C-MCTS: Safe Planning with Monte Carlo Tree Search
2305.16209
0
0
🤯
Abstract
The Constrained Markov Decision Process (CMDP) formulation allows to solve safety-critical decision making tasks that are subject to constraints. While CMDPs have been extensively studied in the Reinforcement Learning literature, little attention has been given to sampling-based planning algorithms such as MCTS for solving them. Previous approaches perform conservatively with respect to costs as they avoid constraint violations by using Monte Carlo cost estimates that suffer from high variance. We propose Constrained MCTS (C-MCTS), which estimates cost using a safety critic that is trained with Temporal Difference learning in an offline phase prior to agent deployment. The critic limits exploration by pruning unsafe trajectories within MCTS during deployment. C-MCTS satisfies cost constraints but operates closer to the constraint boundary, achieving higher rewards than previous work. As a nice byproduct, the planner is more efficient w.r.t. planning steps. Most importantly, under model mismatch between the planner and the real world, C-MCTS is less susceptible to cost violations than previous work.
Create account to get full access
Overview
- This paper proposes a new approach called Constrained MCTS (C-MCTS) for solving safety-critical decision-making tasks that are subject to constraints.
- Previous approaches in the Reinforcement Learning literature have used Monte Carlo Tree Search (MCTS) methods conservatively to avoid constraint violations, but this can lead to suboptimal performance.
- C-MCTS estimates costs using a safety critic trained offline, which allows it to explore closer to the constraint boundary while still satisfying the constraints.
- The paper also shows that C-MCTS is less susceptible to cost violations than previous methods under model mismatch between the planner and the real world.
Plain English Explanation
The paper addresses the challenge of making decisions in situations where there are important constraints that must be satisfied, such as safety or cost limits. Previous methods have been very careful to avoid violating these constraints, but this can mean they don't fully explore the space of possible actions and end up with suboptimal decisions.
The key idea in this paper is to use a separate "safety critic" model that is trained ahead of time to estimate the likelihood of violating constraints. This safety critic is then used within the Monte Carlo Tree Search (MCTS) planning algorithm to prune away trajectories that are likely to violate constraints. This allows the planner to explore more aggressively while still satisfying the constraints.
The authors show that this approach, called Constrained MCTS (C-MCTS), can achieve higher rewards than previous methods while still guaranteeing that the constraints are met. They also find that C-MCTS is more robust to differences between the model used for planning and the real-world system being controlled, which is an important practical concern.
Technical Explanation
The paper proposes a new planning algorithm called Constrained MCTS (C-MCTS) for solving Constrained Markov Decision Processes (CMDPs), which are a class of decision-making problems where there are constraints on the allowed costs or risks.
Previous MCTS-based approaches for CMDPs, such as CMDP-within-Online and CC-VPSTO, have used Monte Carlo estimates of the costs to avoid constraint violations. However, these Monte Carlo estimates can have high variance, leading to overly conservative behavior.
In contrast, C-MCTS uses a learned "safety critic" model to estimate the cost-to-go during the tree search. This safety critic is trained offline using Temporal Difference learning on samples of the CMDP. By leveraging this learned cost estimate, C-MCTS can explore closer to the constraint boundary while still satisfying the constraints.
The key advantages of C-MCTS are:
- It achieves higher rewards than previous MCTS-based methods for CMDPs by exploring more aggressively.
- It is more efficient in terms of the number of planning steps required.
- It is more robust to model mismatch between the planner and the real-world system being controlled, exhibiting fewer constraint violations.
Critical Analysis
The paper presents a novel and promising approach for solving safety-critical decision-making problems. The use of a learned safety critic to guide the MCTS planning is a clever idea that allows the planner to operate closer to the constraint boundary while still satisfying the constraints.
One potential limitation is that the performance of C-MCTS may depend heavily on the quality of the learned safety critic. If the critic is not well-trained or does not accurately capture the true cost landscape, it could lead to constraint violations or suboptimal performance. The paper does not provide a thorough analysis of the sensitivity of C-MCTS to the safety critic model.
Additionally, the paper only evaluates C-MCTS on relatively simple simulated environments. It would be important to see how the approach scales and performs on more complex, real-world problems with richer state/action spaces and more challenging constraints.
Finally, the paper does not compare C-MCTS to other recent advances in constrained planning and control, such as safe exploration methods or chance-constrained optimization techniques. A more comprehensive benchmarking against the state-of-the-art would help situate the contributions of C-MCTS within the broader field.
Overall, the paper presents an interesting and potentially impactful approach, but further research is needed to fully understand its strengths, weaknesses, and practical applicability.
Conclusion
This paper introduces Constrained MCTS (C-MCTS), a new planning algorithm for solving safety-critical decision-making problems subject to constraints. C-MCTS leverages a learned "safety critic" model to guide the Monte Carlo Tree Search (MCTS) exploration, allowing it to operate closer to the constraint boundary while still satisfying the constraints.
