BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages

0

Sign in to get full access
Overview
- This paper introduces BLEnD, a new benchmark for evaluating large language models (LLMs) on their knowledge of everyday information across diverse cultures and languages.
- The benchmark covers a wide range of topics, including cultural values, traditions, and norms, social etiquette and communication styles, and current events and popular culture.
- The goal is to assess how well LLMs can understand and reason about the nuances of human knowledge and behaviors in a global context, going beyond traditional benchmarks focused on specific tasks or datasets.
Plain English Explanation
The paper presents a new way to evaluate large language models (LLMs), which are AI systems that can understand and generate human-like text. The authors created a benchmark called BLEnD that tests how well these models can handle everyday knowledge and information across diverse cultures and languages.
The benchmark covers a wide range of topics, from cultural values and traditions to social etiquette and current events. The idea is to see how well LLMs can understand the nuances and complexities of human knowledge and behavior in a global context, rather than just focusing on specific tasks or datasets.
For example, the benchmark might test how well an LLM can explain a cultural tradition from a country it hasn't been trained on, or how it responds to a social situation involving different communication styles. The goal is to go beyond traditional benchmarks and get a more comprehensive understanding of how these powerful AI systems perform in real-world, cross-cultural scenarios.
Technical Explanation
The BLEnD benchmark is designed to evaluate the performance of large language models (LLMs) on a diverse range of everyday knowledge across cultures and languages. It covers topics such as cultural values and norms, social etiquette and communication styles, and current events and popular culture.
The benchmark includes a wide variety of question types, such as multiple-choice, open-ended, and task-oriented prompts, to assess different aspects of the LLMs' capabilities. The authors also include user-centric evaluations to understand how the models perform in more realistic, interactive scenarios.
To ensure the benchmark is challenging and representative of real-world knowledge, the authors carefully curate the content and address potential data contamination issues that could skew the results.
Critical Analysis
The BLEnD benchmark represents a significant advancement in the evaluation of large language models, as it moves beyond traditional benchmarks focused on specific tasks or datasets. By testing LLMs on a diverse range of everyday knowledge across cultures and languages, the authors aim to provide a more comprehensive assessment of their capabilities.
However, the authors acknowledge that the benchmark is not without its limitations. For example, the content curation process and the potential for data contamination could still introduce biases or blind spots in the evaluation. Additionally, the user-centric evaluations, while valuable, may be more challenging to scale and standardize.
Furthermore, the authors note that the benchmark is primarily focused on assessing the models' knowledge and reasoning abilities, and does not directly evaluate their real-world performance in terms of safety, ethics, or societal impact. These are important considerations that should be addressed in future research.
Conclusion
The BLEnD benchmark represents a valuable contribution to the field of large language model evaluation. By testing these powerful AI systems on a diverse range of everyday knowledge and cross-cultural scenarios, the authors aim to provide a more holistic understanding of their capabilities and limitations.
