BooookScore: A systematic exploration of book-length summarization in the era of LLMs
2310.00785
2
0
🔎
Abstract
Summarizing book-length documents (>100K tokens) that exceed the context window size of large language models (LLMs) requires first breaking the input document into smaller chunks and then prompting an LLM to merge, update, and compress chunk-level summaries. Despite the complexity and importance of this task, it has yet to be meaningfully studied due to the challenges of evaluation: existing book-length summarization datasets (e.g., BookSum) are in the pretraining data of most public LLMs, and existing evaluation methods struggle to capture errors made by modern LLM summarizers. In this paper, we present the first study of the coherence of LLM-based book-length summarizers implemented via two prompting workflows: (1) hierarchically merging chunk-level summaries, and (2) incrementally updating a running summary. We obtain 1193 fine-grained human annotations on GPT-4 generated summaries of 100 recently-published books and identify eight common types of coherence errors made by LLMs. Because human evaluation is expensive and time-consuming, we develop an automatic metric, BooookScore, that measures the proportion of sentences in a summary that do not contain any of the identified error types. BooookScore has high agreement with human annotations and allows us to systematically evaluate the impact of many other critical parameters (e.g., chunk size, base LLM) while saving $15K USD and 500 hours in human evaluation costs. We find that closed-source LLMs such as GPT-4 and Claude 2 produce summaries with higher BooookScore than those generated by open-source models. While LLaMA 2 falls behind other models, Mixtral achieves performance on par with GPT-3.5-Turbo. Incremental updating yields lower BooookScore but higher level of detail than hierarchical merging, a trade-off sometimes preferred by annotators.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper explores the challenges of summarizing book-length documents using large language models (LLMs).
• It presents the first study on the coherence of LLM-based book-length summarizers, evaluating two prompting workflows: hierarchically merging chunk-level summaries and incrementally updating a running summary.
• The authors develop a new automatic metric, BookScore, to measure the coherence of LLM-generated summaries and systematically evaluate the impact of various parameters.
• The paper finds that closed-source LLMs like GPT-4 and Claude 2 produce more coherent summaries than open-source models, while the LLaMA 2 model lags behind.
Plain English Explanation
Summarizing long books and documents (over 100,000 words) is a challenging task for large language models (LLMs) like GPT-4 and LLaMA 2. This is because LLMs have a limited "context window" - they can only process a certain amount of text at a time. To summarize a long document, the text needs to be broken into smaller chunks, and the LLM has to then combine and condense those chunk-level summaries.
The researchers in this paper looked at two different ways of doing this - [object Object] and [object Object]. They got human evaluators to carefully examine the coherence (how well the different parts flow together) of summaries generated by different LLMs using these methods.
The researchers found that closed-source, proprietary LLMs like GPT-4 and Claude 2 produced more coherent summaries than open-source models like LLaMA 2. They also developed a new automatic metric called BookScore that can measure coherence without needing expensive human evaluations.
Overall, this research highlights the challenges of using LLMs for summarizing long documents, and shows that more work is needed to improve their ability to generate coherent, high-quality summaries of book-length content.
Technical Explanation
The paper addresses the challenge of summarizing book-length documents (over 100,000 tokens) using large language models (LLMs). LLMs have a limited "context window" and struggle to maintain coherence when summarizing long texts. To address this, the researchers explored two prompting workflows:
-
[object Object]: Breaking the input document into smaller chunks, generating summaries for each chunk, and then merging those chunk-level summaries.
-
[object Object]: Generating a summary for the first chunk, then updating that summary as additional chunks are processed.
The researchers obtained 1,193 human annotations on summaries generated by GPT-4 for 100 recently-published books. This allowed them to identify eight common types of coherence errors made by LLMs.
To avoid the high cost and time of human evaluation, the researchers developed an automatic metric called BookScore. BookScore measures the proportion of sentences in a summary that do not contain any of the identified coherence error types. They found that BookScore has high agreement with human annotations, allowing them to systematically evaluate the impact of factors like chunk size and base LLM.
The key findings are:
- Closed-source LLMs like GPT-4 and Claude 2 produce summaries with higher BookScore than open-source models like LLaMA 2.
- While LLaMA 2 lags behind, the Mixtral model achieves performance on par with GPT-3.5-Turbo.
- Incremental updating yields lower BookScore but higher level of detail than hierarchical merging, a trade-off sometimes preferred by annotators.
Critical Analysis
The paper makes a valuable contribution by being the first to systematically study the coherence of LLM-based book-length summarizers. The identification of common coherence error types and the development of the BookScore metric are particularly noteworthy.
However, the paper also acknowledges several limitations:
-
The study is limited to 100 recently-published books, which may not be representative of the full diversity of book-length content.
-
The human evaluation process, while rigorous, is still relatively small in scale compared to the vast amount of book-length content that exists.
-
The paper does not address the potential for [object Object] in LLM-generated summaries, which could be an important area for further research.
-
The [object Object] is not explored, and could potentially lead to improvements in coherence and accuracy.
Overall, this paper provides a solid foundation for understanding the challenges of book-length summarization using LLMs, but more research is needed to fully address the limitations and further improve the performance of these models.
