Capturing Perspectives of Crowdsourced Annotators in Subjective Learning Tasks
2311.09743
0
0
🏅
Abstract
Supervised classification heavily depends on datasets annotated by humans. However, in subjective tasks such as toxicity classification, these annotations often exhibit low agreement among raters. Annotations have commonly been aggregated by employing methods like majority voting to determine a single ground truth label. In subjective tasks, aggregating labels will result in biased labeling and, consequently, biased models that can overlook minority opinions. Previous studies have shed light on the pitfalls of label aggregation and have introduced a handful of practical approaches to tackle this issue. Recently proposed multi-annotator models, which predict labels individually per annotator, are vulnerable to under-determination for annotators with few samples. This problem is exacerbated in crowdsourced datasets. In this work, we propose textbf{Annotator Aware Representations for Texts (AART)} for subjective classification tasks. Our approach involves learning representations of annotators, allowing for exploration of annotation behaviors. We show the improvement of our method on metrics that assess the performance on capturing individual annotators' perspectives. Additionally, we demonstrate fairness metrics to evaluate our model's equability of performance for marginalized annotators compared to others.
Create account to get full access
Overview
- Supervised classification tasks often rely on datasets annotated by humans, but in subjective tasks like toxicity classification, these annotations can have low agreement among raters.
- Commonly, these annotations are aggregated using methods like majority voting to determine a single ground truth label. However, in subjective tasks, this can lead to biased labeling and models that overlook minority opinions.
- Previous studies have explored the issues with label aggregation and proposed approaches to address this challenge.
- Recently introduced multi-annotator models that predict labels individually per annotator can be vulnerable to under-determination for annotators with few samples, especially in crowdsourced datasets.
Plain English Explanation
Machine learning models often need to be trained on datasets where the desired outputs (labels) have been provided by human raters or annotators. However, when the task is subjective, like determining whether a piece of text is toxic or not, different people may disagree on the correct label. Annotator Aware Representations for Texts (AART) aims to address this issue by learning representations of the individual annotators, allowing the model to better understand each person's perspective.
The traditional approach of aggregating all the labels into a single "ground truth" can lead to biased results, overlooking minority opinions. Previous research has highlighted the problems with this approach and explored alternative methods. The multi-annotator models proposed more recently can struggle when some annotators have provided only a few samples, which is common in crowdsourced datasets.
Technical Explanation
The Annotator Aware Representations for Texts (AART) approach involves learning representations of the individual annotators, allowing the model to better understand each person's perspective on the subjective task. This is important because in subjective tasks, such as determining whether a piece of text is toxic or not, different people may disagree on the correct label.
The researchers show that their AART method improves performance on metrics that assess the model's ability to capture the individual annotators' perspectives. They also demonstrate the use of fairness metrics to evaluate how equitable the model's performance is for annotators from marginalized groups compared to others.
This research builds on previous studies that have explored the issues with label aggregation and introduced practical approaches to address this challenge. The multi-annotator models proposed more recently can struggle with under-determination for annotators who have provided only a few samples, which is a common issue in crowdsourced datasets.
Critical Analysis
The paper provides a valuable contribution by addressing the limitations of existing approaches to handling subjective annotations, such as the issues with label aggregation and the challenges faced by multi-annotator models in handling sparse annotations.
However, the paper does not delve into the potential biases that may be introduced by the AART model itself. While the fairness metrics are a step in the right direction, there may be other ways in which the model's representations of annotators could lead to unintended consequences. Additionally, the generalizability of the approach to other types of subjective tasks beyond toxicity classification is not explicitly discussed.
Further research could explore the sensitivity of the AART model to the quality and diversity of the annotator pool, as well as investigate ways to mitigate potential biases introduced by the annotator representations. Evaluating the model's performance on a wider range of subjective tasks would also help establish the broader applicability of the approach.
Conclusion
The Annotator Aware Representations for Texts (AART) approach represents a significant step forward in addressing the challenges of handling subjective annotations in supervised classification tasks. By learning representations of individual annotators, the model can better capture the diverse perspectives and opinions that may exist on subjective topics, overcoming the limitations of traditional label aggregation methods.
This research has important implications for building fairer and more inclusive machine learning models, particularly in domains where subjective judgments play a crucial role. As the field continues to explore ways to incorporate human knowledge and perspectives into AI systems, approaches like AART will be invaluable in ensuring that minority opinions and underrepresented voices are not overlooked.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
Noise Correction on Subjective Datasets
Uthman Jinadu, Yi Ding
0
0
Incorporating every annotator's perspective is crucial for unbiased data modeling. Annotator fatigue and changing opinions over time can distort dataset annotations. To combat this, we propose to learn a more accurate representation of diverse opinions by utilizing multitask learning in conjunction with loss-based label correction. We show that using our novel formulation, we can cleanly separate agreeing and disagreeing annotations. Furthermore, this method provides a controllable way to encourage or discourage disagreement. We demonstrate that this modification can improve prediction performance in a single or multi-annotator setting. Lastly, we show that this method remains robust to additional label noise that is applied to subjective data.
