MedDoc-Bot: A Chat Tool for Comparative Analysis of Large Language Models in the Context of the Pediatric Hypertension Guideline

0
💬
Sign in to get full access
Overview
- This research evaluates the performance of four open-source large language models (LLMs) - Meditron, MedAlpaca, Mistral, and Llama-2 - in interpreting medical guidelines saved in PDF format.
- The specific test scenario involves applying these models to the hypertension guidelines for children and adolescents provided by the European Society of Cardiology (ESC).
- The researchers developed a user-friendly medical document chatbot tool (MedDoc-Bot) using Streamlit, a Python library, to enable authorized users to upload PDF files and pose questions, with the LLMs generating interpretive responses.
- A pediatric expert provides a benchmark for evaluation by formulating questions and responses extracted from the ESC guidelines, and rates the model-generated responses based on their fidelity and relevance.
- The study also evaluates the METEOR and chrF metric scores to assess the similarity of model responses to reference answers.
Plain English Explanation
The researchers wanted to see how well a few different open-source large language models could interpret medical guidelines that are stored as PDF documents. They focused on guidelines for treating high blood pressure in children and teenagers, which were provided by the European Society of Cardiology.
To test this, the researchers created a user-friendly chatbot tool that lets people upload PDF files and ask questions. The chatbot then uses four different language models - Meditron, MedAlpaca, Mistral, and Llama-2 - to try to provide relevant answers.
A medical expert reviewed the guidelines and provided benchmark questions and answers. The expert then evaluated the responses generated by the language models to see how well they matched the expert's own understanding of the guidelines.
The researchers also used some automated metrics to compare the model responses to the expert's answers and see how similar they were. The results showed that the Llama-2 and Mistral models performed the best on these metrics.
However, the Llama-2 model was a bit slower when dealing with text and tabular data from the guidelines. In the human evaluation, the responses from Mistral, Meditron, and Llama-2 were generally rated as reasonably accurate and relevant.
This study provides helpful insights into the strengths and limitations of these open-source large language models when it comes to interpreting medical guidelines. This could inform future work on developing better AI tools for working with medical documents.
Technical Explanation
The researchers evaluated the performance of four open-source large language models - Meditron, MedAlpaca, Mistral, and Llama-2 - in interpreting medical guidelines stored in PDF format.
They focused on the hypertension guidelines for children and adolescents provided by the European Society of Cardiology (ESC) as a specific test case. Using the Streamlit Python library, the researchers developed a user-friendly medical document chatbot tool (MedDoc-Bot) that allows authorized users to upload PDF files and pose questions, with the LLMs generating interpretive responses.
A pediatric expert formulated relevant questions and provided benchmark responses extracted directly from the ESC guidelines. The expert then rated the model-generated responses based on their fidelity and relevance to the guidelines. Additionally, the researchers evaluated the METEOR and chrF metric scores to assess the similarity between the model responses and the expert's reference answers.
The results showed that the Llama-2 and Mistral models performed well on the automated metric evaluations. However, Llama-2 was slower when dealing with text and tabular data from the guidelines. In the human evaluation, the responses generated by Mistral, Meditron, and Llama-2 were found to exhibit reasonable fidelity and relevance to the guidelines.
Critical Analysis
The paper provides a useful, comparative analysis of the performance of several open-source LLMs in the specific context of interpreting medical guidelines. However, it is important to note some potential limitations and areas for further research:
-
The study focused on a single set of guidelines (ESC hypertension guidelines for children and adolescents), which may limit the generalizability of the findings to other medical domains and document types.
-
The human evaluation relied on a single expert's assessment, which could introduce individual biases. Expanding the pool of expert raters could help validate the findings.
-
The study did not explore the ability of the LLMs to handle more complex reasoning, such as drawing inferences or reconciling conflicting information within the guidelines.
-
The researchers did not investigate the models' performance on tasks like summarization, extraction of key recommendations, or generation of new guidelines-based content, which could be valuable for practical applications.
-
The study did not address potential issues related to the privacy and security of sensitive medical information when using these LLMs, which would be an important consideration for real-world deployment.
Overall, this research provides a solid foundation for adapting open-source large language models to medical document interpretation, but further work is needed to fully understand the capabilities and limitations of these models in healthcare applications.
Conclusion
This study evaluates the performance of four open-source large language models - Meditron, MedAlpaca, Mistral, and Llama-2 - in interpreting medical guidelines stored in PDF format, using the European Society of Cardiology's hypertension guidelines for children and adolescents as a test case.
The researchers developed a user-friendly medical document chatbot tool (MedDoc-Bot) to enable authorized users to upload PDF files and pose questions, with the LLMs generating interpretive responses. A pediatric expert provided a benchmark for evaluation, and the researchers also assessed the models using automated METEOR and chrF metric scores.
