clembench-2024: A Challenging, Dynamic, Complementary, Multilingual Benchmark and Underlying Flexible Framework for LLMs as Multi-Action Agents
2405.20859
0
0

Abstract
It has been established in recent work that Large Language Models (LLMs) can be prompted to self-play conversational games that probe certain capabilities (general instruction following, strategic goal orientation, language understanding abilities), where the resulting interactive game play can be automatically scored. In this paper, we take one of the proposed frameworks for setting up such game-play environments, and further test its usefulness as an evaluation instrument, along a number of dimensions: We show that it can easily keep up with new developments while avoiding data contamination, we show that the tests implemented within it are not yet saturated (human performance is substantially higher than that of even the best models), and we show that it lends itself to investigating additional questions, such as the impact of the prompting language on performance. We believe that the approach forms a good basis for making decisions on model choice for building applied interactive systems, and perhaps ultimately setting up a closed-loop development environment of system and simulated evaluator.
Create account to get full access
Overview
- Introduces a new benchmark called
clembench2024for evaluating large language models (LLMs) as multi-action agents - Designed to be challenging, dynamic, complementary, and multilingual
- Provides a flexible framework for testing LLM capabilities across a variety of dialogue games and tasks
Plain English Explanation
This paper presents a new benchmark called clembench2024 that is designed to thoroughly test the abilities of large language models (LLMs) as multi-action agents. Unlike traditional benchmarks that focus on a single task or domain, clembench2024 is meant to be challenging, dynamic, complementary, and multilingual.
The underlying framework allows for a wide variety of dialogue games and agent capabilities to be evaluated. This ensures that the benchmarks cover a diverse set of skills that are necessary for LLMs to engage in meaningful, human-like conversations and interactions. The goal is to push the boundaries of what current LLMs are capable of and identify areas where further research and development is needed.
By creating a more comprehensive and demanding set of tests, the researchers hope to drive progress in building LLMs that can truly collaborate with humans as partners, rather than just providing scripted or narrow responses. The flexibility of the clembench2024 framework also allows it to be adapted and expanded over time as the field of conversational AI continues to evolve.
Technical Explanation
The clembench2024 benchmark is designed to evaluate LLMs across a range of dialogue games and agent capabilities. These include tasks that require dynamic learning strategies, the ability to engage with human feedback, and the capacity to participate in human-like dialogues.
The flexible framework underlying clembench2024 allows for the definition of diverse scenarios and challenges that LLMs must navigate as autonomous agents. This includes tasks that require multi-modal reasoning, long-term planning, contextual understanding, and the ability to handle open-ended, dynamic interactions.
The benchmarks are designed to be challenging, with a focus on assessing the limitations of current LLM capabilities. The goal is to push the field forward by identifying areas where further research and development is needed to create LLMs that can truly collaborate with humans as partners.
Critical Analysis
The researchers acknowledge that clembench2024 represents a significant challenge for existing LLMs, and that significant advancements will be required to meet the benchmark's demands. Some potential limitations and areas for further research include:
- The need for LLMs to develop more robust and flexible learning strategies to handle the dynamic nature of the benchmark tasks.
- The difficulties in training LLMs to maintain coherent long-term context and memory across extended dialogues.
- The challenges of developing LLMs that can effectively integrate human feedback and corrections into their behavior.
- The complexities of scaling the benchmark to handle a truly diverse range of languages and cultural contexts.
It will be important for the research community to carefully evaluate the performance of LLMs on clembench2024 and use the insights gained to drive further progress in conversational AI. Continued refinement and expansion of the benchmark framework will also be crucial to ensure it remains a relevant and challenging test of LLM capabilities.
Conclusion
The clembench2024 benchmark represents a significant step forward in the evaluation of large language models as multi-action agents. By designing a flexible framework that encompasses a diverse range of dialogue games and agent capabilities, the researchers have created a powerful tool for pushing the boundaries of what current LLMs can do.
