Can humans teach machines to code?
2404.19397
0
0
🔎
Abstract
The goal of inductive program synthesis is for a machine to automatically generate a program from user-supplied examples of the desired behaviour of the program. A key underlying assumption is that humans can provide examples of sufficient quality to teach a concept to a machine. However, as far as we are aware, this assumption lacks both empirical and theoretical support. To address this limitation, we explore the question `Can humans teach machines to code?'. To answer this question, we conduct a study where we ask humans to generate examples for six programming tasks, such as finding the maximum element of a list. We compare the performance of a program synthesis system trained on (i) human-provided examples, (ii) randomly sampled examples, and (iii) expert-provided examples. Our results show that, on most of the tasks, non-expert participants did not provide sufficient examples for a program synthesis system to learn an accurate program. Our results also show that non-experts need to provide more examples than both randomly sampled and expert-provided examples.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper investigates whether humans can provide sufficient examples to teach machines how to code through program synthesis.
- The researchers conducted a study where they asked non-expert participants to generate examples for six programming tasks, and compared the performance of a program synthesis system trained on these examples to randomly sampled and expert-provided examples.
- The results suggest that non-experts often do not provide enough high-quality examples for the program synthesis system to learn accurate programs, and that non-experts need to provide more examples than both randomly sampled and expert-provided examples.
Plain English Explanation
The goal of inductive program synthesis is for a machine to automatically generate a computer program based on examples provided by a human user. The key assumption is that humans can provide good enough examples to teach the machine the desired concept. However, the researchers were unsure if this assumption was valid.
To explore this question, the researchers conducted a study where they asked regular people (non-experts) to provide examples for six different programming tasks, such as finding the maximum element in a list. They then used these examples to train a program synthesis system and compared its performance to a system trained on randomly generated examples and a system trained on examples provided by experts.
The results showed that, for most of the tasks, the non-expert participants did not provide enough high-quality examples for the program synthesis system to learn an accurate program. The non-experts needed to provide many more examples than both the randomly generated and expert-provided examples in order for the system to perform well.
This suggests that the assumption that humans can easily teach machines to code through examples may not be accurate. Regular people struggle to provide the kind of comprehensive and insightful examples that a machine would need to learn complex programming concepts.
Technical Explanation
The paper explores the question of whether humans can effectively teach machines to code through inductive program synthesis. The researchers conducted an experiment where they asked non-expert participants to generate examples for six different programming tasks, such as finding the maximum element in a list or converting Celsius to Fahrenheit.
They then used these human-provided examples to train a program synthesis system, and compared its performance to a system trained on randomly sampled examples and a system trained on examples provided by experts. The researchers evaluated the accuracy of the programs produced by each system on held-out test cases.
The results showed that, for most of the tasks, the non-expert participants did not provide sufficient examples for the program synthesis system to learn an accurate program. The system trained on human-provided examples performed worse than the system trained on randomly sampled examples, and needed many more examples than the expert-provided examples to achieve comparable performance.
These findings challenge the underlying assumption of inductive program synthesis that humans can provide examples of sufficient quality to teach machines complex programming concepts. The paper suggests that non-experts struggle to generate the comprehensive and insightful examples required for effective machine learning of programming tasks.
Critical Analysis
The paper provides important empirical evidence that calls into question a key assumption of inductive program synthesis - that humans can easily teach machines to code through the provision of examples. The researchers' systematic comparison of human-provided, randomly sampled, and expert-provided examples highlights the difficulty non-experts face in generating examples that are sufficient for program synthesis systems to learn accurate programs.
However, the paper does not fully explore the reasons why non-experts struggle in this task. It is possible that with more training or guidance, non-experts could improve their ability to provide high-quality examples. Additionally, the paper only examines a limited set of programming tasks, and the results may not generalize to all types of programming problems.
Further research is needed to better understand the factors that influence humans' ability to teach machines through examples, and to explore alternative approaches to bridging the gap between human and machine programming. Potential avenues include investigating the use of large language models for concept induction or exploring hybrid approaches that combine human and machine contributions.
Conclusion
This paper presents an important challenge to the assumption that humans can effectively teach machines to code through the provision of examples. The results suggest that non-experts struggle to generate the quality and quantity of examples required for program synthesis systems to learn accurate programs.
