BotEval: Facilitating Interactive Human Evaluation

0

Sign in to get full access
Overview
- BotEval is a system that facilitates interactive human evaluation of conversational AI systems.
- It allows users to engage with chatbots, provide feedback, and rate their performance.
- The system collects and aggregates this feedback to help improve the chatbots.
Plain English Explanation
BotEval: Facilitating Interactive Human Evaluation is a research paper that describes a system called BotEval, which is designed to make it easier for humans to evaluate and provide feedback on conversational AI systems, such as chatbots.
The key idea behind BotEval is to create an interactive platform where users can engage with different chatbots, have conversations with them, and then provide feedback on the chatbot's performance. This feedback can include ratings, comments, and other assessments of the chatbot's capabilities, such as its ability to understand natural language, provide relevant and coherent responses, and meet the user's needs.
By collecting and aggregating this feedback from many users, the BotEval system can help researchers and developers improve the chatbots over time. The feedback can provide valuable insights into the strengths and weaknesses of the chatbots, allowing the developers to refine and enhance the systems.
Technical Explanation
BotEval: Facilitating Interactive Human Evaluation describes the key components of the BotEval system. It includes:
- User interface: BotEval provides a web-based interface where users can interact with chatbots and provide feedback.
- Chatbot integration: The system is designed to integrate with various chatbot platforms, allowing users to engage with a diverse range of conversational AI systems.
- Feedback collection: BotEval collects user feedback, including ratings, comments, and other assessments of the chatbot's performance.
- Aggregation and analysis: The system aggregates the feedback data and provides insights to researchers and developers, helping them understand the strengths and weaknesses of the chatbots.
The paper also discusses the experimental evaluation of the BotEval system, which involved testing its usability and the quality of the feedback collected.
Critical Analysis
The paper acknowledges some limitations of the BotEval system, such as the need for further research to understand the factors that influence user feedback and the potential biases that may arise. Additionally, the paper suggests that the system could be expanded to support more advanced features, such as the ability to capture non-textual feedback (e.g., facial expressions, tone of voice) and to provide more detailed analytics and visualizations.
While the BotEval system represents a valuable contribution to the field of conversational AI evaluation, there may be other approaches or techniques that could provide complementary insights. For example, some researchers have explored the use of automated evaluation methods, such as HumanRankEval and RealHumanEval, which may offer different perspectives on chatbot performance.
Conclusion
BotEval: Facilitating Interactive Human Evaluation introduces a system that aims to streamline the process of collecting and analyzing human feedback on conversational AI systems. By providing an interactive platform for users to engage with chatbots and share their assessments, BotEval can help researchers and developers better understand the strengths and weaknesses of these systems, ultimately leading to their improvement and more effective deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BotEval: Facilitating Interactive Human Evaluation
Hyundong Cho, Thamme Gowda, Yuyang Huang, Zixun Lu, Tianli Tong, Jonathan May
Following the rapid progress in natural language processing (NLP) models, language models are applied to increasingly more complex interactive tasks such as negotiations and conversation moderations. Having human evaluators directly interact with these NLP models is essential for adequately evaluating the performance on such interactive tasks. We develop BotEval, an easily customizable, open-source, evaluation toolkit that focuses on enabling human-bot interactions as part of the evaluation process, as opposed to human evaluators making judgements for a static input. BotEval balances flexibility for customization and user-friendliness by providing templates for common use cases that span various degrees of complexity and built-in compatibility with popular crowdsourcing platforms. We showcase the numerous useful features of BotEval through a study that evaluates the performance of various chatbots on their effectiveness for conversational moderation and discuss how BotEval differs from other annotation tools.