The ultimate goal is to accelerate the development of LLMs that can engage in truly collaborative, human-like interactions, rather than simply providing scripted or narrow responses. The insights gained from clembench2024 will be invaluable in guiding future research and development efforts in the field of conversational AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Language Model Council: Benchmarking Foundation Models on Highly Subjective Tasks by Consensus
Justin Zhao, Flor Miriam Plaza-del-Arco, Amanda Cercas Curry
0
0
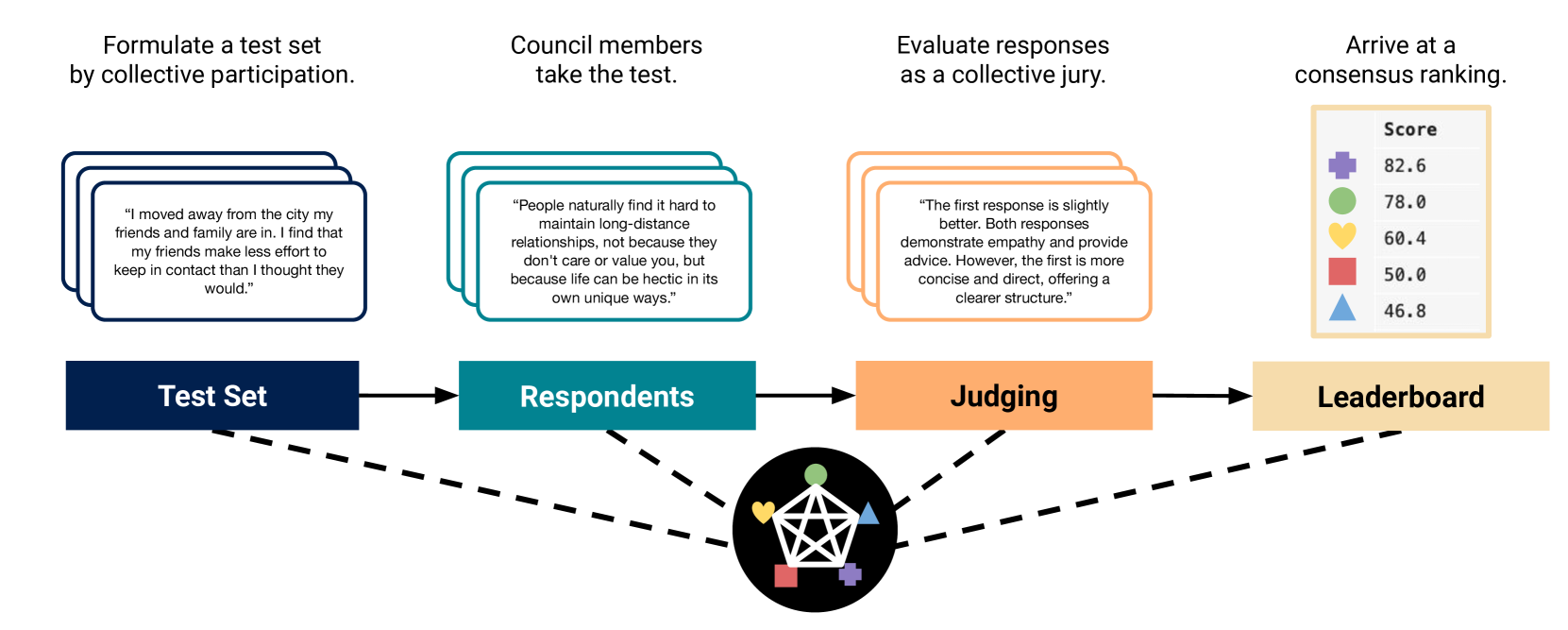
The rapid advancement of Large Language Models (LLMs) necessitates robust and challenging benchmarks. Leaderboards like Chatbot Arena rank LLMs based on how well their responses align with human preferences. However, many tasks such as those related to emotional intelligence, creative writing, or persuasiveness, are highly subjective and often lack majoritarian human agreement. Judges may have irreconcilable disagreements about what constitutes a better response. To address the challenge of ranking LLMs on highly subjective tasks, we propose a novel benchmarking framework, the Language Model Council (LMC). The LMC operates through a democratic process to: 1) formulate a test set through equal participation, 2) administer the test among council members, and 3) evaluate responses as a collective jury. We deploy a council of 20 newest LLMs on an open-ended emotional intelligence task: responding to interpersonal dilemmas. Our results show that the LMC produces rankings that are more separable, robust, and less biased than those from any individual LLM judge, and is more consistent with a human-established leaderboard compared to other benchmarks.
