Causality for Tabular Data Synthesis: A High-Order Structure Causal Benchmark Framework

0

Sign in to get full access
Overview
- This paper introduces a high-order structure causal benchmark framework for tabular data synthesis called Causality for Tabular Data Synthesis (CTDS).
- CTDS aims to provide a comprehensive and structured evaluation of tabular data synthesis algorithms by focusing on their ability to preserve high-order causal structures in the data.
- The framework includes a set of synthetic tabular datasets with varying degrees of complexity, as well as a suite of evaluation metrics to assess the fidelity of the synthesized data.
Plain English Explanation
The researchers have developed a new benchmark framework called Causality for Tabular Data Synthesis (CTDS) to evaluate how well different algorithms can generate synthetic tabular data that preserves the underlying causal relationships in the original data.
Tabular data, which is data organized in rows and columns like a spreadsheet, often contains complex causal structures - relationships between different variables where one variable influences another. When generating synthetic data to replace real-world tabular data (for example, to protect privacy), it's important that the synthetic data maintains these causal structures so that it can be used for the same kinds of analyses and applications as the original data.
The CTDS framework includes a set of synthetic tabular datasets that have been designed to have varying levels of complexity in their causal structures. Researchers can use these datasets to test how well different data synthesis algorithms are able to preserve these high-order causal relationships in the synthetic data they generate. The framework also includes a suite of evaluation metrics to quantify how closely the synthetic data matches the original in terms of its causal structure.
By providing this comprehensive benchmark, the researchers hope to drive progress in the field of tabular data synthesis and ensure that the synthetic data being generated is a faithful representation of the real-world data it is meant to replace. This is an important step towards enabling the use of synthetic data in sensitive applications where preserving the underlying causal relationships is crucial.
Technical Explanation
The key elements of the Causality for Tabular Data Synthesis (CTDS) framework are:
-
Synthetic Datasets: The researchers have created a set of synthetic tabular datasets with varying degrees of complexity in their causal structures. These datasets cover a range of common data types and distributions, as well as different types of causal relationships, including linear, nonlinear, and high-order interactions.
-
Evaluation Metrics: The framework includes a suite of evaluation metrics to assess how well the synthesized data preserves the causal structure of the original data. These metrics measure aspects like the fidelity of the causal graph, the accuracy of causal effect estimates, and the preservation of conditional dependencies.
-
Benchmarking Procedure: Researchers can use the CTDS framework to systematically evaluate and compare the performance of different tabular data synthesis algorithms across the provided datasets and evaluation metrics. This allows for a comprehensive and structured assessment of the algorithms' abilities to preserve high-order causal structures.
The CTDS framework builds on previous work in this area, such as the Systematic Assessment of Tabular Data Synthesis Algorithms (SATDS) benchmark and the OCDB benchmark for causal discovery. However, it adds a specific focus on high-order causal structures, which are critical for many real-world applications of synthetic data, such as in the IncomesCM dataset and other domains where complex causal relationships are present.
Critical Analysis
The CTDS framework represents a valuable contribution to the field of tabular data synthesis, as it addresses an important limitation of previous benchmarks - the lack of a comprehensive evaluation of algorithms' ability to preserve high-order causal structures.
However, the paper does acknowledge some potential limitations and areas for further research:
-
Scope of Datasets: While the provided synthetic datasets cover a wide range of complexity, they may not capture all the nuances and challenges of real-world tabular data. Expanding the benchmark to include more diverse and realistic datasets could further strengthen the framework.
-
Evaluation Metrics: The proposed evaluation metrics focus on assessing causal structure preservation, but there may be other important aspects of data fidelity (e.g., statistical properties, utility for downstream tasks) that are not adequately captured. Incorporating a broader set of evaluation criteria could provide a more holistic assessment of the synthesized data.
-
Algorithm Limitations: The paper does not explore the limitations or failure modes of existing tabular data synthesis algorithms in depth. Identifying and addressing the specific challenges these algorithms face in preserving high-order causal structures could guide future research and development.
-
Real-World Validation: While the CTDS framework provides a robust synthetic benchmark, it would be valuable to also evaluate the performance of data synthesis algorithms on real-world tabular datasets with known causal structures. This could help validate the insights gained from the synthetic experiments.
Overall, the CTDS framework is a significant step forward in the evaluation of tabular data synthesis algorithms, and its focus on high-order causal structures is a crucial advance in the field. As the authors note, continued research and development in this area could have important implications for privacy-preserving data sharing, causal inference, and other applications where maintaining the underlying causal relationships is of paramount importance.