Conclusion
This paper presents the first comprehensive study on the coherence of LLM-based book-length summarizers. The researchers developed a new automatic metric, BookScore, to measure coherence and used it to systematically evaluate the performance of various LLMs on this task.
The key finding is that closed-source LLMs like GPT-4 and Claude 2 outperform open-source models in terms of summary coherence, although the Mixtral model achieves competitive results. The paper also highlights the trade-offs between hierarchical merging and incremental updating of summaries, with the latter providing more detailed but less coherent results.
This research is an important step towards improving the ability of LLMs to summarize long-form content, which is crucial for many real-world applications. By identifying common coherence issues and developing new evaluation metrics, the paper lays the groundwork for further advancements in this challenging area of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
Enhancing Trust in LLM-Generated Code Summaries with Calibrated Confidence Scores
Yuvraj Virk, Premkumar Devanbu, Toufique Ahmed
0
0
A good summary can often be very useful during program comprehension. While a brief, fluent, and relevant summary can be helpful, it does require significant human effort to produce. Often, good summaries are unavailable in software projects, thus making maintenance more difficult. There has been a considerable body of research into automated AI-based methods, using Large Language models (LLMs), to generate summaries of code; there also has been quite a bit work on ways to measure the performance of such summarization methods, with special attention paid to how closely these AI-generated summaries resemble a summary a human might have produced. Measures such as BERTScore and BLEU have been suggested and evaluated with human-subject studies. However, LLMs often err and generate something quite unlike what a human might say. Given an LLM-produced code summary, is there a way to gauge whether it's likely to be sufficiently similar to a human produced summary, or not? In this paper, we study this question, as a calibration problem: given a summary from an LLM, can we compute a confidence measure, which is a good indication of whether the summary is sufficiently similar to what a human would have produced in this situation? We examine this question using several LLMs, for several languages, and in several different settings. We suggest an approach which provides well-calibrated predictions of likelihood of similarity to human summaries.
5/1/2024
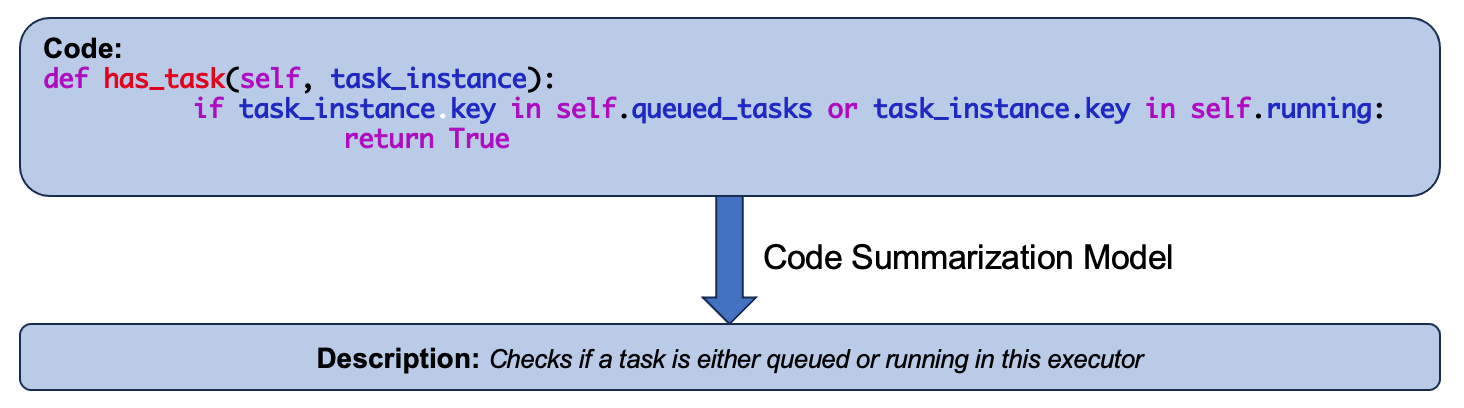
Analyzing the Performance of Large Language Models on Code Summarization
Rajarshi Haldar, Julia Hockenmaier
0
0
Large language models (LLMs) such as Llama 2 perform very well on tasks that involve both natural language and source code, particularly code summarization and code generation. We show that for the task of code summarization, the performance of these models on individual examples often depends on the amount of (subword) token overlap between the code and the corresponding reference natural language descriptions in the dataset. This token overlap arises because the reference descriptions in standard datasets (corresponding to docstrings in large code bases) are often highly similar to the names of the functions they describe. We also show that this token overlap occurs largely in the function names of the code and compare the relative performance of these models after removing function names versus removing code structure. We also show that using multiple evaluation metrics like BLEU and BERTScore gives us very little additional insight since these metrics are highly correlated with each other.
