Characterizing Data Point Vulnerability via Average-Case Robustness

0
📊
Sign in to get full access
Overview
- Robustness is a crucial property for machine learning models to ensure consistent behavior in real-world settings.
- Adversarial robustness is a standard framework that views robustness through a binary lens, but this does not account for the degrees of vulnerability.
- The paper proposes a complementary framework called average-case robustness, which measures the fraction of points in a local region that provide consistent predictions.
- Computing average-case robustness is challenging, so the paper introduces analytical estimators to efficiently approximate this metric for multi-class classifiers.
Plain English Explanation
Robustness is an important property for machine learning models to have, as it ensures the models behave consistently across different real-world situations. The standard way to assess robustness is through adversarial robustness, which looks at whether a worst-case adversarial misclassification exists near an input. However, this binary view doesn't account for the varying degrees of vulnerability - some data points may have many more misclassified examples in their neighborhoods, making them more vulnerable.
To address this, the paper proposes a new framework called "average-case robustness," which measures the fraction of points in a local region that are classified consistently. This provides a more nuanced view of robustness. But computing average-case robustness is challenging, as standard approaches are inefficient, especially for high-dimensional data.
The key innovation in this paper is the development of analytical estimators that can efficiently approximate average-case robustness for multi-class classifiers. These estimators allow researchers and practitioners to better characterize the robustness of their models and identify vulnerable data points. Overall, this work provides a complementary perspective on model robustness, giving us a more comprehensive understanding of how machine learning systems behave.
Technical Explanation
The paper introduces a new framework for assessing the robustness of machine learning models called "average-case robustness." Unlike the standard adversarial robustness perspective, which views robustness through a binary lens, average-case robustness measures the fraction of points in a local region around an input that are consistently classified.
Computing this average-case robustness metric exactly is computationally expensive, especially for high-dimensional data, as it requires sampling many points in the local region. To address this, the authors develop the first analytical estimators for average-case robustness for multi-class classifiers. These estimators leverage the structure of the classifier and the data distribution to provide accurate and efficient approximations of the true average-case robustness.
The authors demonstrate the effectiveness of their estimators on standard deep learning models, showing that they can accurately quantify robustness and identify vulnerable data points. They also use the estimators to uncover robustness biases in models, where certain groups of examples may be more vulnerable than others.
Critical Analysis
The paper presents a promising new framework for analyzing the robustness of machine learning models, but there are a few important caveats to consider:
-
The analytical estimators developed in the paper rely on certain assumptions about the classifier and data distribution that may not always hold in practice. The authors acknowledge this and suggest directions for further research to relax these assumptions.
-
The paper focuses on multi-class classification tasks, but many real-world machine learning applications involve more complex prediction problems, such as regression or structured prediction. Extending the average-case robustness framework to these settings is an important area for future work.
-
While the paper demonstrates the usefulness of the average-case robustness estimators, more research is needed to understand the practical implications of this metric and how it relates to other notions of model robustness and model behavior.
Overall, this paper represents an important step forward in the study of model robustness, providing a complementary perspective that could lead to a more comprehensive understanding of neural network behavior. As with any research, there is room for further exploration and refinement, but the authors have laid the groundwork for an exciting new direction in this critical area of machine learning.
Conclusion
This paper introduces a new framework for assessing the robustness of machine learning models called "average-case robustness." Unlike the standard adversarial robustness perspective, average-case robustness measures the fraction of points in a local region around an input that are consistently classified, providing a more nuanced view of model behavior.
To efficiently compute this average-case robustness metric, the authors developed analytical estimators that leverage the structure of the classifier and data distribution. They demonstrated the effectiveness of these estimators on standard deep learning models, showing their ability to accurately quantify robustness and identify vulnerable data points.