The key advantages of C-MCTS are its ability to achieve higher rewards than previous MCTS-based methods for Constrained Markov Decision Processes (CMDPs), its improved planning efficiency, and its increased robustness to model mismatch between the planner and the real-world system.
While the paper demonstrates promising results in simulated environments, further research is needed to fully understand the strengths and limitations of the C-MCTS approach, particularly when applied to more complex, real-world problems. Nonetheless, this work represents an important contribution to the field of safe and constrained planning, with potential applications in robotics, autonomous systems, and other safety-critical domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
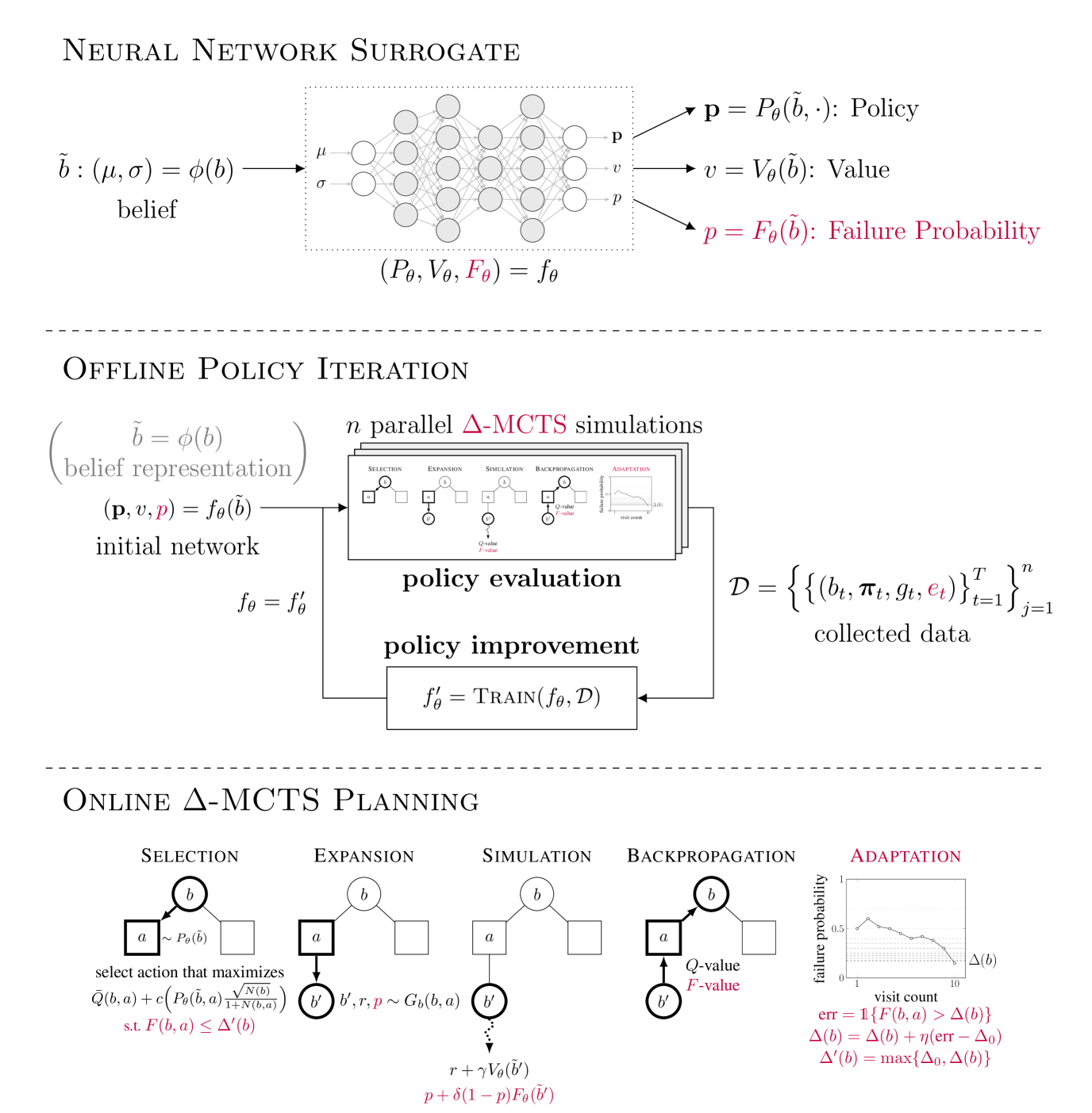
ConstrainedZero: Chance-Constrained POMDP Planning using Learned Probabilistic Failure Surrogates and Adaptive Safety Constraints
Robert J. Moss, Arec Jamgochian, Johannes Fischer, Anthony Corso, Mykel J. Kochenderfer
0
0
To plan safely in uncertain environments, agents must balance utility with safety constraints. Safe planning problems can be modeled as a chance-constrained partially observable Markov decision process (CC-POMDP) and solutions often use expensive rollouts or heuristics to estimate the optimal value and action-selection policy. This work introduces the ConstrainedZero policy iteration algorithm that solves CC-POMDPs in belief space by learning neural network approximations of the optimal value and policy with an additional network head that estimates the failure probability given a belief. This failure probability guides safe action selection during online Monte Carlo tree search (MCTS). To avoid overemphasizing search based on the failure estimates, we introduce $Delta$-MCTS, which uses adaptive conformal inference to update the failure threshold during planning. The approach is tested on a safety-critical POMDP benchmark, an aircraft collision avoidance system, and the sustainability problem of safe CO$_2$ storage. Results show that by separating safety constraints from the objective we can achieve a target level of safety without optimizing the balance between rewards and costs.
