CMB: A Comprehensive Medical Benchmark in Chinese
2308.08833
0
0
📶
Abstract
Large Language Models (LLMs) provide a possibility to make a great breakthrough in medicine. The establishment of a standardized medical benchmark becomes a fundamental cornerstone to measure progression. However, medical environments in different regions have their local characteristics, e.g., the ubiquity and significance of traditional Chinese medicine within China. Therefore, merely translating English-based medical evaluation may result in textit{contextual incongruities} to a local region. To solve the issue, we propose a localized medical benchmark called CMB, a Comprehensive Medical Benchmark in Chinese, designed and rooted entirely within the native Chinese linguistic and cultural framework. While traditional Chinese medicine is integral to this evaluation, it does not constitute its entirety. Using this benchmark, we have evaluated several prominent large-scale LLMs, including ChatGPT, GPT-4, dedicated Chinese LLMs, and LLMs specialized in the medical domain. We hope this benchmark provide first-hand experience in existing LLMs for medicine and also facilitate the widespread adoption and enhancement of medical LLMs within China. Our data and code are publicly available at https://github.com/FreedomIntelligence/CMB.
Create account to get full access
Overview
- Researchers propose a new medical benchmark called CMB (Comprehensive Medical Benchmark) in Chinese to address the unique needs of the Chinese healthcare system, including the role of traditional Chinese medicine.
- The benchmark is designed to evaluate the performance of large language models (LLMs) in the medical domain, providing a standardized way to measure their capabilities.
- The researchers evaluate several prominent LLMs, including ChatGPT, GPT-4, dedicated Chinese LLMs, and LLMs specialized in the medical domain.
Plain English Explanation
Large language models (LLMs) have the potential to make significant breakthroughs in the field of medicine. However, the unique characteristics of medical environments in different regions, such as the prevalence of traditional Chinese medicine in China, can create challenges when using English-based medical evaluations. To address this, the researchers have developed a new medical benchmark called CMB, which is designed specifically for the Chinese language and cultural context.
The CMB benchmark aims to provide a standardized way to measure the performance of LLMs in the medical domain, taking into account the nuances of traditional Chinese medicine. By using this benchmark, the researchers have evaluated several prominent LLMs, including ChatGPT, GPT-4, and LLMs specialized in the medical domain.
The goal of this research is to provide first-hand insights into the capabilities of existing LLMs in the medical field, particularly within the Chinese context. The researchers hope that this benchmark will facilitate the widespread adoption and enhancement of medical LLMs in China, ultimately leading to improved healthcare outcomes.
Technical Explanation
The researchers have developed the Comprehensive Medical Benchmark (CMB) in Chinese, which is designed to evaluate the performance of large language models (LLMs) in the medical domain. The CMB is rooted in the native Chinese linguistic and cultural framework, taking into account the integral role of traditional Chinese medicine within the Chinese healthcare system.
The researchers have used the CMB to assess the capabilities of several prominent LLMs, including ChatGPT, GPT-4, dedicated Chinese LLMs, and LLMs specialized in the medical domain. By using this standardized benchmark, the researchers aim to provide a comprehensive understanding of the current state of LLM performance in the Chinese medical context.
The CMB benchmark is designed to address the contextual incongruities that may arise when using English-based medical evaluations in a local region with unique linguistic and cultural characteristics. By rooting the benchmark entirely within the Chinese framework, the researchers seek to ensure the relevance and validity of the evaluation for the Chinese healthcare system.
Critical Analysis
The researchers acknowledge that the CMB benchmark is a localized solution, and its applicability may be limited to the Chinese context. While the inclusion of traditional Chinese medicine is a strength of the benchmark, it may also pose challenges in terms of generalizability to other regions or healthcare systems.
Additionally, the researchers have only evaluated a limited set of LLMs, and the benchmark may not capture the full range of capabilities and limitations of these models. Further research is needed to expand the evaluation to a more diverse set of LLMs and to explore the potential biases or limitations that may be inherent in the benchmark design.
It is also worth considering the potential ethical and societal implications of using LLMs in the medical domain, particularly in terms of patient privacy, data security, and the potential for biased or inaccurate medical advice. The researchers do not address these concerns in depth, and further exploration of these issues would be valuable.
Conclusion
The researchers have developed the Comprehensive Medical Benchmark (CMB) in Chinese, a standardized evaluation tool designed to assess the performance of large language models (LLMs) in the medical domain within the Chinese context. By using the CMB, the researchers have provided insights into the capabilities of several prominent LLMs, including ChatGPT, GPT-4, and LLMs specialized in the medical field.
