ChildDiffusion: Unlocking the Potential of Generative AI and Controllable Augmentations for Child Facial Data using Stable Diffusion and Large Language Models

0
Sign in to get full access
Overview
- This paper presents ChildDiffusion, a novel approach that leverages Stable Diffusion and large language models to generate synthetic child facial data and enable controllable augmentations for child facial data.
- The researchers aim to unlock the potential of generative AI for child facial data, which is crucial for developing inclusive and ethical AI systems.
- The paper explores the challenges and opportunities in this domain, offering technical insights and a critical analysis of the proposed approach.
Plain English Explanation
The researchers have developed a new method called ChildDiffusion that uses advanced AI models, such as Stable Diffusion and large language models, to create synthetic child facial data. This is an important task because child facial data is scarce and critical for building AI systems that work well for children, such as facial analysis or expression recognition models.
The researchers explain that existing generative adversarial networks (GANs) have limitations in generating high-quality and diverse child facial data. ChildDiffusion aims to overcome these challenges by leveraging the power of Stable Diffusion and language models to produce more realistic and controllable synthetic child faces.
The paper describes the technical details of the ChildDiffusion approach, including the model architecture and training process. The researchers also provide a critical analysis of the method, discussing potential limitations and areas for future research, such as ensuring the robustness and fairness of the generated data.
Technical Explanation
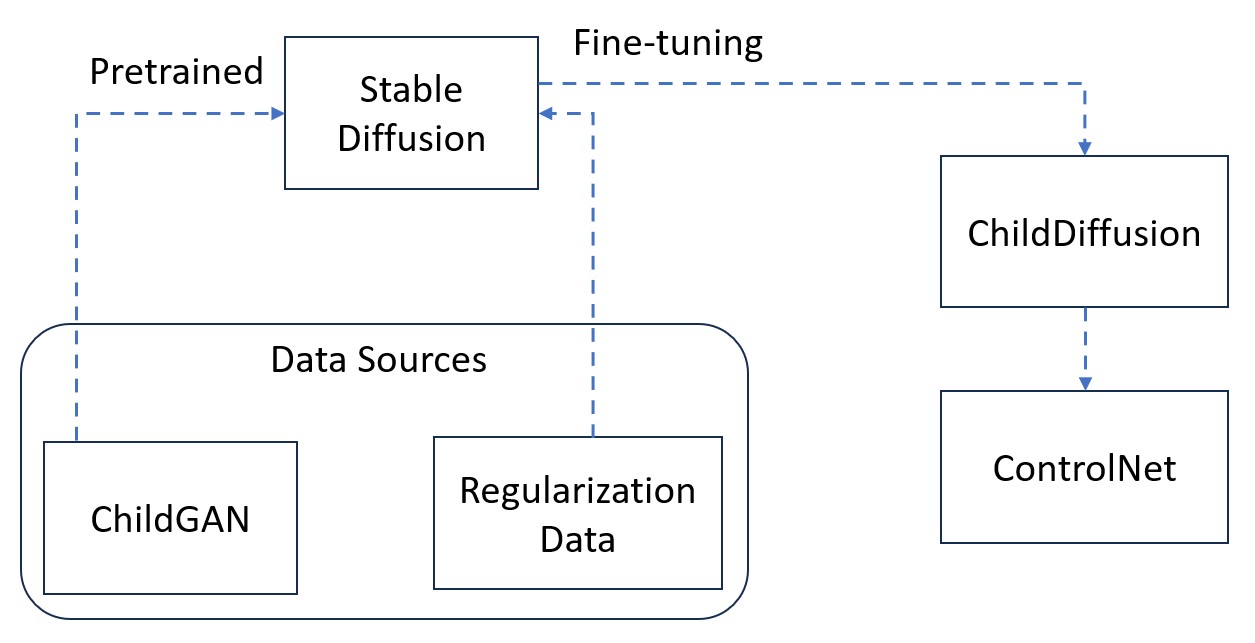
The ChildDiffusion approach utilizes Stable Diffusion, a powerful generative AI model, in combination with large language models to generate synthetic child facial data. Stable Diffusion is a diffusion-based model that can generate high-quality images from text descriptions, while the language models provide additional control and customization capabilities.
The researchers designed a novel architecture that integrates Stable Diffusion with language models to enable fine-grained control over the generated child faces. This includes the ability to adjust attributes like age, gender, and ethnicity, allowing for the creation of diverse and representative synthetic data.
The paper describes the training process, which involves a multi-stage approach to ensure the generated child faces are realistic and consistent. The researchers also explore techniques for augmenting the existing child facial data, further expanding the diversity and quality of the synthetic dataset.