5/2/2024
💬
A safe exploration approach to constrained Markov decision processes
Tingting Ni, Maryam Kamgarpour
0
0
We consider discounted infinite horizon constrained Markov decision processes (CMDPs) where the goal is to find an optimal policy that maximizes the expected cumulative reward subject to expected cumulative constraints. Motivated by the application of CMDPs in online learning of safety-critical systems, we focus on developing a model-free and simulator-free algorithm that ensures constraint satisfaction during learning. To this end, we develop an interior point approach based on the log barrier function of the CMDP. Under the commonly assumed conditions of Fisher non-degeneracy and bounded transfer error of the policy parameterization, we establish the theoretical properties of the algorithm. In particular, in contrast to existing CMDP approaches that ensure policy feasibility only upon convergence, our algorithm guarantees the feasibility of the policies during the learning process and converges to the $varepsilon$-optimal policy with a sample complexity of $tilde{mathcal{O}}(varepsilon^{-6})$. In comparison to the state-of-the-art policy gradient-based algorithm, C-NPG-PDA, our algorithm requires an additional $mathcal{O}(varepsilon^{-2})$ samples to ensure policy feasibility during learning with the same Fisher non-degenerate parameterization.
5/24/2024
🎲
Monte Carlo Planning for Stochastic Control on Constrained Markov Decision Processes
Larkin Liu, Shiqi Liu, Matej Jusup
0
0
In the world of stochastic control, especially in economics and engineering, Markov Decision Processes (MDPs) can effectively model various stochastic decision processes, from asset management to transportation optimization. These underlying MDPs, upon closer examination, often reveal a specifically constrained causal structure concerning the transition and reward dynamics. By exploiting this structure, we can obtain a reduction in the causal representation of the problem setting, allowing us to solve of the optimal value function more efficiently. This work defines an MDP framework, the texttt{SD-MDP}, where we disentangle the causal structure of MDPs' transition and reward dynamics, providing distinct partitions on the temporal causal graph. With this stochastic reduction, the texttt{SD-MDP} reflects a general class of resource allocation problems. This disentanglement further enables us to derive theoretical guarantees on the estimation error of the value function under an optimal policy by allowing independent value estimation from Monte Carlo sampling. Subsequently, by integrating this estimator into well-known Monte Carlo planning algorithms, such as Monte Carlo Tree Search (MCTS), we derive bounds on the simple regret of the algorithm. Finally, we quantify the policy improvement of MCTS under the texttt{SD-MDP} framework by demonstrating that the MCTS planning algorithm achieves higher expected reward (lower costs) under a constant simulation budget, on a tangible economic example based on maritime refuelling.
6/26/2024
🏅
Anytime-Constrained Reinforcement Learning
Jeremy McMahan, Xiaojin Zhu
0
0
We introduce and study constrained Markov Decision Processes (cMDPs) with anytime constraints. An anytime constraint requires the agent to never violate its budget at any point in time, almost surely. Although Markovian policies are no longer sufficient, we show that there exist optimal deterministic policies augmented with cumulative costs. In fact, we present a fixed-parameter tractable reduction from anytime-constrained cMDPs to unconstrained MDPs. Our reduction yields planning and learning algorithms that are time and sample-efficient for tabular cMDPs so long as the precision of the costs is logarithmic in the size of the cMDP. However, we also show that computing non-trivial approximately optimal policies is NP-hard in general. To circumvent this bottleneck, we design provable approximation algorithms that efficiently compute or learn an arbitrarily accurate approximately feasible policy with optimal value so long as the maximum supported cost is bounded by a polynomial in the cMDP or the absolute budget. Given our hardness results, our approximation guarantees are the best possible under worst-case analysis.
6/14/2024