While the findings raise doubts about the feasibility of purely human-driven approaches to teaching machines programming, they also highlight the need for further research to better understand the factors that influence human teaching ability and to explore alternative approaches to bridging the gap between human and machine programming. Addressing these challenges could lead to significant advancements in the field of inductive program synthesis and the broader goal of enabling machines to learn complex skills from human guidance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Language Models Synergize with Automated Machine Learning
Jinglue Xu, Jialong Li, Zhen Liu, Nagar Anthel Venkatesh Suryanarayanan, Guoyuan Zhou, Jia Guo, Hitoshi Iba, Kenji Tei
0
0
Recently, program synthesis driven by large language models (LLMs) has become increasingly popular. However, program synthesis for machine learning (ML) tasks still poses significant challenges. This paper explores a novel form of program synthesis, targeting ML programs, by combining LLMs and automated machine learning (autoML). Specifically, our goal is to fully automate the generation and optimization of the code of the entire ML workflow, from data preparation to modeling and post-processing, utilizing only textual descriptions of the ML tasks. To manage the length and diversity of ML programs, we propose to break each ML program into smaller, manageable parts. Each part is generated separately by the LLM, with careful consideration of their compatibilities. To ensure compatibilities, we design a testing technique for ML programs. Unlike traditional program synthesis, which typically relies on binary evaluations (i.e., correct or incorrect), evaluating ML programs necessitates more than just binary judgments. Therefore, we further assess ML programs numerically and select the optimal programs from a range of candidates using AutoML methods. In experiments across various ML tasks, our method outperforms existing methods in 10 out of 12 tasks for generating ML programs. In addition, autoML significantly improves the performance of the generated ML programs. In experiments, given the textual task description, our method, Text-to-ML, generates the complete and optimized ML program in a fully autonomous process.
5/14/2024
💬
When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming
Hussein Mozannar, Gagan Bansal, Adam Fourney, Eric Horvitz
0
0