The CMB benchmark addresses the unique needs of the Chinese healthcare system, including the integral role of traditional Chinese medicine. The researchers hope that this benchmark will facilitate the widespread adoption and enhancement of medical LLMs in China, ultimately leading to improved healthcare outcomes. However, the localized nature of the benchmark and the potential ethical implications of using LLMs in the medical domain warrant further investigation and discussion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

TCMBench: A Comprehensive Benchmark for Evaluating Large Language Models in Traditional Chinese Medicine
Wenjing Yue, Xiaoling Wang, Wei Zhu, Ming Guan, Huanran Zheng, Pengfei Wang, Changzhi Sun, Xin Ma
0
0
Large language models (LLMs) have performed remarkably well in various natural language processing tasks by benchmarking, including in the Western medical domain. However, the professional evaluation benchmarks for LLMs have yet to be covered in the traditional Chinese medicine(TCM) domain, which has a profound history and vast influence. To address this research gap, we introduce TCM-Bench, an comprehensive benchmark for evaluating LLM performance in TCM. It comprises the TCM-ED dataset, consisting of 5,473 questions sourced from the TCM Licensing Exam (TCMLE), including 1,300 questions with authoritative analysis. It covers the core components of TCMLE, including TCM basis and clinical practice. To evaluate LLMs beyond accuracy of question answering, we propose TCMScore, a metric tailored for evaluating the quality of answers generated by LLMs for TCM related questions. It comprehensively considers the consistency of TCM semantics and knowledge. After conducting comprehensive experimental analyses from diverse perspectives, we can obtain the following findings: (1) The unsatisfactory performance of LLMs on this benchmark underscores their significant room for improvement in TCM. (2) Introducing domain knowledge can enhance LLMs' performance. However, for in-domain models like ZhongJing-TCM, the quality of generated analysis text has decreased, and we hypothesize that their fine-tuning process affects the basic LLM capabilities. (3) Traditional metrics for text generation quality like Rouge and BertScore are susceptible to text length and surface semantic ambiguity, while domain-specific metrics such as TCMScore can further supplement and explain their evaluation results. These findings highlight the capabilities and limitations of LLMs in the TCM and aim to provide a more profound assistance to medical research.
6/4/2024
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Anshul Thakur, Lei Clifton, David A. Clifton
0
0
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and complex clinical tasks that are close to real-world practice, i.e., referral QA, treatment recommendation, hospitalization (long document) summarization, patient education, pharmacology QA and drug interaction for emerging drugs. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs.
6/27/2024
CliBench: Multifaceted Evaluation of Large Language Models in Clinical Decisions on Diagnoses, Procedures, Lab Tests Orders and Prescriptions
Mingyu Derek Ma, Chenchen Ye, Yu Yan, Xiaoxuan Wang, Peipei Ping, Timothy S Chang, Wei Wang
0
0
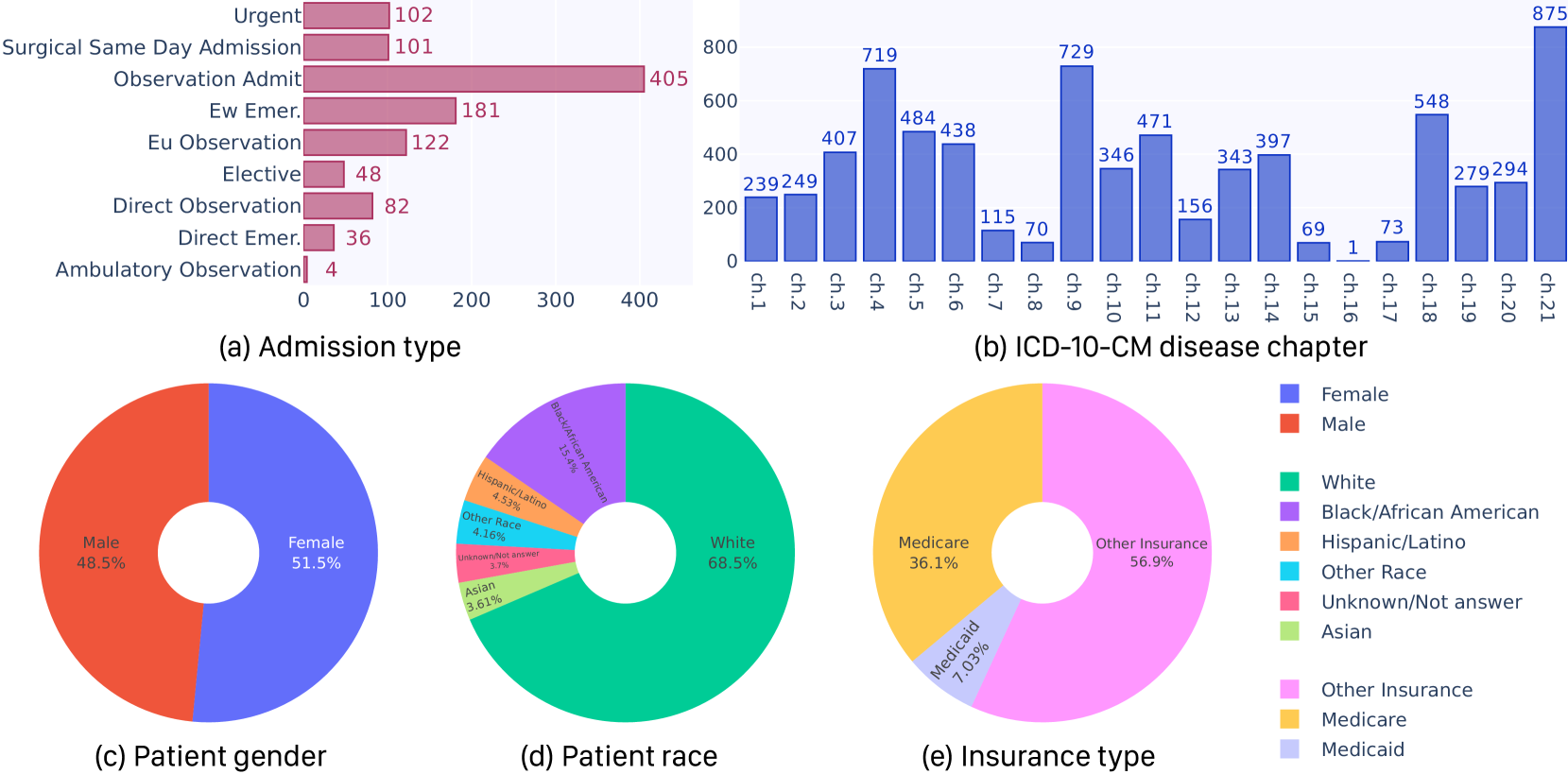