Conclusion
The Causality for Tabular Data Synthesis (CTDS) framework introduced in this paper provides a comprehensive and structured approach to evaluating the performance of tabular data synthesis algorithms in preserving high-order causal structures. By creating a set of synthetic datasets with varying degrees of complexity and developing a suite of evaluation metrics, the researchers have established a valuable benchmark for driving progress in this important area of research.
The CTDS framework builds on and advances previous work in tabular data synthesis evaluation, addressing a key limitation of not adequately capturing the preservation of complex causal relationships. This is a crucial advancement, as maintaining these high-order causal structures is essential for many real-world applications where synthetic data is used as a privacy-preserving alternative to sensitive, original data.
While the framework has some potential limitations, such as the scope of the synthetic datasets and the need for broader evaluation criteria, it represents a significant contribution to the field. By providing a rigorous and structured approach to benchmarking tabular data synthesis algorithms, the CTDS framework has the potential to accelerate research and development in this area, ultimately enabling the generation of more accurate and reliable synthetic data that can be safely used in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Causality for Tabular Data Synthesis: A High-Order Structure Causal Benchmark Framework
Ruibo Tu, Zineb Senane, Lele Cao, Cheng Zhang, Hedvig Kjellstrom, Gustav Eje Henter
Tabular synthesis models remain ineffective at capturing complex dependencies, and the quality of synthetic data is still insufficient for comprehensive downstream tasks, such as prediction under distribution shifts, automated decision-making, and cross-table understanding. A major challenge is the lack of prior knowledge about underlying structures and high-order relationships in tabular data. We argue that a systematic evaluation on high-order structural information for tabular data synthesis is the first step towards solving the problem. In this paper, we introduce high-order structural causal information as natural prior knowledge and provide a benchmark framework for the evaluation of tabular synthesis models. The framework allows us to generate benchmark datasets with a flexible range of data generation processes and to train tabular synthesis models using these datasets for further evaluation. We propose multiple benchmark tasks, high-order metrics, and causal inference tasks as downstream tasks for evaluating the quality of synthetic data generated by the trained models. Our experiments demonstrate to leverage the benchmark framework for evaluating the model capability of capturing high-order structural causal information. Furthermore, our benchmarking results provide an initial assessment of state-of-the-art tabular synthesis models. They have clearly revealed significant gaps between ideal and actual performance and how baseline methods differ. Our benchmark framework is available at URL https://github.com/TURuibo/CauTabBench.
Read more7/8/2024
0
Structured Evaluation of Synthetic Tabular Data
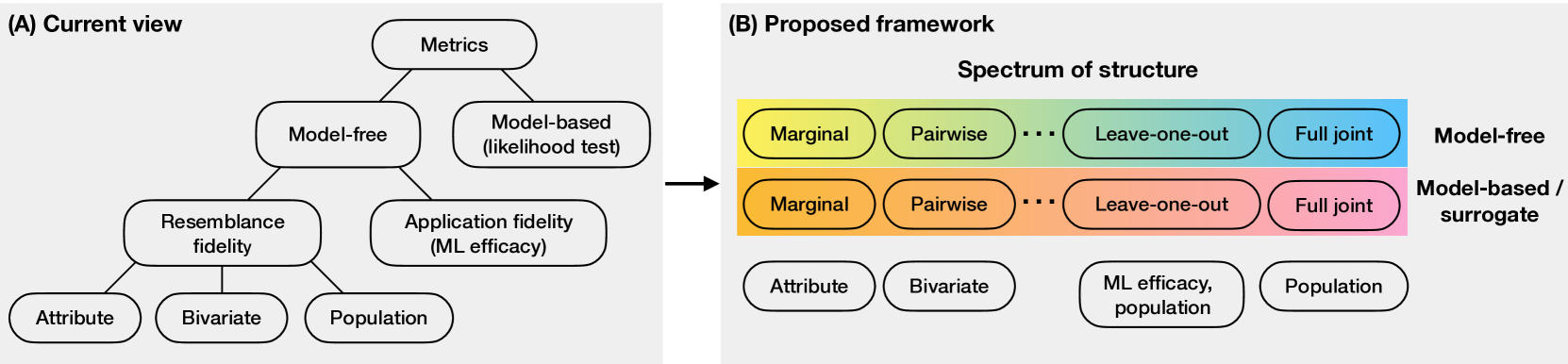
Scott Cheng-Hsin Yang, Baxter Eaves, Michael Schmidt, Ken Swanson, Patrick Shafto
Tabular data is common yet typically incomplete, small in volume, and access-restricted due to privacy concerns. Synthetic data generation offers potential solutions. Many metrics exist for evaluating the quality of synthetic tabular data; however, we lack an objective, coherent interpretation of the many metrics. To address this issue, we propose an evaluation framework with a single, mathematical objective that posits that the synthetic data should be drawn from the same distribution as the observed data. Through various structural decomposition of the objective, this framework allows us to reason for the first time the completeness of any set of metrics, as well as unifies existing metrics, including those that stem from fidelity considerations, downstream application, and model-based approaches. Moreover, the framework motivates model-free baselines and a new spectrum of metrics. We evaluate structurally informed synthesizers and synthesizers powered by deep learning. Using our structured framework, we show that synthetic data generators that explicitly represent tabular structure outperform other methods, especially on smaller datasets.
