End-to-end Streaming model for Low-Latency Speech Anonymization

0

Sign in to get full access
Overview
- This paper presents an end-to-end streaming model for low-latency speech anonymization.
- The model aims to anonymize speech in real-time while preserving speech quality and intelligibility.
- The authors explore techniques like adversarial perturbation and pseudolabeling to achieve low-latency speech anonymization.
Plain English Explanation
The paper introduces a new system that can anonymize someone's voice in real-time, as they are speaking. This means the system can hide the speaker's identity and make the voice sound different, without a noticeable delay.
The key ideas are:
- Anonymizing speech is important for privacy, but it's challenging to do this quickly without degrading the audio quality or making it hard to understand the speaker.
- The researchers developed a neural network model that can perform this anonymization in an "end-to-end" way, meaning it takes in the original speech and outputs the anonymized version directly.
- To make the anonymization happen quickly, the model uses some special techniques like adversarial perturbation and pseudolabeling.
- The goal is to alter the voice enough to protect the speaker's identity, but not so much that the speech becomes difficult to understand.
Technical Explanation
The paper presents an end-to-end streaming model for low-latency speech anonymization. The model takes raw speech audio as input and outputs anonymized speech in real-time.
Key technical elements include:
- Architecture: The model uses a multi-speaker text-to-speech architecture, with an encoder that learns speaker-specific latent features and a decoder that generates the anonymized speech.
- Adversarial Perturbation: The model leverages adversarial perturbation techniques to introduce small, imperceptible changes to the input speech that obfuscate the speaker's identity.
- Pseudolabeling: The authors use pseudolabeling to train the model on unlabeled speech data, improving its generalization and robustness.
- Real-time Processing: The model is designed for low-latency operation, using techniques like non-autoregressive real-time accent conversion to generate the anonymized speech quickly.
Critical Analysis
The paper tackles an important problem of speech anonymization, but it also acknowledges some limitations and areas for future work:
- The model may not completely hide a speaker's identity, as some speaker-specific characteristics could still be present in the anonymized speech.
- The authors note that further research is needed to improve the speech quality and intelligibility of the anonymized output.
- Extensive user studies would be required to thoroughly evaluate the model's effectiveness and real-world usability.
Additionally, there are some potential concerns that are not addressed in the paper:
- The ethical implications of widespread speech anonymization technology, such as its potential use for deception or evading accountability, should be carefully considered.
- The model's robustness to adversarial attacks or other attempts to compromise the anonymization process is not explored.
Overall, the paper presents a promising step towards low-latency speech anonymization, but there are still important challenges and considerations that merit further investigation.
Conclusion
This paper introduces an end-to-end streaming model for low-latency speech anonymization. The key innovations include the use of adversarial perturbation and pseudolabeling techniques to achieve real-time anonymization while preserving speech quality and intelligibility.
The proposed model represents an important advancement in the field of speech privacy and could have significant implications for applications where the ability to conceal a speaker's identity is crucial. However, the authors acknowledge limitations and areas for further research, and there are additional ethical and technical considerations that warrant careful examination.
Overall, this paper presents a promising step forward in the quest to develop effective and practical speech anonymization solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
End-to-end Streaming model for Low-Latency Speech Anonymization
Waris Quamer, Ricardo Gutierrez-Osuna
Speaker anonymization aims to conceal cues to speaker identity while preserving linguistic content. Current machine learning based approaches require substantial computational resources, hindering real-time streaming applications. To address these concerns, we propose a streaming model that achieves speaker anonymization with low latency. The system is trained in an end-to-end autoencoder fashion using a lightweight content encoder that extracts HuBERT-like information, a pretrained speaker encoder that extract speaker identity, and a variance encoder that injects pitch and energy information. These three disentangled representations are fed to a decoder that resynthesizes the speech signal. We present evaluation results from two implementations of our system, a full model that achieves a latency of 230ms, and a lite version (0.1x in size) that further reduces latency to 66ms while maintaining state-of-the-art performance in naturalness, intelligibility, and privacy preservation.
Read more6/14/2024

