ChEX: Interactive Localization and Region Description in Chest X-rays

0
Sign in to get full access
Overview
- This paper presents ChEX, a novel interactive system for localization and description of regions in chest X-ray (CXR) images.
- ChEX allows users to interactively select regions of interest in CXR images and generates natural language descriptions of the selected regions.
- The system uses vision-language models to enable this interaction and report generation, leveraging advancements in both computer vision and natural language processing.
Plain English Explanation
ChEX: Interactive Localization and Region Description in Chest X-rays is a new tool that helps doctors and radiologists work with chest X-ray (CXR) images more easily. With ChEX, users can select specific areas of interest in a CXR image and get a plain-language description of what's happening in that region.
This is possible because ChEX uses advanced AI models that combine computer vision (to understand the visual elements in the image) and natural language processing (to generate the descriptions). So, instead of just looking at a complex medical image, the doctor can quickly get helpful information about the key features and abnormalities in the areas they're focusing on.
This type of interactive system could be very useful for clinical workflows involving CXR analysis, allowing doctors to more efficiently identify and communicate the relevant findings. It builds on recent progress in explaining chest X-ray pathology models and could potentially integrate with larger language model frameworks for medical imaging.
Technical Explanation
ChEX: Interactive Localization and Region Description in Chest X-rays presents a novel system that allows users to interactively select regions of interest in chest X-ray (CXR) images and generates natural language descriptions of the selected regions.
The system uses a vision-language model architecture that consists of a visual encoder (e.g., a convolutional neural network) to process the CXR image, and a language model (e.g., a transformer-based model) to generate the region descriptions. The visual encoder and language model are jointly trained end-to-end on a dataset of CXR images paired with annotated region descriptions.
During interactive use, the user can click on regions of the CXR image, and the system will generate a textual description of the selected region. The descriptions are generated conditioned on the visual input and the user's selected region, allowing the system to provide targeted, informative feedback.
The authors evaluate ChEX on a dataset of CXR images with region-level annotations, showing that the system can generate accurate and coherent descriptions of user-specified regions. Additionally, they demonstrate the system's potential for clinical workflows through a user study with radiologists.
Critical Analysis
The ChEX paper presents a promising approach for interactive localization and description of regions in chest X-ray images. However, the authors acknowledge some limitations and areas for further research:
-
The system was trained and evaluated on a single dataset, so its generalization to other CXR datasets or clinical settings is unclear. Further research on the system's broader applicability would be valuable.
-
The authors do not provide detailed information on the performance of the underlying vision and language models. Evaluating the individual model components could offer insights into the system's strengths and weaknesses.
-
While the user study with radiologists suggests the system's potential utility, a larger-scale clinical evaluation would be necessary to fully assess its impact on real-world workflows and decision-making.
-
The paper does not address potential concerns around the interpretability and explainability of the system's outputs, which could be important for building trust and adoption in a medical setting.
