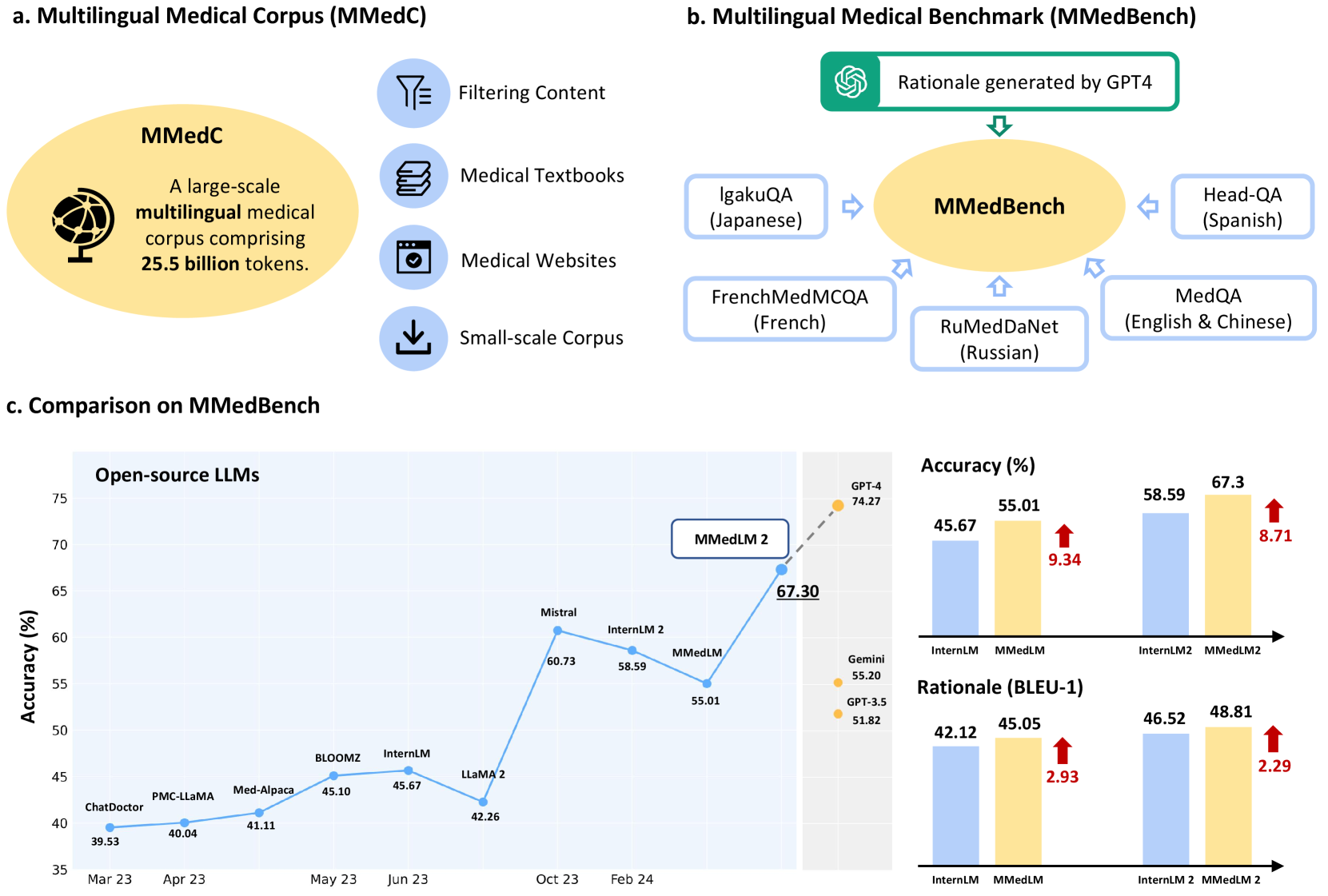
The development of open-source, multilingual medical language models can benefit a wide, linguistically diverse audience from different regions. To promote this domain, we present contributions from the following: First, we construct a multilingual medical corpus, containing approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, enabling auto-regressive domain adaptation for general LLMs; Second, to monitor the development of multilingual medical LLMs, we propose a multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; Third, we have assessed a number of open-source large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC. Our final model, MMed-Llama 3, with only 8B parameters, achieves superior performance compared to all other open-source models on both MMedBench and English benchmarks, even rivaling GPT-4. In conclusion, in this work, we present a large-scale corpus, a benchmark and a series of models to support the development of multilingual medical LLMs.
Read more6/4/2024
📈
0
Lisbon Computational Linguists at SemEval-2024 Task 2: Using A Mistral 7B Model and Data Augmentation
Artur Guimar~aes, Bruno Martins, Jo~ao Magalh~aes
This paper describes our approach to the SemEval-2024 safe biomedical Natural Language Inference for Clinical Trials (NLI4CT) task, which concerns classifying statements about Clinical Trial Reports (CTRs). We explored the capabilities of Mistral-7B, a generalist open-source Large Language Model (LLM). We developed a prompt for the NLI4CT task, and fine-tuned a quantized version of the model using an augmented version of the training dataset. The experimental results show that this approach can produce notable results in terms of the macro F1-score, while having limitations in terms of faithfulness and consistency. All the developed code is publicly available on a GitHub repository
Read more8/7/2024
0
Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
Iker Garc'ia-Ferrero, Rodrigo Agerri, Aitziber Atutxa Salazar, Elena Cabrio, Iker de la Iglesia, Alberto Lavelli, Bernardo Magnini, Benjamin Molinet, Johana Ramirez-Romero, German Rigau, Jose Maria Villa-Gonzalez, Serena Villata, Andrea Zaninello
Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
Read more4/12/2024