AI powered code-recommendation systems, such as Copilot and CodeWhisperer, provide code suggestions inside a programmer's environment (e.g., an IDE) with the aim of improving productivity. We pursue mechanisms for leveraging signals about programmers' acceptance and rejection of code suggestions to guide recommendations. We harness data drawn from interactions with GitHub Copilot, a system used by millions of programmers, to develop interventions that can save time for programmers. We introduce a utility-theoretic framework to drive decisions about suggestions to display versus withhold. The approach, conditional suggestion display from human feedback (CDHF), relies on a cascade of models that provide the likelihood that recommended code will be accepted. These likelihoods are used to selectively hide suggestions, reducing both latency and programmer verification time. Using data from 535 programmers, we perform a retrospective evaluation of CDHF and show that we can avoid displaying a significant fraction of suggestions that would have been rejected. We further demonstrate the importance of incorporating the programmer's latent unobserved state in decisions about when to display suggestions through an ablation study. Finally, we showcase how using suggestion acceptance as a reward signal for guiding the display of suggestions can lead to suggestions of reduced quality, indicating an unexpected pitfall.
4/23/2024
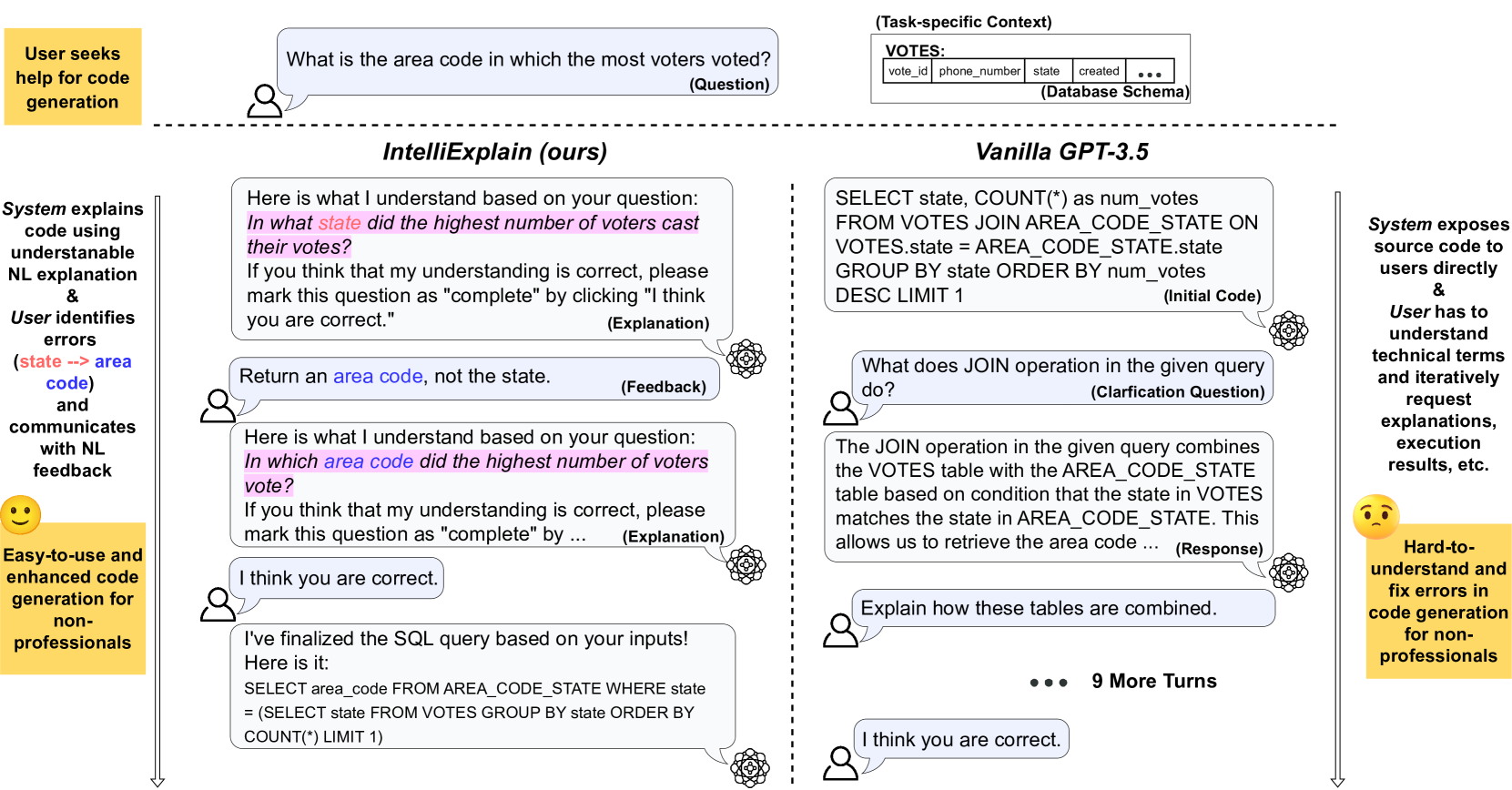
New!IntelliExplain: Enhancing Interactive Code Generation through Natural Language Explanations for Non-Professional Programmers
Hao Yan, Thomas D. Latoza, Ziyu Yao
0
0
Large language models (LLMs) have exhibited a strong promise in automatically generating executable code from natural language descriptions, particularly with interactive features that allow users to engage in the code-generation process by instructing the LLM with iterative feedback. However, existing interaction paradigms often assume that users have expert knowledge to debug source code and are not optimized for non-professional programmers' use. This raises challenges in making interactive code generation more accessible for individuals with varying levels of programming expertise. To tackle these challenges, we present IntelliExplain, which offers a novel human-LLM interaction paradigm to enhance non-professional programmers' experience by enabling them to interact with source code via natural language explanations. Users interact with IntelliExplain by providing natural language corrective feedback on errors they identify from the explanations. Feedback is used by the system to revise the code, until the user is satisfied with explanations by the system of the code. Our user study demonstrates that users with IntelliExplain achieve a significantly higher success rate 11.6% and 25.3% better than with vanilla GPT-3.5, while also requiring 39.0% and 15.6% less time in Text-to-SQL and Python code generation tasks, respectively.