The integration of Artificial Intelligence (AI), especially Large Language Models (LLMs), into the clinical diagnosis process offers significant potential to improve the efficiency and accessibility of medical care. While LLMs have shown some promise in the medical domain, their application in clinical diagnosis remains underexplored, especially in real-world clinical practice, where highly sophisticated, patient-specific decisions need to be made. Current evaluations of LLMs in this field are often narrow in scope, focusing on specific diseases or specialties and employing simplified diagnostic tasks. To bridge this gap, we introduce CliBench, a novel benchmark developed from the MIMIC IV dataset, offering a comprehensive and realistic assessment of LLMs' capabilities in clinical diagnosis. This benchmark not only covers diagnoses from a diverse range of medical cases across various specialties but also incorporates tasks of clinical significance: treatment procedure identification, lab test ordering and medication prescriptions. Supported by structured output ontologies, CliBench enables a precise and multi-granular evaluation, offering an in-depth understanding of LLM's capability on diverse clinical tasks of desired granularity. We conduct a zero-shot evaluation of leading LLMs to assess their proficiency in clinical decision-making. Our preliminary results shed light on the potential and limitations of current LLMs in clinical settings, providing valuable insights for future advancements in LLM-powered healthcare.
6/17/2024
💬
A Survey of Large Language Models in Medicine: Progress, Application, and Challenge
Hongjian Zhou, Fenglin Liu, Boyang Gu, Xinyu Zou, Jinfa Huang, Jinge Wu, Yiru Li, Sam S. Chen, Peilin Zhou, Junling Liu, Yining Hua, Chengfeng Mao, Chenyu You, Xian Wu, Yefeng Zheng, Lei Clifton, Zheng Li, Jiebo Luo, David A. Clifton
0
0
Large language models (LLMs), such as ChatGPT, have received substantial attention due to their capabilities for understanding and generating human language. While there has been a burgeoning trend in research focusing on the employment of LLMs in supporting different medical tasks (e.g., enhancing clinical diagnostics and providing medical education), a review of these efforts, particularly their development, practical applications, and outcomes in medicine, remains scarce. Therefore, this review aims to provide a detailed overview of the development and deployment of LLMs in medicine, including the challenges and opportunities they face. In terms of development, we provide a detailed introduction to the principles of existing medical LLMs, including their basic model structures, number of parameters, and sources and scales of data used for model development. It serves as a guide for practitioners in developing medical LLMs tailored to their specific needs. In terms of deployment, we offer a comparison of the performance of different LLMs across various medical tasks, and further compare them with state-of-the-art lightweight models, aiming to provide an understanding of the advantages and limitations of LLMs in medicine. Overall, in this review, we address the following questions: 1) What are the practices for developing medical LLMs 2) How to measure the medical task performance of LLMs in a medical setting? 3) How have medical LLMs been employed in real-world practice? 4) What challenges arise from the use of medical LLMs? and 5) How to more effectively develop and deploy medical LLMs? By answering these questions, this review aims to provide insights into the opportunities for LLMs in medicine and serve as a practical resource. We also maintain a regularly updated list of practical guides on medical LLMs at: https://github.com/AI-in-Health/MedLLMsPracticalGuide.
5/16/2024