The results indicate that the Llama-2 and Mistral models performed well on the metric evaluations, though Llama-2 was slower with text and tabular data. In the human evaluation, the responses from Mistral, Meditron, and Llama-2 were rated as reasonably accurate and relevant.
This study offers valuable insights into the strengths and limitations of these open-source large language models for medical document interpretation, which can inform future developments in this area. Continued research on adapting LLMs to medical text-to-text tasks and addressing privacy/security concerns could further advance the use of AI in healthcare settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
MedDoc-Bot: A Chat Tool for Comparative Analysis of Large Language Models in the Context of the Pediatric Hypertension Guideline
Mohamed Yaseen Jabarulla, Steffen Oeltze-Jafra, Philipp Beerbaum, Theodor Uden
This research focuses on evaluating the non-commercial open-source large language models (LLMs) Meditron, MedAlpaca, Mistral, and Llama-2 for their efficacy in interpreting medical guidelines saved in PDF format. As a specific test scenario, we applied these models to the guidelines for hypertension in children and adolescents provided by the European Society of Cardiology (ESC). Leveraging Streamlit, a Python library, we developed a user-friendly medical document chatbot tool (MedDoc-Bot). This tool enables authorized users to upload PDF files and pose questions, generating interpretive responses from four locally stored LLMs. A pediatric expert provides a benchmark for evaluation by formulating questions and responses extracted from the ESC guidelines. The expert rates the model-generated responses based on their fidelity and relevance. Additionally, we evaluated the METEOR and chrF metric scores to assess the similarity of model responses to reference answers. Our study found that Llama-2 and Mistral performed well in metrics evaluation. However, Llama-2 was slower when dealing with text and tabular data. In our human evaluation, we observed that responses created by Mistral, Meditron, and Llama-2 exhibited reasonable fidelity and relevance. This study provides valuable insights into the strengths and limitations of LLMs for future developments in medical document interpretation. Open-Source Code: https://github.com/yaseen28/MedDoc-Bot
Read more5/7/2024
0
Can LLMs Correct Physicians, Yet? Investigating Effective Interaction Methods in the Medical Domain
Burcu Sayin, Pasquale Minervini, Jacopo Staiano, Andrea Passerini
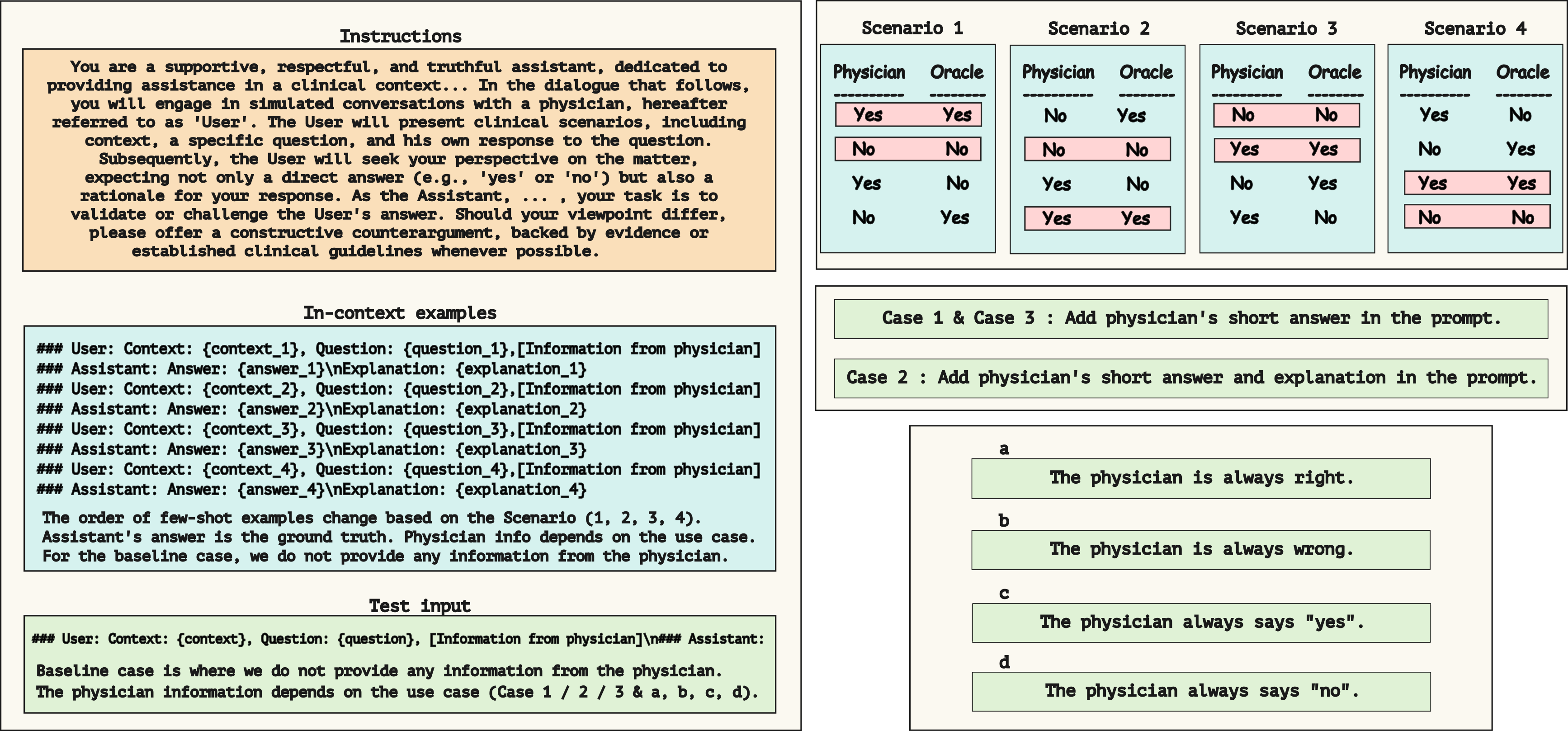
We explore the potential of Large Language Models (LLMs) to assist and potentially correct physicians in medical decision-making tasks. We evaluate several LLMs, including Meditron, Llama2, and Mistral, to analyze the ability of these models to interact effectively with physicians across different scenarios. We consider questions from PubMedQA and several tasks, ranging from binary (yes/no) responses to long answer generation, where the answer of the model is produced after an interaction with a physician. Our findings suggest that prompt design significantly influences the downstream accuracy