By offering a complementary lens for understanding model robustness, this work represents an important contribution to the field of machine learning. The insights and tools developed in this paper can help researchers and practitioners better characterize the behavior of their models, ultimately leading to more robust and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Characterizing Data Point Vulnerability via Average-Case Robustness
Tessa Han, Suraj Srinivas, Himabindu Lakkaraju
Studying the robustness of machine learning models is important to ensure consistent model behaviour across real-world settings. To this end, adversarial robustness is a standard framework, which views robustness of predictions through a binary lens: either a worst-case adversarial misclassification exists in the local region around an input, or it does not. However, this binary perspective does not account for the degrees of vulnerability, as data points with a larger number of misclassified examples in their neighborhoods are more vulnerable. In this work, we consider a complementary framework for robustness, called average-case robustness, which measures the fraction of points in a local region that provides consistent predictions. However, computing this quantity is hard, as standard Monte Carlo approaches are inefficient especially for high-dimensional inputs. In this work, we propose the first analytical estimators for average-case robustness for multi-class classifiers. We show empirically that our estimators are accurate and efficient for standard deep learning models and demonstrate their usefulness for identifying vulnerable data points, as well as quantifying robustness bias of models. Overall, our tools provide a complementary view to robustness, improving our ability to characterize model behaviour.
Read more5/31/2024
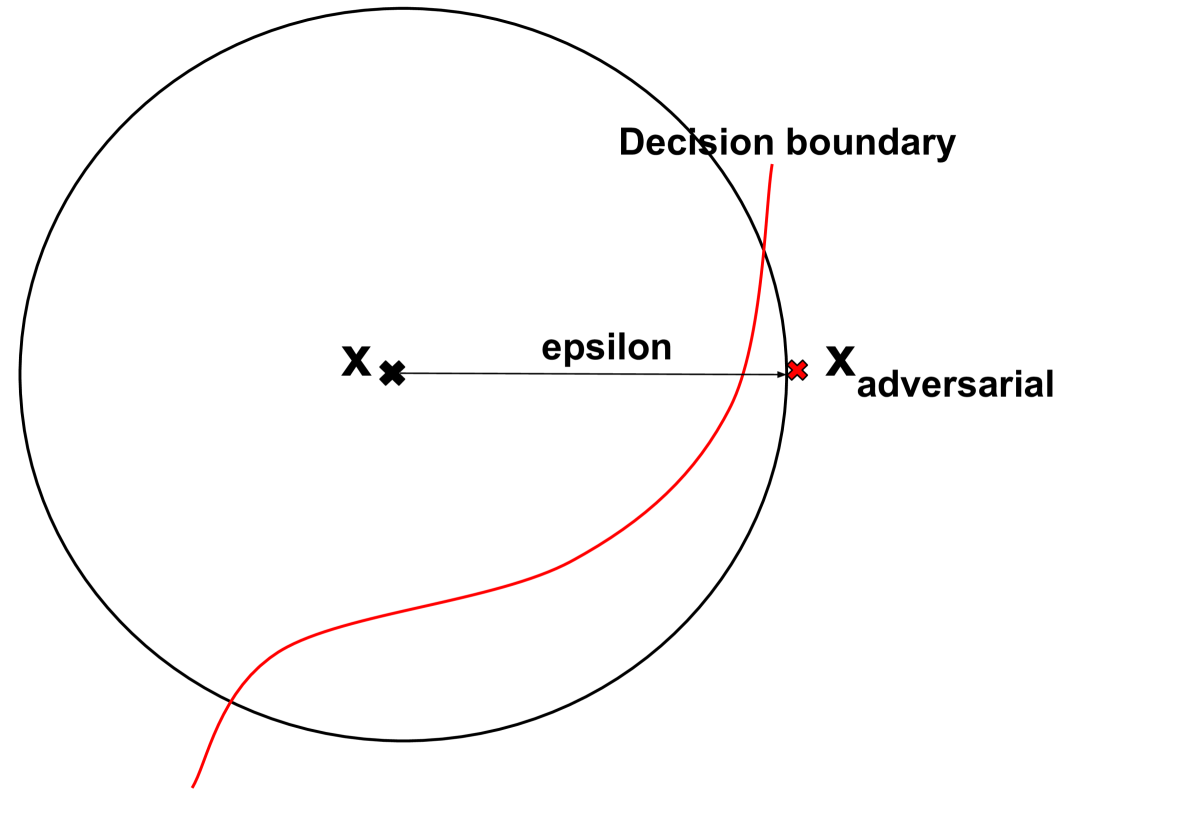
0
A practical approach to evaluating the adversarial distance for machine learning classifiers
Georg Siedel, Ekagra Gupta, Andrey Morozov
