Boosting Online 3D Multi-Object Tracking through Camera-Radar Cross Check

0

Sign in to get full access
Overview
- Presents a camera-radar fusion approach for boosting online 3D multi-object tracking
- Leverages the complementary strengths of camera and radar sensors to improve tracking performance
- Introduces a novel cross-check mechanism to align detections from the two modalities
Plain English Explanation
The paper describes a method for improving the tracking of multiple objects in a 3D environment using data from both camera and radar sensors. Camera-radar fusion is used to take advantage of the unique capabilities of each sensor type. Cameras provide detailed visual information, while radar can detect objects at a distance and is less affected by environmental conditions.
The key innovation is a "cross-check" process that aligns the detections from the camera and radar, helping to resolve discrepancies and enhance the overall tracking performance. This multi-sensor fusion approach results in more robust and accurate 3D multi-object tracking compared to using either sensor alone.
Technical Explanation
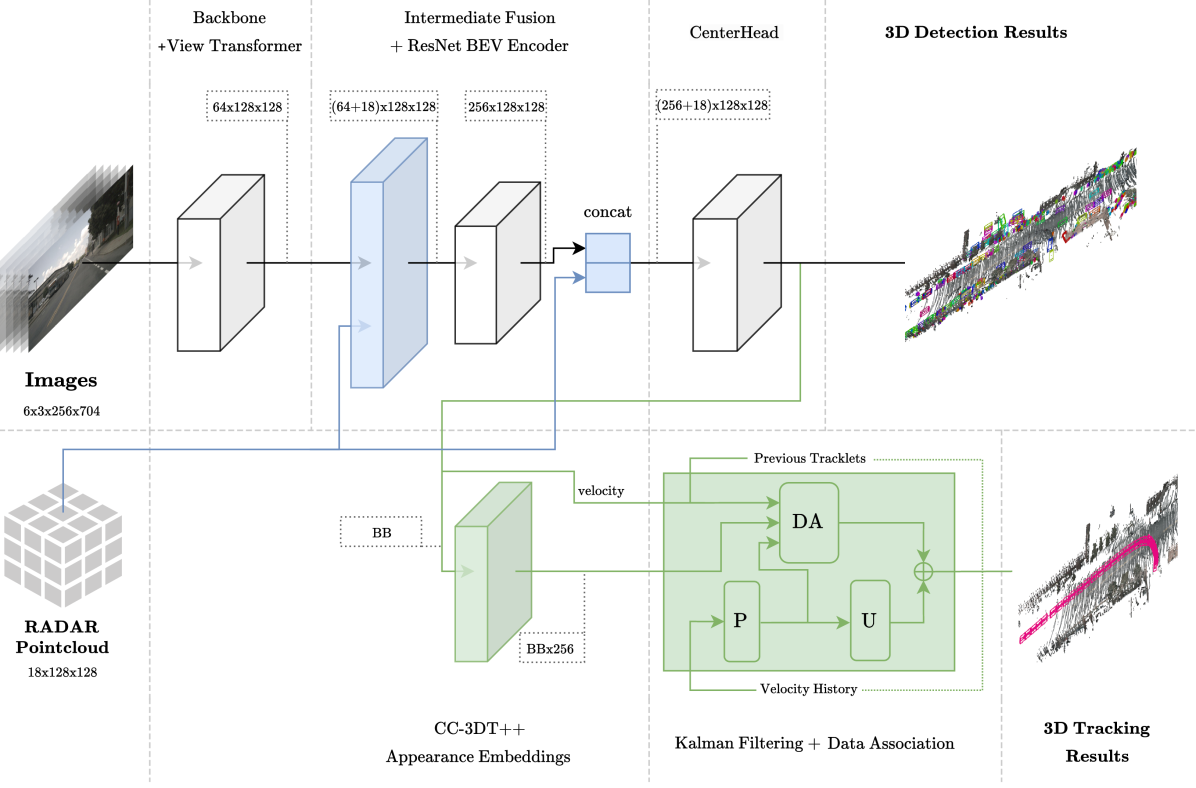
The paper proposes an online 3D multi-object tracking framework that combines camera and radar data. It first generates object detections and 3D bounding boxes from each sensor independently. Then, a cross-check mechanism is used to align the detections and resolve any discrepancies between the two modalities.