Overall, the ChEX system represents an exciting step forward in leveraging vision-language models for interactive medical image analysis. Further research and development in this area could lead to more powerful tools for radiologists and physicians to efficiently and effectively interpret chest X-rays.
Conclusion
ChEX: Interactive Localization and Region Description in Chest X-rays presents a novel interactive system that allows users to select regions of interest in chest X-ray images and generates natural language descriptions of the selected regions. The system combines computer vision and natural language processing techniques to enable this interactive workflow, which could be highly valuable for clinical applications involving CXR analysis.
While the paper demonstrates the potential of this approach, further research is needed to address limitations around generalization, model interpretability, and real-world clinical evaluation. Nonetheless, the ChEX system represents an important step forward in leveraging advanced AI models to enhance medical imaging workflows and improve patient care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ChEX: Interactive Localization and Region Description in Chest X-rays
Philip Muller, Georgios Kaissis, Daniel Rueckert
Report generation models offer fine-grained textual interpretations of medical images like chest X-rays, yet they often lack interactivity (i.e. the ability to steer the generation process through user queries) and localized interpretability (i.e. visually grounding their predictions), which we deem essential for future adoption in clinical practice. While there have been efforts to tackle these issues, they are either limited in their interactivity by not supporting textual queries or fail to also offer localized interpretability. Therefore, we propose a novel multitask architecture and training paradigm integrating textual prompts and bounding boxes for diverse aspects like anatomical regions and pathologies. We call this approach the Chest X-Ray Explainer (ChEX). Evaluations across a heterogeneous set of 9 chest X-ray tasks, including localized image interpretation and report generation, showcase its competitiveness with SOTA models while additional analysis demonstrates ChEX's interactive capabilities. Code: https://github.com/philip-mueller/chex
Read more7/16/2024
0
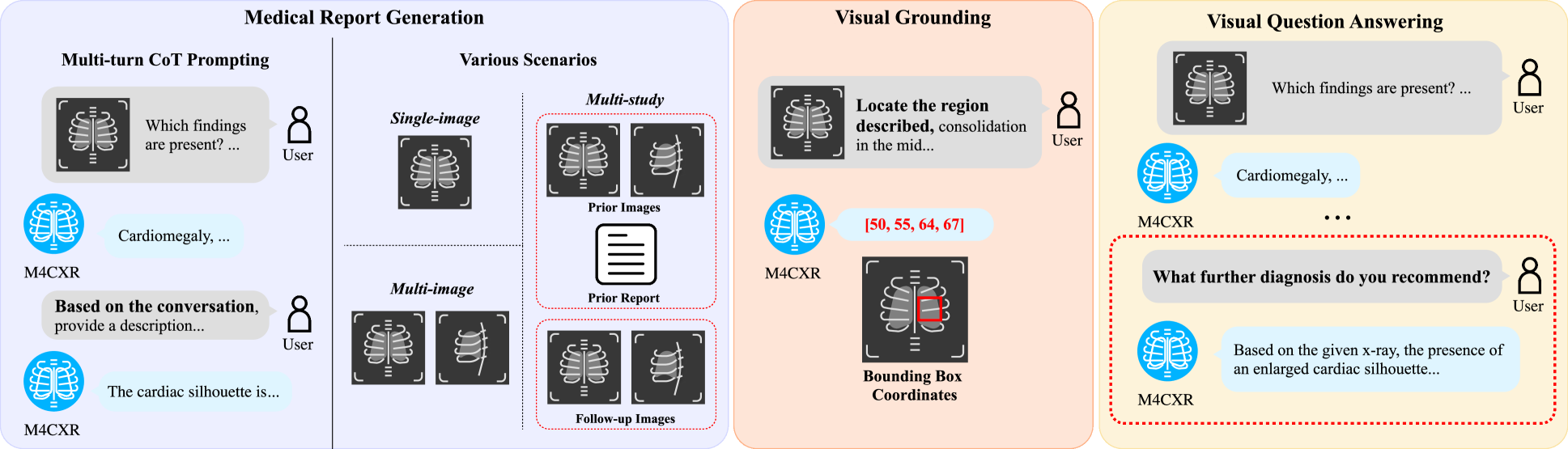
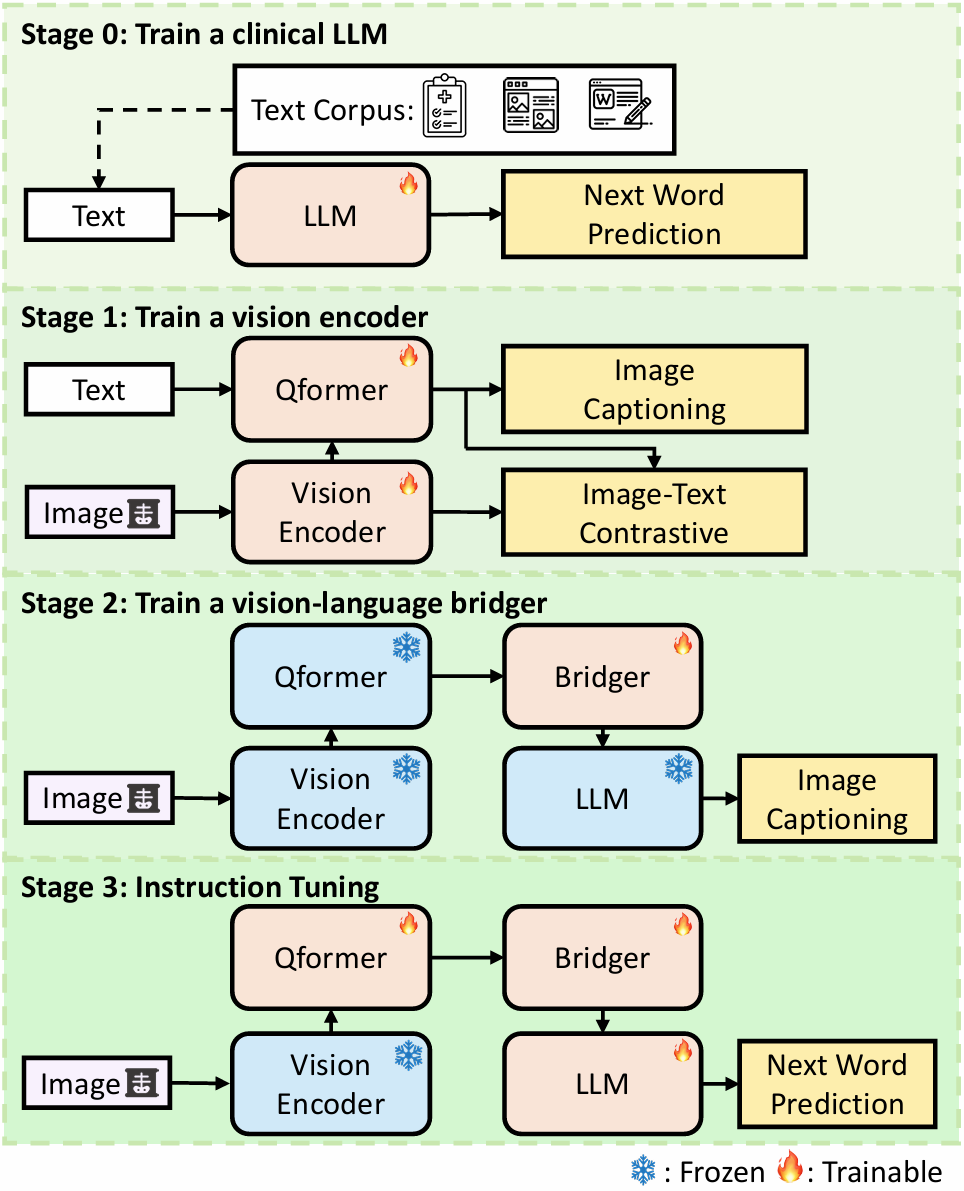
M4CXR: Exploring Multi-task Potentials of Multi-modal Large Language Models for Chest X-ray Interpretation
Jonggwon Park, Soobum Kim, Byungmu Yoon, Jihun Hyun, Kyoyun Choi
The rapid evolution of artificial intelligence, especially in large language models (LLMs), has significantly impacted various domains, including healthcare. In chest X-ray (CXR) analysis, previous studies have employed LLMs, but with limitations: either underutilizing the multi-tasking capabilities of LLMs or lacking clinical accuracy. This paper presents M4CXR, a multi-modal LLM designed to enhance CXR interpretation. The model is trained on a visual instruction-following dataset that integrates various task-specific datasets in a conversational format. As a result, the model supports multiple tasks such as medical report generation (MRG), visual grounding, and visual question answering (VQA). M4CXR achieves state-of-the-art clinical accuracy in MRG by employing a chain-of-thought prompting strategy, in which it identifies findings in CXR images and subsequently generates corresponding reports. The model is adaptable to various MRG scenarios depending on the available inputs, such as single-image, multi-image, and multi-study contexts. In addition to MRG, M4CXR performs visual grounding at a level comparable to specialized models and also demonstrates outstanding performance in VQA. Both quantitative and qualitative assessments reveal M4CXR's versatility in MRG, visual grounding, and VQA, while consistently maintaining clinical accuracy.