Robustness is critical for machine learning (ML) classifiers to ensure consistent performance in real-world applications where models may encounter corrupted or adversarial inputs. In particular, assessing the robustness of classifiers to adversarial inputs is essential to protect systems from vulnerabilities and thus ensure safety in use. However, methods to accurately compute adversarial robustness have been challenging for complex ML models and high-dimensional data. Furthermore, evaluations typically measure adversarial accuracy on specific attack budgets, limiting the informative value of the resulting metrics. This paper investigates the estimation of the more informative adversarial distance using iterative adversarial attacks and a certification approach. Combined, the methods provide a comprehensive evaluation of adversarial robustness by computing estimates for the upper and lower bounds of the adversarial distance. We present visualisations and ablation studies that provide insights into how this evaluation method should be applied and parameterised. We find that our adversarial attack approach is effective compared to related implementations, while the certification method falls short of expectations. The approach in this paper should encourage a more informative way of evaluating the adversarial robustness of ML classifiers.
Read more9/6/2024
👀
0
Assessing Robustness of Machine Learning Models using Covariate Perturbations
Arun Prakash R, Anwesha Bhattacharyya, Joel Vaughan, Vijayan N. Nair
As machine learning models become increasingly prevalent in critical decision-making models and systems in fields like finance, healthcare, etc., ensuring their robustness against adversarial attacks and changes in the input data is paramount, especially in cases where models potentially overfit. This paper proposes a comprehensive framework for assessing the robustness of machine learning models through covariate perturbation techniques. We explore various perturbation strategies to assess robustness and examine their impact on model predictions, including separate strategies for numeric and non-numeric variables, summaries of perturbations to assess and compare model robustness across different scenarios, and local robustness diagnosis to identify any regions in the data where a model is particularly unstable. Through empirical studies on real world dataset, we demonstrate the effectiveness of our approach in comparing robustness across models, identifying the instabilities in the model, and enhancing model robustness.