of LLMs and that LLMs can provide valuable feedback to physicians, challenging incorrect diagnoses and contributing to more accurate decision-making. For example, when the physician is accurate 38% of the time, Mistral can produce the correct answer, improving accuracy up to 74% depending on the prompt being used, while Llama2 and Meditron models exhibit greater sensitivity to prompt choice. Our analysis also uncovers the challenges of ensuring that LLM-generated suggestions are pertinent and useful, emphasizing the need for further research in this area.
Read more5/7/2024
💬
0
Comparative Analysis of Open-Source Language Models in Summarizing Medical Text Data
Yuhao Chen, Zhimu Wang, Bo Wen, Farhana Zulkernine
Unstructured text in medical notes and dialogues contains rich information. Recent advancements in Large Language Models (LLMs) have demonstrated superior performance in question answering and summarization tasks on unstructured text data, outperforming traditional text analysis approaches. However, there is a lack of scientific studies in the literature that methodically evaluate and report on the performance of different LLMs, specifically for domain-specific data such as medical chart notes. We propose an evaluation approach to analyze the performance of open-source LLMs such as Llama2 and Mistral for medical summarization tasks, using GPT-4 as an assessor. Our innovative approach to quantitative evaluation of LLMs can enable quality control, support the selection of effective LLMs for specific tasks, and advance knowledge discovery in digital health.
Read more5/31/2024
🚀
0
Performance Evaluation of Lightweight Open-source Large Language Models in Pediatric Consultations: A Comparative Analysis
Qiuhong Wei, Ying Cui, Mengwei Ding, Yanqin Wang, Lingling Xiang, Zhengxiong Yao, Ceran Chen, Ying Long, Zhezhen Jin, Ximing Xu
Large language models (LLMs) have demonstrated potential applications in medicine, yet data privacy and computational burden limit their deployment in healthcare institutions. Open-source and lightweight versions of LLMs emerge as potential solutions, but their performance, particularly in pediatric settings remains underexplored. In this cross-sectional study, 250 patient consultation questions were randomly selected from a public online medical forum, with 10 questions from each of 25 pediatric departments, spanning from December 1, 2022, to October 30, 2023. Two lightweight open-source LLMs, ChatGLM3-6B and Vicuna-7B, along with a larger-scale model, Vicuna-13B, and the widely-used proprietary ChatGPT-3.5, independently answered these questions in Chinese between November 1, 2023, and November 7, 2023. To assess reproducibility, each inquiry was replicated once. We found that ChatGLM3-6B demonstrated higher accuracy and completeness than Vicuna-13B and Vicuna-7B (P .05), with over 98.4% of responses being rated as safe. Repetition of inquiries confirmed these findings. In conclusion, Lightweight LLMs demonstrate promising application in pediatric healthcare. However, the observed gap between lightweight and large-scale proprietary LLMs underscores the need for continued development efforts.
Read more7/24/2024