The insights gained from the BLEnD benchmark could have significant implications for the development and deployment of LLMs, as they can help identify areas where these models excel or struggle, and inform the design of more robust and culturally-aware AI systems. As the field of language AI continues to evolve, benchmarks like BLEnD will become increasingly important in shaping the future of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages
Junho Myung, Nayeon Lee, Yi Zhou, Jiho Jin, Rifki Afina Putri, Dimosthenis Antypas, Hsuvas Borkakoty, Eunsu Kim, Carla Perez-Almendros, Abinew Ali Ayele, V'ictor Guti'errez-Basulto, Yazm'in Ib'a~nez-Garc'ia, Hwaran Lee, Shamsuddeen Hassan Muhammad, Kiwoong Park, Anar Sabuhi Rzayev, Nina White, Seid Muhie Yimam, Mohammad Taher Pilehvar, Nedjma Ousidhoum, Jose Camacho-Collados, Alice Oh
Large language models (LLMs) often lack culture-specific knowledge of daily life, especially across diverse regions and non-English languages. Existing benchmarks for evaluating LLMs' cultural sensitivities are limited to a single language or collected from online sources such as Wikipedia, which do not reflect the mundane everyday lifestyles of diverse regions. That is, information about the food people eat for their birthday celebrations, spices they typically use, musical instruments youngsters play, or the sports they practice in school is common cultural knowledge but uncommon in easily collected online sources, especially for underrepresented cultures. To address this issue, we introduce BLEnD, a hand-crafted benchmark designed to evaluate LLMs' everyday knowledge across diverse cultures and languages. BLEnD comprises 52.6k question-answer pairs from 16 countries/regions, in 13 different languages, including low-resource ones such as Amharic, Assamese, Azerbaijani, Hausa, and Sundanese. We construct the benchmark to include two formats of questions: short-answer and multiple-choice. We show that LLMs perform better for cultures that are highly represented online, with a maximum 57.34% difference in GPT-4, the best-performing model, in the short-answer format. For cultures represented by mid-to-high-resource languages, LLMs perform better in their local languages, but for cultures represented by low-resource languages, LLMs perform better in English than the local languages. We make our dataset publicly available at: https://github.com/nlee0212/BLEnD.
Read more6/17/2024
💬
0
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jifan Yu, Xiaozhi Wang, Shangqing Tu, Shulin Cao, Daniel Zhang-Li, Xin Lv, Hao Peng, Zijun Yao, Xiaohan Zhang, Hanming Li, Chunyang Li, Zheyuan Zhang, Yushi Bai, Yantao Liu, Amy Xin, Nianyi Lin, Kaifeng Yun, Linlu Gong, Jianhui Chen, Zhili Wu, Yunjia Qi, Weikai Li, Yong Guan, Kaisheng Zeng, Ji Qi, Hailong Jin, Jinxin Liu, Yu Gu, Yuan Yao, Ning Ding, Lei Hou, Zhiyuan Liu, Bin Xu, Jie Tang, Juanzi Li
The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For textbf{ability modeling}, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For textbf{data}, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For textbf{evaluation criteria}, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge-creating ability. We evaluate $28$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.
Read more7/2/2024
💬
0
WorldValuesBench: A Large-Scale Benchmark Dataset for Multi-Cultural Value Awareness of Language Models
Wenlong Zhao, Debanjan Mondal, Niket Tandon, Danica Dillion, Kurt Gray, Yuling Gu
The awareness of multi-cultural human values is critical to the ability of language models (LMs) to generate safe and personalized responses. However, this awareness of LMs has been insufficiently studied, since the computer science community lacks access to the large-scale real-world data about multi-cultural values. In this paper, we present WorldValuesBench, a globally diverse, large-scale benchmark dataset for the multi-cultural value prediction task, which requires a model to generate a rating response to a value question based on demographic contexts. Our dataset is derived from an influential social science project, World Values Survey (WVS), that has collected answers to hundreds of value questions (e.g., social, economic, ethical) from 94,728 participants worldwide. We have constructed more than 20 million examples of the type (demographic attributes, value question) $rightarrow$ answer from the WVS responses. We perform a case study using our dataset and show that the task is challenging for strong open and closed-source models. On merely $11.1%$, $25.0%$, $72.2%$, and $75.0%$ of the questions, Alpaca-7B, Vicuna-7B-v1.5, Mixtral-8x7B-Instruct-v0.1, and GPT-3.5 Turbo can respectively achieve $<0.2$ Wasserstein 1-distance from the human normalized answer distributions. WorldValuesBench opens up new research avenues in studying limitations and opportunities in multi-cultural value awareness of LMs.