Read more8/6/2024
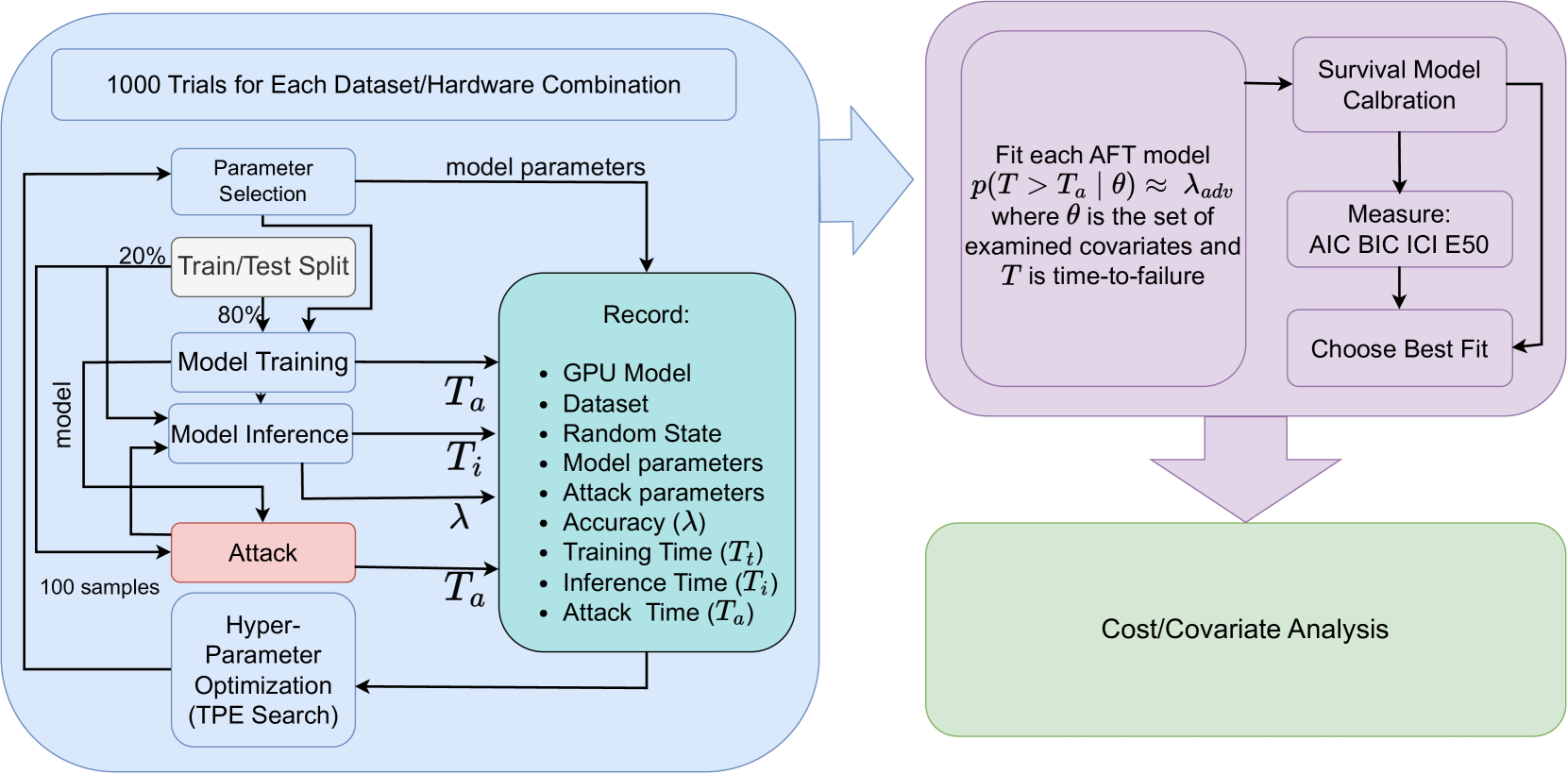
0
A Cost-Aware Approach to Adversarial Robustness in Neural Networks
Charles Meyers, Mohammad Reza Saleh Sedghpour, Tommy Lofstedt, Erik Elmroth
Considering the growing prominence of production-level AI and the threat of adversarial attacks that can evade a model at run-time, evaluating the robustness of models to these evasion attacks is of critical importance. Additionally, testing model changes likely means deploying the models to (e.g. a car or a medical imaging device), or a drone to see how it affects performance, making un-tested changes a public problem that reduces development speed, increases cost of development, and makes it difficult (if not impossible) to parse cause from effect. In this work, we used survival analysis as a cloud-native, time-efficient and precise method for predicting model performance in the presence of adversarial noise. For neural networks in particular, the relationships between the learning rate, batch size, training time, convergence time, and deployment cost are highly complex, so researchers generally rely on benchmark datasets to assess the ability of a model to generalize beyond the training data. To address this, we propose using accelerated failure time models to measure the effect of hardware choice, batch size, number of epochs, and test-set accuracy by using adversarial attacks to induce failures on a reference model architecture before deploying the model to the real world. We evaluate several GPU types and use the Tree Parzen Estimator to maximize model robustness and minimize model run-time simultaneously. This provides a way to evaluate the model and optimise it in a single step, while simultaneously allowing us to model the effect of model parameters on training time, prediction time, and accuracy. Using this technique, we demonstrate that newer, more-powerful hardware does decrease the training time, but with a monetary and power cost that far outpaces the marginal gains in accuracy.
Read more9/14/2024