4/15/2024
Characterizing Multimodal Long-form Summarization: A Case Study on Financial Reports
Tianyu Cao, Natraj Raman, Danial Dervovic, Chenhao Tan
0
0
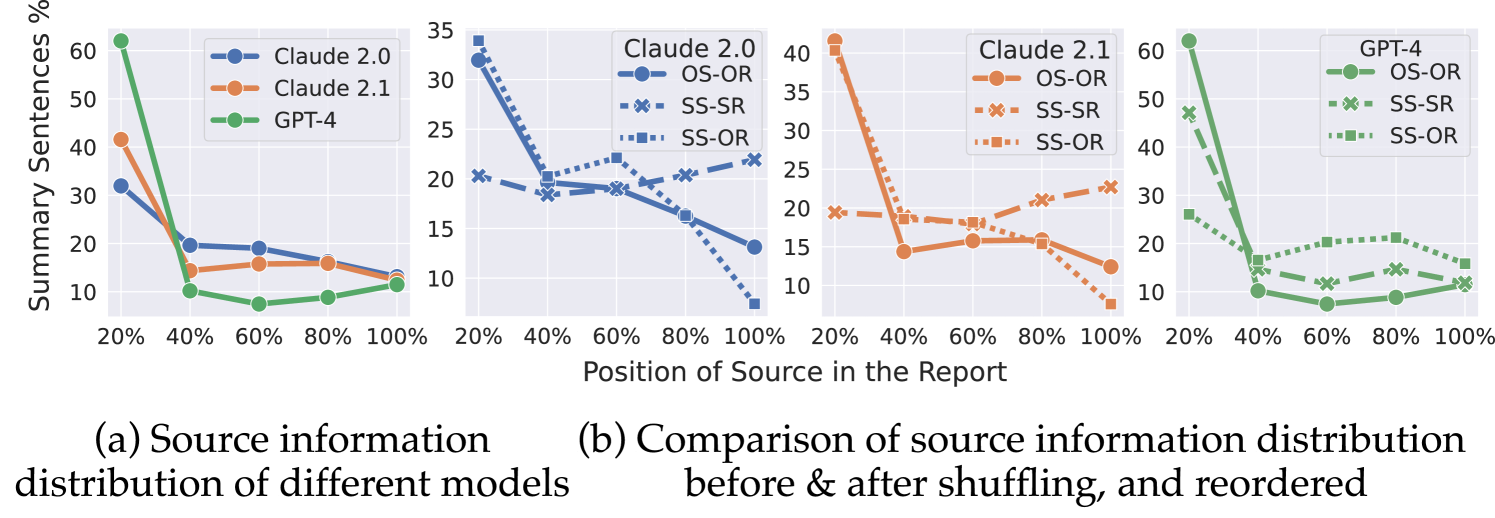
As large language models (LLMs) expand the power of natural language processing to handle long inputs, rigorous and systematic analyses are necessary to understand their abilities and behavior. A salient application is summarization, due to its ubiquity and controversy (e.g., researchers have declared the death of summarization). In this paper, we use financial report summarization as a case study because financial reports not only are long but also use numbers and tables extensively. We propose a computational framework for characterizing multimodal long-form summarization and investigate the behavior of Claude 2.0/2.1, GPT-4/3.5, and Command. We find that GPT-3.5 and Command fail to perform this summarization task meaningfully. For Claude 2 and GPT-4, we analyze the extractiveness of the summary and identify a position bias in LLMs. This position bias disappears after shuffling the input for Claude, which suggests that Claude has the ability to recognize important information. We also conduct a comprehensive investigation on the use of numeric data in LLM-generated summaries and offer a taxonomy of numeric hallucination. We employ prompt engineering to improve GPT-4's use of numbers with limited success. Overall, our analyses highlight the strong capability of Claude 2 in handling long multimodal inputs compared to GPT-4.
5/9/2024

On the Limitations of Large Language Models (LLMs): False Attribution
Tosin Adewumi, Nudrat Habib, Lama Alkhaled, Elisa Barney
0
0
In this work, we provide insight into one important limitation of large language models (LLMs), i.e. false attribution, and introduce a new hallucination metric - Simple Hallucination Index (SHI). The task of automatic author attribution for relatively small chunks of text is an important NLP task but can be challenging. We empirically evaluate the power of 3 open SotA LLMs in zero-shot setting (LLaMA-2-13B, Mixtral 8x7B, and Gemma-7B), especially as human annotation can be costly. We collected the top 10 most popular books, according to Project Gutenberg, divided each one into equal chunks of 400 words, and asked each LLM to predict the author. We then randomly sampled 162 chunks for human evaluation from each of the annotated books, based on the error margin of 7% and a confidence level of 95% for the book with the most chunks (Great Expectations by Charles Dickens, having 922 chunks). The average results show that Mixtral 8x7B has the highest prediction accuracy, the lowest SHI, and a Pearson's correlation (r) of 0.737, 0.249, and -0.9996, respectively, followed by LLaMA-2-13B and Gemma-7B. However, Mixtral 8x7B suffers from high hallucinations for 3 books, rising as high as an SHI of 0.87 (in the range 0-1, where 1 is the worst). The strong negative correlation of accuracy and SHI, given by r, demonstrates the fidelity of the new hallucination metric, which is generalizable to other tasks. We publicly release the annotated chunks of data and our codes to aid the reproducibility and evaluation of other models.
4/9/2024