0
Probing the Feasibility of Multilingual Speaker Anonymization
Sarina Meyer, Florian Lux, Ngoc Thang Vu
In speaker anonymization, speech recordings are modified in a way that the identity of the speaker remains hidden. While this technology could help to protect the privacy of individuals around the globe, current research restricts this by focusing almost exclusively on English data. In this study, we extend a state-of-the-art anonymization system to nine languages by transforming language-dependent components to their multilingual counterparts. Experiments testing the robustness of the anonymized speech against privacy attacks and speech deterioration show an overall success of this system for all languages. The results suggest that speaker embeddings trained on English data can be applied across languages, and that the anonymization performance for a language is mainly affected by the quality of the speech synthesis component used for it.
Read more7/4/2024
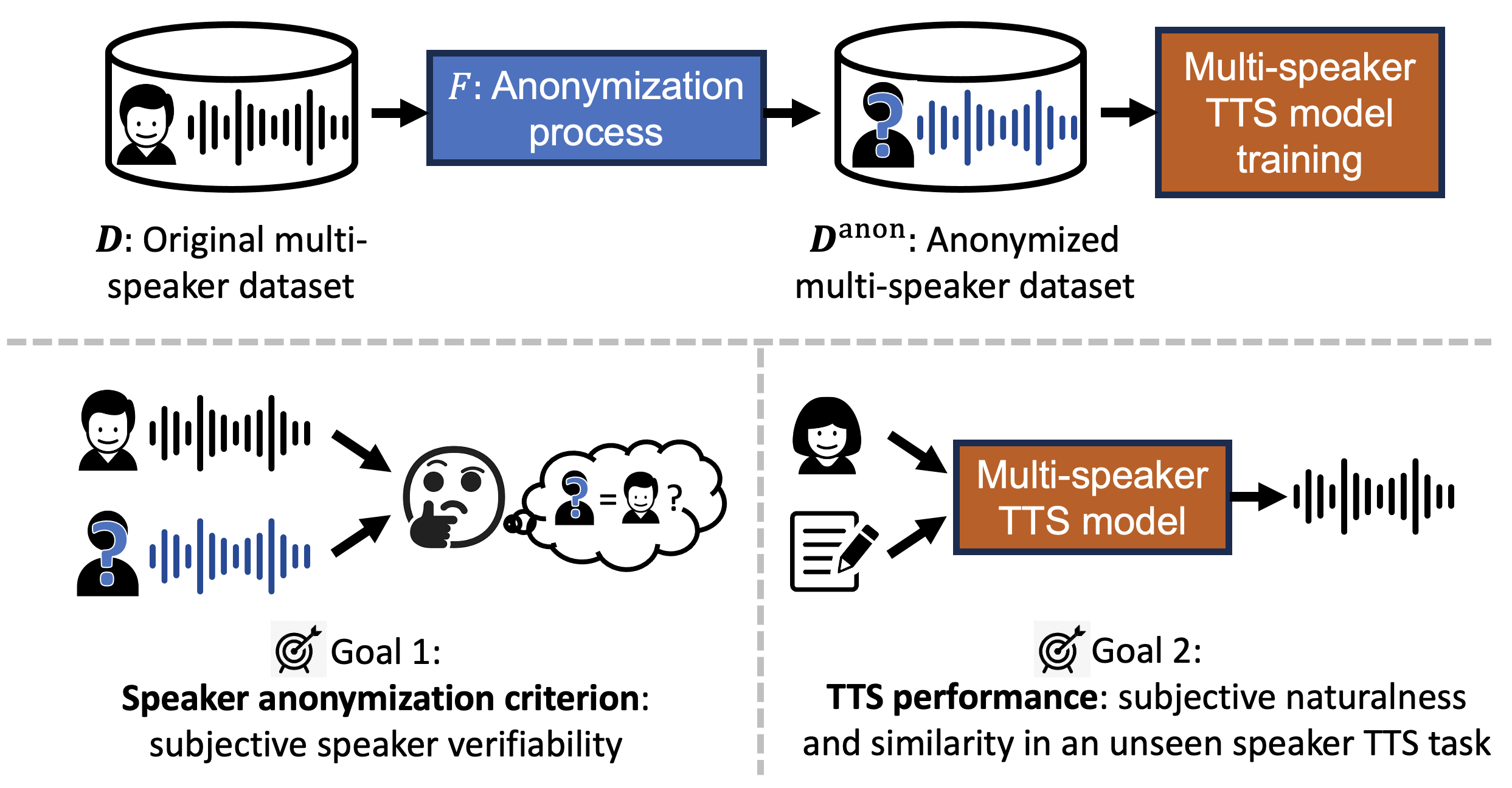
0
Multi-speaker Text-to-speech Training with Speaker Anonymized Data
Wen-Chin Huang, Yi-Chiao Wu, Tomoki Toda
The trend of scaling up speech generation models poses a threat of biometric information leakage of the identities of the voices in the training data, raising privacy and security concerns. In this paper, we investigate training multi-speaker text-to-speech (TTS) models using data that underwent speaker anonymization (SA), a process that tends to hide the speaker identity of the input speech while maintaining other attributes. Two signal processing-based and three deep neural network-based SA methods were used to anonymize VCTK, a multi-speaker TTS dataset, which is further used to train an end-to-end TTS model, VITS, to perform unseen speaker TTS during the testing phase. We conducted extensive objective and subjective experiments to evaluate the anonymized training data, as well as the performance of the downstream TTS model trained using those data. Importantly, we found that UTMOS, a data-driven subjective rating predictor model, and GVD, a metric that measures the gain of voice distinctiveness, are good indicators of the downstream TTS performance. We summarize insights in the hope of helping future researchers determine the goodness of the SA system for multi-speaker TTS training.
Read more5/21/2024
🗣️
0
ELF: Encoding Speaker-Specific Latent Speech Feature for Speech Synthesis
Jungil Kong, Junmo Lee, Jeongmin Kim, Beomjeong Kim, Jihoon Park, Dohee Kong, Changheon Lee, Sangjin Kim
In this work, we propose a novel method for modeling numerous speakers, which enables expressing the overall characteristics of speakers in detail like a trained multi-speaker model without additional training on the target speaker's dataset. Although various works with similar purposes have been actively studied, their performance has not yet reached that of trained multi-speaker models due to their fundamental limitations. To overcome previous limitations, we propose effective methods for feature learning and representing target speakers' speech characteristics by discretizing the features and conditioning them to a speech synthesis model. Our method obtained a significantly higher similarity mean opinion score (SMOS) in subjective similarity evaluation than seen speakers of a high-performance multi-speaker model, even with unseen speakers. The proposed method also outperforms a zero-shot method by significant margins. Furthermore, our method shows remarkable performance in generating new artificial speakers. In addition, we demonstrate that the encoded latent features are sufficiently informative to reconstruct an original speaker's speech completely. It implies that our method can be used as a general methodology to encode and reconstruct speakers' characteristics in various tasks.
Read more6/3/2024