Read more4/26/2024
0
Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
Millicent Ochieng, Varun Gumma, Sunayana Sitaram, Jindong Wang, Vishrav Chaudhary, Keshet Ronen, Kalika Bali, Jacki O'Neill
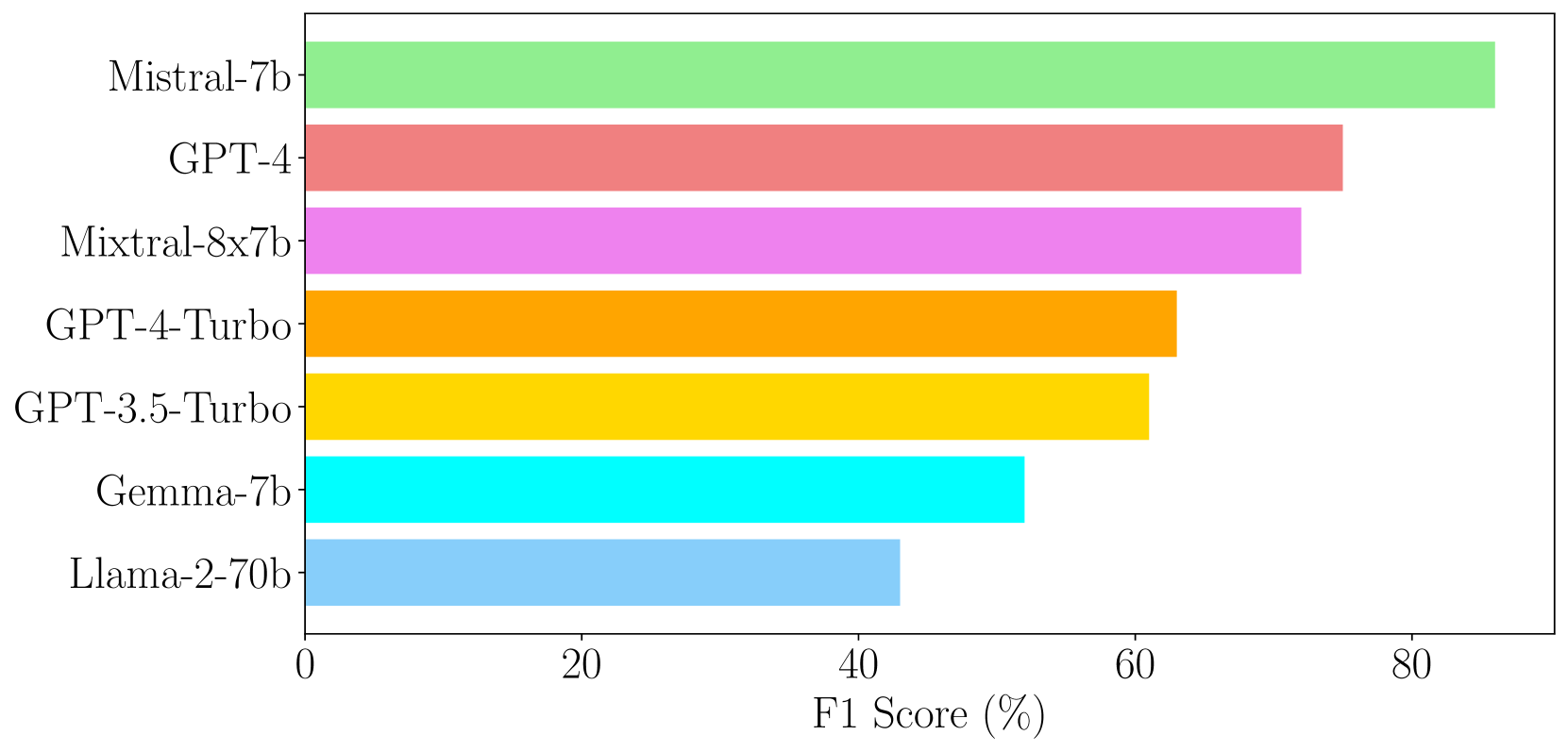
The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings and the need for developing evaluation benchmarks for capturing these issues.
Read more6/14/2024