The cross-check process involves spatial and appearance matching to associate camera and radar detections that correspond to the same physical object. This cross-domain spatial matching allows the system to leverage the complementary strengths of the sensors and improve the overall tracking accuracy.
The fused detections are then input to a deep learning-based robust multi-object tracking algorithm to generate the final 3D trajectories of the objects. Experiments on public benchmark datasets demonstrate the effectiveness of the proposed camera-radar fusion approach compared to using a single sensor.
Critical Analysis
The paper presents a compelling approach for leveraging multi-sensor fusion to boost the performance of online 3D multi-object tracking. The authors acknowledge that their method relies on accurate camera and radar detections, which could be a limitation in challenging real-world environments with occlusions or sensor failures.
Additionally, the cross-check process introduces an extra computational step that could impact the system's efficiency, especially in scenarios with a large number of objects. Further research may be needed to optimize the balance between tracking accuracy and processing speed.
While the experimental results are promising, the authors do not provide a thorough analysis of the failure cases or edge cases where the camera-radar fusion approach may struggle. Exploring these limitations and potential failure modes would help researchers better understand the scope and applicability of the proposed technique.
Conclusion
This paper introduces a novel camera-radar fusion approach for boosting online 3D multi-object tracking. By leveraging the complementary strengths of the two sensor modalities and introducing a cross-check mechanism, the authors demonstrate improved tracking performance compared to single-sensor methods.
The proposed technique has the potential to enhance a wide range of applications, from autonomous vehicles to surveillance systems, by providing more robust and accurate 3D object tracking in complex environments. As multi-sensor fusion continues to be an active area of research, this work represents an important contribution to the field of multi-object tracking.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Boosting Online 3D Multi-Object Tracking through Camera-Radar Cross Check
Sheng-Yao Kuan, Jen-Hao Cheng, Hsiang-Wei Huang, Wenhao Chai, Cheng-Yen Yang, Hugo Latapie, Gaowen Liu, Bing-Fei Wu, Jenq-Neng Hwang
In the domain of autonomous driving, the integration of multi-modal perception techniques based on data from diverse sensors has demonstrated substantial progress. Effectively surpassing the capabilities of state-of-the-art single-modality detectors through sensor fusion remains an active challenge. This work leverages the respective advantages of cameras in perspective view and radars in Bird's Eye View (BEV) to greatly enhance overall detection and tracking performance. Our approach, Camera-Radar Associated Fusion Tracking Booster (CRAFTBooster), represents a pioneering effort to enhance radar-camera fusion in the tracking stage, contributing to improved 3D MOT accuracy. The superior experimental results on the K-Radaar dataset, which exhibit 5-6% on IDF1 tracking performance gain, validate the potential of effective sensor fusion in advancing autonomous driving.