6/14/2024

CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jie Feng, Jun Zhang, Junbo Yan, Xin Zhang, Tianjian Ouyang, Tianhui Liu, Yuwei Du, Siqi Guo, Yong Li
0
0
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench
6/21/2024
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, Xiangliang Zhang
0
0
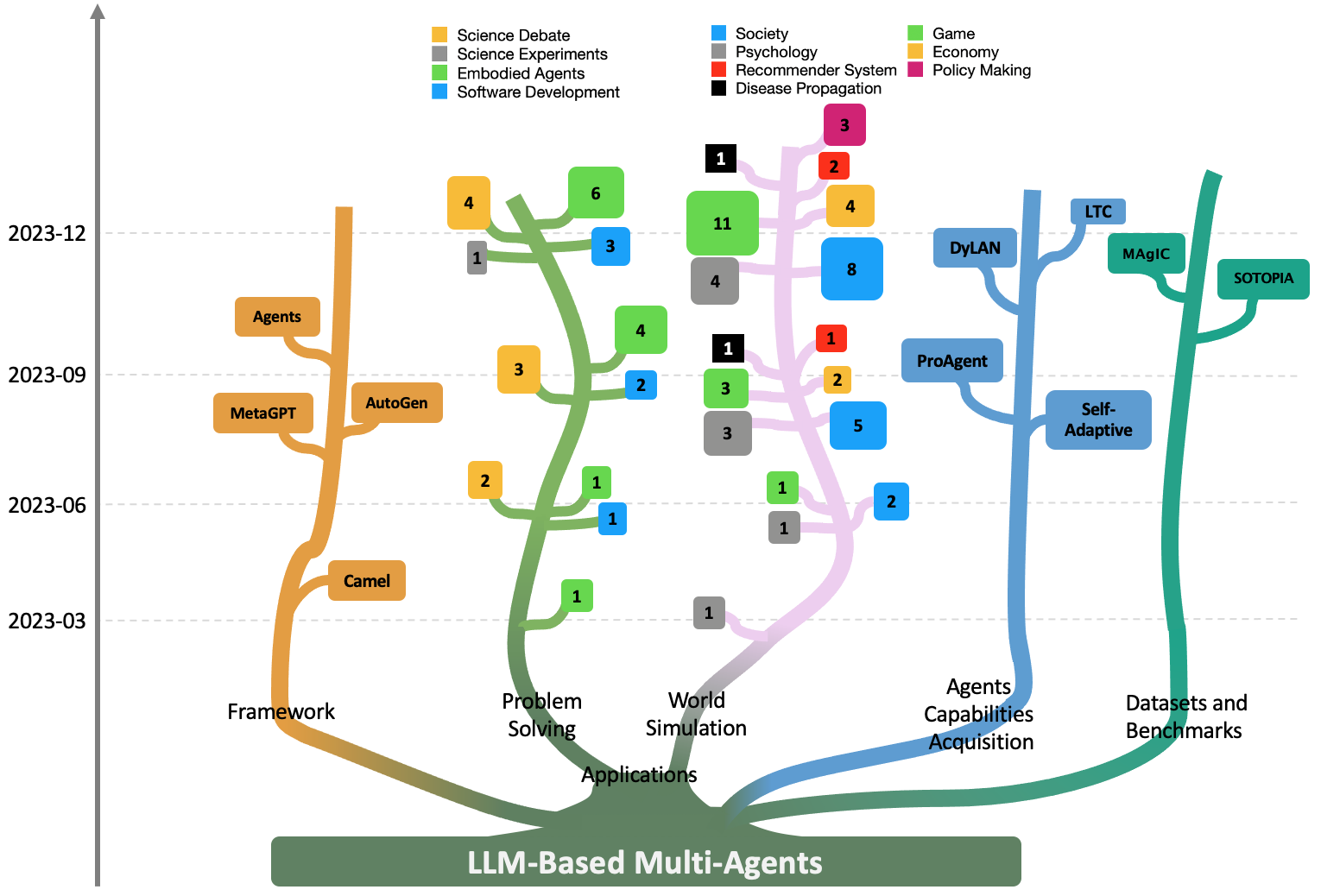
Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents' capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
4/22/2024
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
0
0
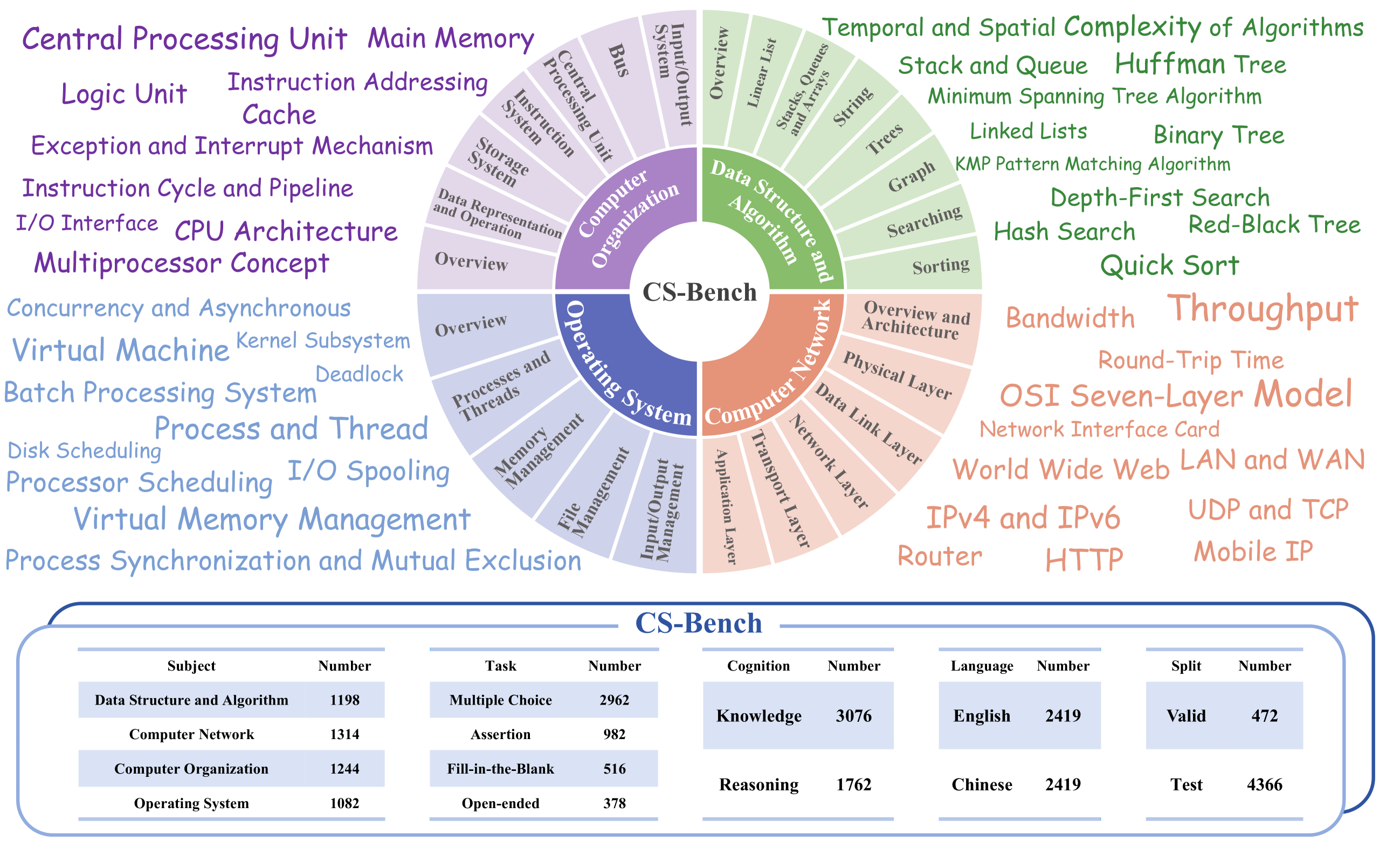
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
6/14/2024