Read more7/26/2024
0
The Challenges of Evaluating LLM Applications: An Analysis of Automated, Human, and LLM-Based Approaches
Bhashithe Abeysinghe, Ruhan Circi
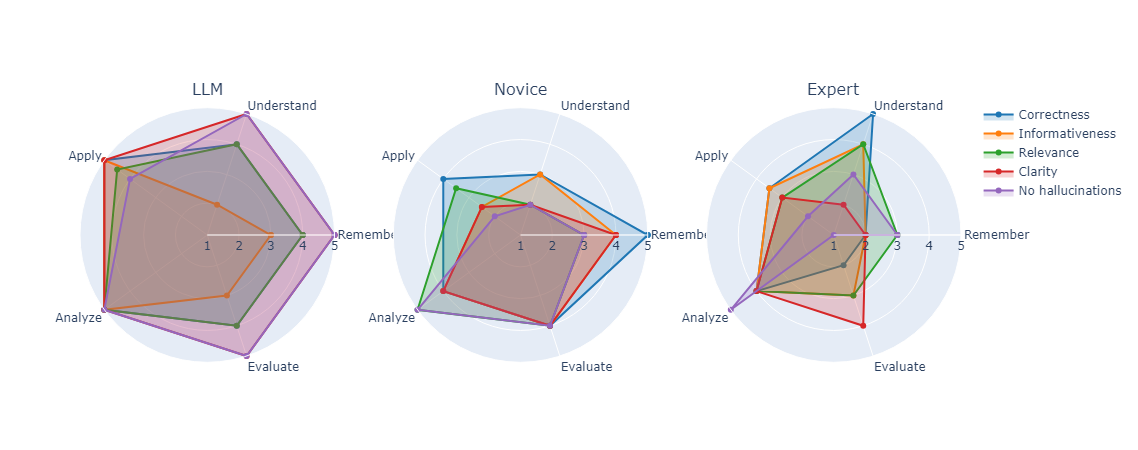
Chatbots have been an interesting application of natural language generation since its inception. With novel transformer based Generative AI methods, building chatbots have become trivial. Chatbots which are targeted at specific domains for example medicine and psychology are implemented rapidly. This however, should not distract from the need to evaluate the chatbot responses. Especially because the natural language generation community does not entirely agree upon how to effectively evaluate such applications. With this work we discuss the issue further with the increasingly popular LLM based evaluations and how they correlate with human evaluations. Additionally, we introduce a comprehensive factored evaluation mechanism that can be utilized in conjunction with both human and LLM-based evaluations. We present the results of an experimental evaluation conducted using this scheme in one of our chatbot implementations which consumed educational reports, and subsequently compare automated, traditional human evaluation, factored human evaluation, and factored LLM evaluation. Results show that factor based evaluation produces better insights on which aspects need to be improved in LLM applications and further strengthens the argument to use human evaluation in critical spaces where main functionality is not direct retrieval.
Read more6/14/2024
0
HumanRankEval: Automatic Evaluation of LMs as Conversational Assistants
Milan Gritta, Gerasimos Lampouras, Ignacio Iacobacci
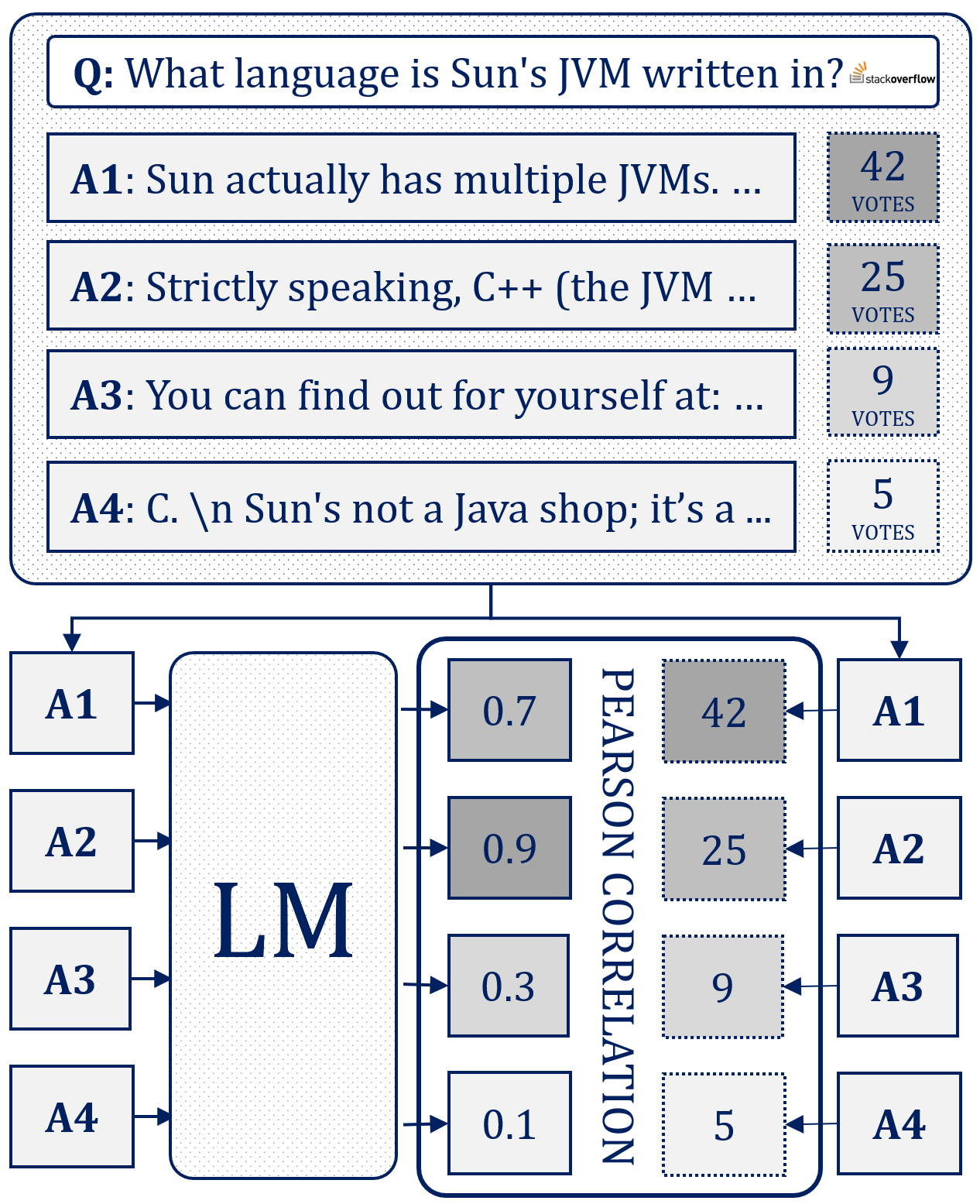
Language models (LMs) as conversational assistants recently became popular tools that help people accomplish a variety of tasks. These typically result from adapting LMs pretrained on general domain text sequences through further instruction-tuning and possibly preference optimisation methods. The evaluation of such LMs would ideally be performed using human judgement, however, this is not