5/17/2024
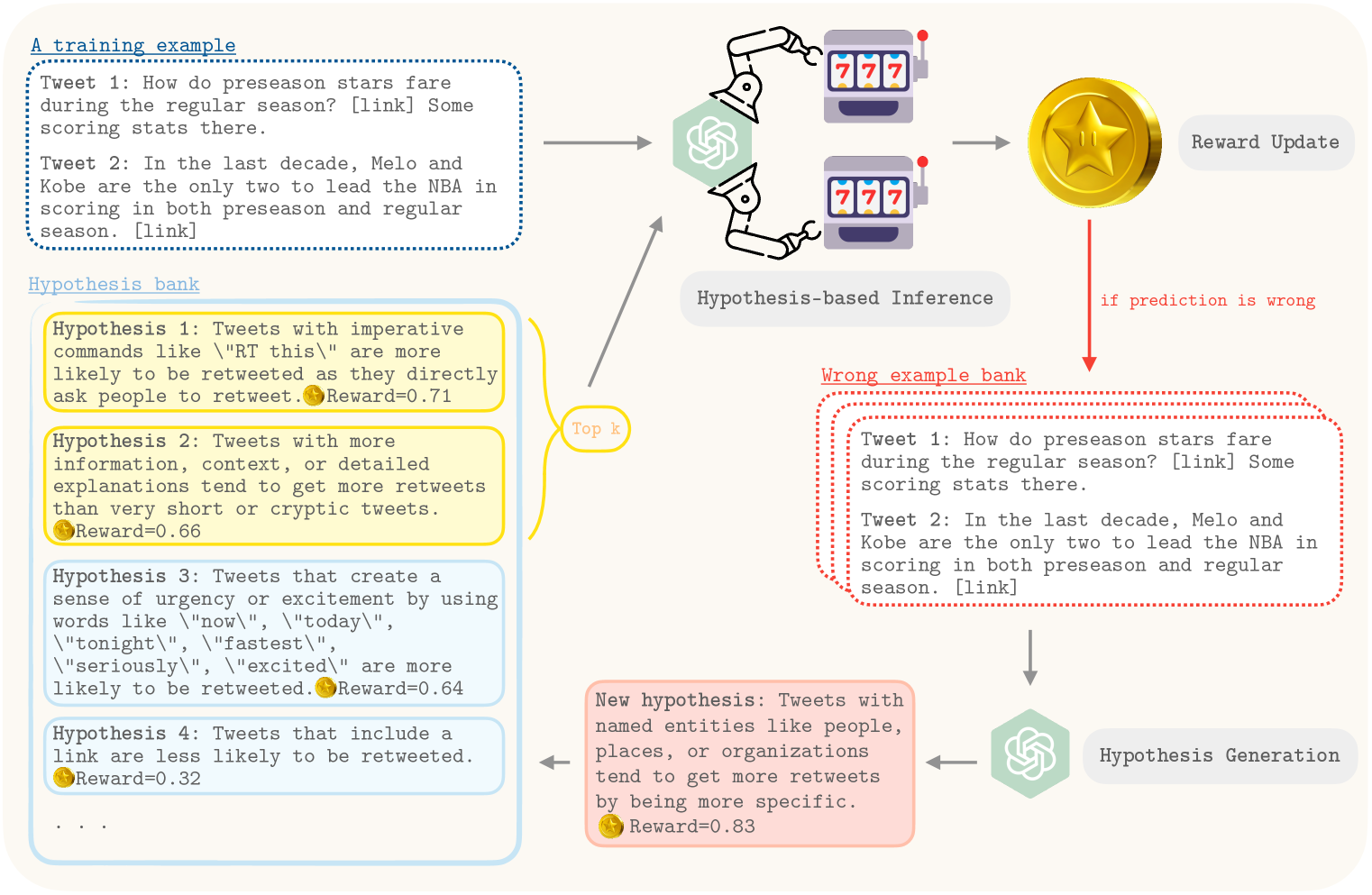
Hypothesis Generation with Large Language Models
Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, Chenhao Tan
0
0
Effective generation of novel hypotheses is instrumental to scientific progress. So far, researchers have been the main powerhouse behind hypothesis generation by painstaking data analysis and thinking (also known as the Eureka moment). In this paper, we examine the potential of large language models (LLMs) to generate hypotheses. We focus on hypothesis generation based on data (i.e., labeled examples). To enable LLMs to handle arbitrarily long contexts, we generate initial hypotheses from a small number of examples and then update them iteratively to improve the quality of hypotheses. Inspired by multi-armed bandits, we design a reward function to inform the exploitation-exploration tradeoff in the update process. Our algorithm is able to generate hypotheses that enable much better predictive performance than few-shot prompting in classification tasks, improving accuracy by 31.7% on a synthetic dataset and by 13.9%, 3.3% and, 24.9% on three real-world datasets. We also outperform supervised learning by 12.8% and 11.2% on two challenging real-world datasets. Furthermore, we find that the generated hypotheses not only corroborate human-verified theories but also uncover new insights for the tasks.
4/9/2024