Read more4/1/2024
0
Systematic Assessment of Tabular Data Synthesis Algorithms
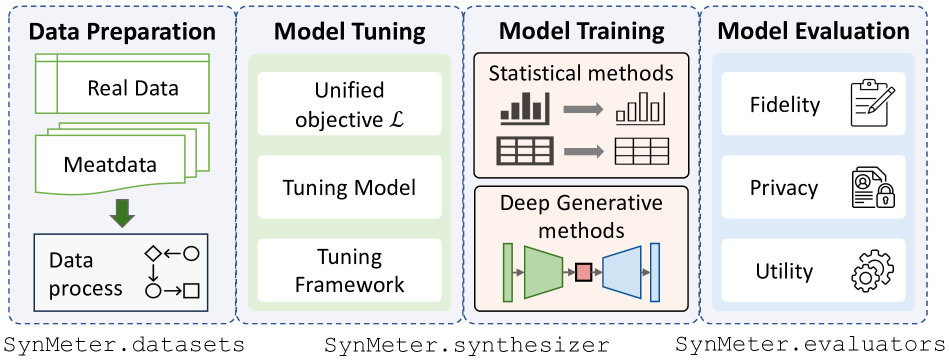
Yuntao Du, Ninghui Li
Data synthesis has been advocated as an important approach for utilizing data while protecting data privacy. A large number of tabular data synthesis algorithms (which we call synthesizers) have been proposed. Some synthesizers satisfy Differential Privacy, while others aim to provide privacy in a heuristic fashion. A comprehensive understanding of the strengths and weaknesses of these synthesizers remains elusive due to drawbacks in evaluation metrics and missing head-to-head comparisons of newly developed synthesizers that take advantage of diffusion models and large language models with state-of-the-art marginal-based synthesizers. In this paper, we present a systematic evaluation framework for assessing tabular data synthesis algorithms. Specifically, we examine and critique existing evaluation metrics, and introduce a set of new metrics in terms of fidelity, privacy, and utility to address their limitations. Based on the proposed metrics, we also devise a unified objective for tuning, which can consistently improve the quality of synthetic data for all methods. We conducted extensive evaluations of 8 different types of synthesizers on 12 real-world datasets and identified some interesting findings, which offer new directions for privacy-preserving data synthesis.
Read more4/16/2024

0
OCDB: Revisiting Causal Discovery with a Comprehensive Benchmark and Evaluation Framework
Wei Zhou, Hong Huang, Guowen Zhang, Ruize Shi, Kehan Yin, Yuanyuan Lin, Bang Liu
Large language models (LLMs) have excelled in various natural language processing tasks, but challenges in interpretability and trustworthiness persist, limiting their use in high-stakes fields. Causal discovery offers a promising approach to improve transparency and reliability. However, current evaluations are often one-sided and lack assessments focused on interpretability performance. Additionally, these evaluations rely on synthetic data and lack comprehensive assessments of real-world datasets. These lead to promising methods potentially being overlooked. To address these issues, we propose a flexible evaluation framework with metrics for evaluating differences in causal structures and causal effects, which are crucial attributes that help improve the interpretability of LLMs. We introduce the Open Causal Discovery Benchmark (OCDB), based on real data, to promote fair comparisons and drive optimization of algorithms. Additionally, our new metrics account for undirected edges, enabling fair comparisons between Directed Acyclic Graphs (DAGs) and Completed Partially Directed Acyclic Graphs (CPDAGs). Experimental results show significant shortcomings in existing algorithms' generalization capabilities on real data, highlighting the potential for performance improvement and the importance of our framework in advancing causal discovery techniques.
Read more6/10/2024