Read more7/22/2024
0
CR3DT: Camera-RADAR Fusion for 3D Detection and Tracking
Nicolas Baumann, Michael Baumgartner, Edoardo Ghignone, Jonas Kuhne, Tobias Fischer, Yung-Hsu Yang, Marc Pollefeys, Michele Magno
To enable self-driving vehicles accurate detection and tracking of surrounding objects is essential. While Light Detection and Ranging (LiDAR) sensors have set the benchmark for high-performance systems, the appeal of camera-only solutions lies in their cost-effectiveness. Notably, despite the prevalent use of Radio Detection and Ranging (RADAR) sensors in automotive systems, their potential in 3D detection and tracking has been largely disregarded due to data sparsity and measurement noise. As a recent development, the combination of RADARs and cameras is emerging as a promising solution. This paper presents Camera-RADAR 3D Detection and Tracking (CR3DT), a camera-RADAR fusion model for 3D object detection, and Multi-Object Tracking (MOT). Building upon the foundations of the State-of-the-Art (SotA) camera-only BEVDet architecture, CR3DT demonstrates substantial improvements in both detection and tracking capabilities, by incorporating the spatial and velocity information of the RADAR sensor. Experimental results demonstrate an absolute improvement in detection performance of 5.3% in mean Average Precision (mAP) and a 14.9% increase in Average Multi-Object Tracking Accuracy (AMOTA) on the nuScenes dataset when leveraging both modalities. CR3DT bridges the gap between high-performance and cost-effective perception systems in autonomous driving, by capitalizing on the ubiquitous presence of RADAR in automotive applications. The code is available at: https://github.com/ETH-PBL/CR3DT.
Read more8/7/2024

0
RCBEVDet++: Toward High-accuracy Radar-Camera Fusion 3D Perception Network
Zhiwei Lin, Zhe Liu, Yongtao Wang, Le Zhang, Ce Zhu
Perceiving the surrounding environment is a fundamental task in autonomous driving. To obtain highly accurate perception results, modern autonomous driving systems typically employ multi-modal sensors to collect comprehensive environmental data. Among these, the radar-camera multi-modal perception system is especially favored for its excellent sensing capabilities and cost-effectiveness. However, the substantial modality differences between radar and camera sensors pose challenges in fusing information. To address this problem, this paper presents RCBEVDet, a radar-camera fusion 3D object detection framework. Specifically, RCBEVDet is developed from an existing camera-based 3D object detector, supplemented by a specially designed radar feature extractor, RadarBEVNet, and a Cross-Attention Multi-layer Fusion (CAMF) module. Firstly, RadarBEVNet encodes sparse radar points into a dense bird's-eye-view (BEV) feature using a dual-stream radar backbone and a Radar Cross Section aware BEV encoder. Secondly, the CAMF module utilizes a deformable attention mechanism to align radar and camera BEV features and adopts channel and spatial fusion layers to fuse them. To further enhance RCBEVDet's capabilities, we introduce RCBEVDet++, which advances the CAMF through sparse fusion, supports query-based multi-view camera perception models, and adapts to a broader range of perception tasks. Extensive experiments on the nuScenes show that our method integrates seamlessly with existing camera-based 3D perception models and improves their performance across various perception tasks. Furthermore, our method achieves state-of-the-art radar-camera fusion results in 3D object detection, BEV semantic segmentation, and 3D multi-object tracking tasks. Notably, with ViT-L as the image backbone, RCBEVDet++ achieves 72.73 NDS and 67.34 mAP in 3D object detection without test-time augmentation or model ensembling.
Read more9/10/2024

0
Deep Learning-Based Robust Multi-Object Tracking via Fusion of mmWave Radar and Camera Sensors
Lei Cheng, Arindam Sengupta, Siyang Cao
Autonomous driving holds great promise in addressing traffic safety concerns by leveraging artificial intelligence and sensor technology. Multi-Object Tracking plays a critical role in ensuring safer and more efficient navigation through complex traffic scenarios. This paper presents a novel deep learning-based method that integrates radar and camera data to enhance the accuracy and robustness of Multi-Object Tracking in autonomous driving systems. The proposed method leverages a Bi-directional Long Short-Term Memory network to incorporate long-term temporal information and improve motion prediction. An appearance feature model inspired by FaceNet is used to establish associations between objects across different frames, ensuring consistent tracking. A tri-output mechanism is employed, consisting of individual outputs for radar and camera sensors and a fusion output, to provide robustness against sensor failures and produce accurate tracking results. Through extensive evaluations of real-world datasets, our approach demonstrates remarkable improvements in tracking accuracy, ensuring reliable performance even in low-visibility scenarios.
Read more7/12/2024