scalable. On the other hand, automatic evaluation featuring auxiliary LMs as judges and/or knowledge-based tasks is scalable but struggles with assessing conversational ability and adherence to instructions. To help accelerate the development of LMs as conversational assistants, we propose a novel automatic evaluation task: HumanRankEval (HRE). It consists of a large-scale, diverse and high-quality set of questions, each with several answers authored and scored by humans. To perform evaluation, HRE ranks these answers based on their log-likelihood under the LM's distribution, and subsequently calculates their correlation with the corresponding human rankings. We support HRE's efficacy by investigating how efficiently it separates pretrained and instruction-tuned LMs of various sizes. We show that HRE correlates well with human judgements and is particularly responsive to model changes following instruction-tuning.
Read more5/16/2024

0
Online vs Offline: A Comparative Study of First-Party and Third-Party Evaluations of Social Chatbots
Ekaterina Svikhnushina, Pearl Pu
This paper explores the efficacy of online versus offline evaluation methods in assessing conversational chatbots, specifically comparing first-party direct interactions with third-party observational assessments. By extending a benchmarking dataset of user dialogs with empathetic chatbots with offline third-party evaluations, we present a systematic comparison between the feedback from online interactions and the more detached offline third-party evaluations. Our results reveal that offline human evaluations fail to capture the subtleties of human-chatbot interactions as effectively as online assessments. In comparison, automated third-party evaluations using a GPT-4 model offer a better approximation of first-party human judgments given detailed instructions. This study highlights the limitations of third-party evaluations in grasping the complexities of user experiences and advocates for the integration of direct interaction feedback in conversational AI evaluation to enhance system development and user satisfaction.
Read more9/14/2024