Read more8/30/2024
0
CXR-Agent: Vision-language models for chest X-ray interpretation with uncertainty aware radiology reporting
Naman Sharma
Recently large vision-language models have shown potential when interpreting complex images and generating natural language descriptions using advanced reasoning. Medicine's inherently multimodal nature incorporating scans and text-based medical histories to write reports makes it conducive to benefit from these leaps in AI capabilities. We evaluate the publicly available, state of the art, foundational vision-language models for chest X-ray interpretation across several datasets and benchmarks. We use linear probes to evaluate the performance of various components including CheXagent's vision transformer and Q-former, which outperform the industry-standard Torch X-ray Vision models across many different datasets showing robust generalisation capabilities. Importantly, we find that vision-language models often hallucinate with confident language, which slows down clinical interpretation. Based on these findings, we develop an agent-based vision-language approach for report generation using CheXagent's linear probes and BioViL-T's phrase grounding tools to generate uncertainty-aware radiology reports with pathologies localised and described based on their likelihood. We thoroughly evaluate our vision-language agents using NLP metrics, chest X-ray benchmarks and clinical evaluations by developing an evaluation platform to perform a user study with respiratory specialists. Our results show considerable improvements in accuracy, interpretability and safety of the AI-generated reports. We stress the importance of analysing results for normal and abnormal scans separately. Finally, we emphasise the need for larger paired (scan and report) datasets alongside data augmentation to tackle overfitting seen in these large vision-language models.
Read more7/15/2024
📊
0
Longitudinal Data and a Semantic Similarity Reward for Chest X-Ray Report Generation
Aaron Nicolson, Jason Dowling, Bevan Koopman
Radiologists face high burnout rates, partially due to the increasing volume of Chest X-rays (CXRs) requiring interpretation and reporting. Automated CXR report generation holds promise for reducing this burden and improving patient care. While current models show potential, their diagnostic accuracy is limited. Our proposed CXR report generator integrates elements of the radiologist workflow and introduces a novel reward for reinforcement learning. Our approach leverages longitudinal data from a patient's prior CXR study and effectively handles cases where no prior study exist, thus mirroring the radiologist's workflow. In contrast, existing models typically lack this flexibility, often requiring prior studies for the model to function optimally. Our approach also incorporates all CXRs from a patient's study and distinguishes between report sections through section embeddings. Our reward for reinforcement learning leverages CXR-BERT, which forces our model to learn the clinical semantics of radiology reporting. We conduct experiments on publicly available datasets -- MIMIC-CXR and Open-i IU X-ray -- with metrics shown to more closely correlate with radiologists' assessment of reporting. Results from our study demonstrate that the proposed model generates reports that are more aligned with radiologists' reports than state-of-the-art models, such as those utilising large language models, reinforcement learning, and multi-task learning. The proposed model improves the diagnostic accuracy of CXR report generation, which could one day reduce radiologists' workload and enhance patient care. Our Hugging Face checkpoint (https://huggingface.co/aehrc/cxrmate) and code (https://github.com/aehrc/cxrmate) are publicly available.
Read more6/21/2024