6/5/2024
Annotator-Centric Active Learning for Subjective NLP Tasks
Michiel van der Meer, Neele Falk, Pradeep K. Murukannaiah, Enrico Liscio
0
0
Active Learning (AL) addresses the high costs of collecting human annotations by strategically annotating the most informative samples. However, for subjective NLP tasks, incorporating a wide range of perspectives in the annotation process is crucial to capture the variability in human judgments. We introduce Annotator-Centric Active Learning (ACAL), which incorporates an annotator selection strategy following data sampling. Our objective is two-fold: (1) to efficiently approximate the full diversity of human judgments, and (2) to assess model performance using annotator-centric metrics, which emphasize minority perspectives over a majority. We experiment with multiple annotator selection strategies across seven subjective NLP tasks, employing both traditional and novel, human-centered evaluation metrics. Our findings indicate that ACAL improves data efficiency and excels in annotator-centric performance evaluations. However, its success depends on the availability of a sufficiently large and diverse pool of annotators to sample from.
6/26/2024

Corpus Considerations for Annotator Modeling and Scaling
Olufunke O. Sarumi, B'ela Neuendorf, Joan Plepi, Lucie Flek, Jorg Schlotterer, Charles Welch
0
0
Recent trends in natural language processing research and annotation tasks affirm a paradigm shift from the traditional reliance on a single ground truth to a focus on individual perspectives, particularly in subjective tasks. In scenarios where annotation tasks are meant to encompass diversity, models that solely rely on the majority class labels may inadvertently disregard valuable minority perspectives. This oversight could result in the omission of crucial information and, in a broader context, risk disrupting the balance within larger ecosystems. As the landscape of annotator modeling unfolds with diverse representation techniques, it becomes imperative to investigate their effectiveness with the fine-grained features of the datasets in view. This study systematically explores various annotator modeling techniques and compares their performance across seven corpora. From our findings, we show that the commonly used user token model consistently outperforms more complex models. We introduce a composite embedding approach and show distinct differences in which model performs best as a function of the agreement with a given dataset. Our findings shed light on the relationship between corpus statistics and annotator modeling performance, which informs future work on corpus construction and perspectivist NLP.
4/4/2024
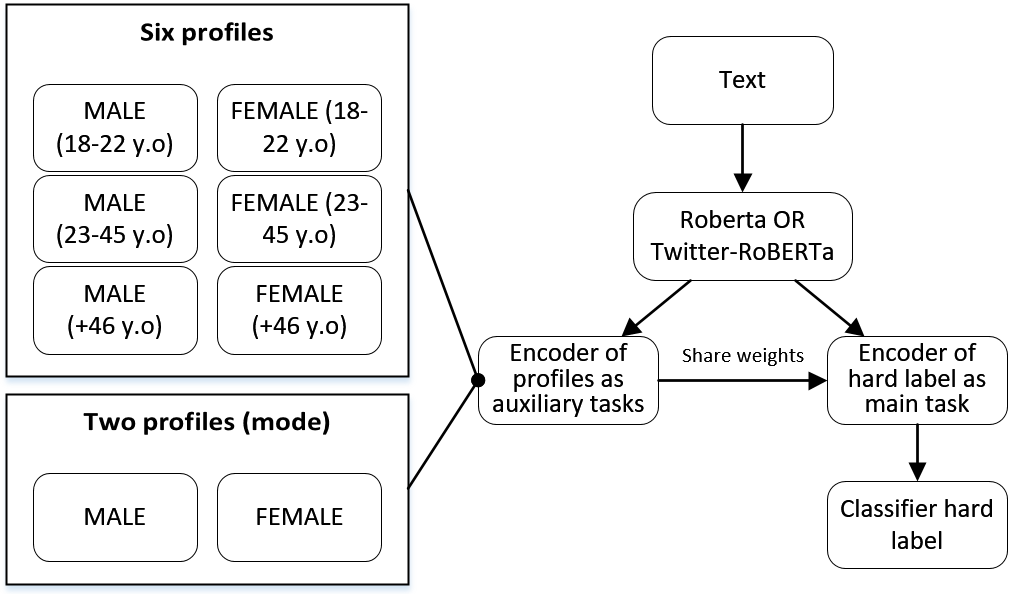
A multitask learning framework for leveraging subjectivity of annotators to identify misogyny
Jason Angel, Segun Taofeek Aroyehun, Grigori Sidorov, Alexander Gelbukh
0
0
Identifying misogyny using artificial intelligence is a form of combating online toxicity against women. However, the subjective nature of interpreting misogyny poses a significant challenge to model the phenomenon. In this paper, we propose a multitask learning approach that leverages the subjectivity of this task to enhance the performance of the misogyny identification systems. We incorporated diverse perspectives from annotators in our model design, considering gender and age across six profile groups, and conducted extensive experiments and error analysis using two language models to validate our four alternative designs of the multitask learning technique to identify misogynistic content in English tweets. The results demonstrate that incorporating various viewpoints enhances the language models' ability to interpret different forms of misogyny. This research advances content moderation and highlights the importance of embracing diverse perspectives to build effective online moderation systems.
6/26/2024