The technical evaluation of ChildDiffusion demonstrates its effectiveness in generating high-quality and controllable child facial data, outperforming traditional GAN-based approaches. The researchers also discuss the potential societal impacts and ethical considerations of their work, highlighting the importance of responsible development and deployment of such generative AI technologies.
Critical Analysis
The ChildDiffusion approach represents a significant advancement in the field of generative AI for child facial data. By leveraging the strengths of Stable Diffusion and language models, the researchers have addressed some of the key limitations of existing GAN-based methods.
One potential limitation, as acknowledged in the paper, is the reliance on the quality and representativeness of the training data used to fine-tune the language models. The researchers emphasize the importance of carefully curating and validating the dataset to ensure the generated child faces are free from biases and reflect the diversity of the target population.
Additionally, the researchers mention the need for further research on the long-term stability and consistency of the generated child faces, as well as the potential for adversarial attacks or misuse of the technology. Responsible development and deployment of ChildDiffusion will be crucial to addressing these concerns and ensuring the ethical use of this technology.
The paper's critical analysis also highlights the importance of continued efforts to address the broader challenges in the field of child-centric AI development, such as data privacy, consent, and the potential for unintended consequences. The researchers encourage the research community to engage in ongoing discussions and collaborations to address these complex issues.
Conclusion
The ChildDiffusion approach represents a significant step forward in the field of generative AI for child facial data. By integrating Stable Diffusion and language models, the researchers have developed a powerful tool that can generate high-quality and controllable synthetic child faces, unlocking new possibilities for inclusive and ethical AI development.
The paper's technical insights and critical analysis provide valuable guidance for researchers and practitioners working in this domain. The successful deployment of ChildDiffusion could have far-reaching implications, enabling the creation of more diverse and representative training data for a wide range of AI applications targeting child populations.
As the field of generative AI continues to evolve, the ChildDiffusion approach serves as a promising example of how advanced techniques can be leveraged to address important societal challenges in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ChildDiffusion: Unlocking the Potential of Generative AI and Controllable Augmentations for Child Facial Data using Stable Diffusion and Large Language Models
Muhammad Ali Farooq, Wang Yao, Peter Corcoran
In this research work we have proposed high-level ChildDiffusion framework capable of generating photorealistic child facial samples and further embedding several intelligent augmentations on child facial data using short text prompts, detailed textual guidance from LLMs, and further image to image transformation using text guidance control conditioning thus providing an opportunity to curate fully synthetic large scale child datasets. The framework is validated by rendering high-quality child faces representing ethnicity data, micro expressions, face pose variations, eye blinking effects, facial accessories, different hair colours and styles, aging, multiple and different child gender subjects in a single frame. Addressing privacy concerns regarding child data acquisition requires a comprehensive approach that involves legal, ethical, and technological considerations. Keeping this in view this framework can be adapted to synthesise child facial data which can be effectively used for numerous downstream machine learning tasks. The proposed method circumvents common issues encountered in generative AI tools, such as temporal inconsistency and limited control over the rendered outputs. As an exemplary use case we have open-sourced child ethnicity data consisting of 2.5k child facial samples of five different classes which includes African, Asian, White, South Asian/ Indian, and Hispanic races by deploying the model in production inference phase. The rendered data undergoes rigorous qualitative as well as quantitative tests to cross validate its efficacy and further fine-tuning Yolo architecture for detecting and classifying child ethnicity as an exemplary downstream machine learning task.
Read more6/18/2024
🤿
0
Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation
Xiyi Chen, Marko Mihajlovic, Shaofei Wang, Sergey Prokudin, Siyu Tang
Recent advances in generative diffusion models have enabled the previously unfeasible capability of generating 3D assets from a single input image or a text prompt. In this work, we aim to enhance the quality and functionality of these models for the task of creating controllable, photorealistic human avatars. We achieve this by integrating a 3D morphable model into the state-of-the-art multi-view-consistent diffusion approach. We demonstrate that accurate conditioning of a generative pipeline on the articulated 3D model enhances the baseline model performance on the task of novel view synthesis from a single image. More importantly, this integration facilitates a seamless and accurate incorporation of facial expression and body pose control into the generation process. To the best of our knowledge, our proposed framework is the first diffusion model to enable the creation of fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject; extensive quantitative and qualitative evaluations demonstrate the advantages of our approach over existing state-of-the-art avatar creation models on both novel view and novel expression synthesis tasks. The code for our project is publicly available.
Read more4/3/2024
🔄
0
Diffusion Deepfake
Chaitali Bhattacharyya, Hanxiao Wang, Feng Zhang, Sungho Kim, Xiatian Zhu
Recent progress in generative AI, primarily through diffusion models, presents significant challenges for real-world deepfake detection. The increased realism in image details, diverse content, and widespread accessibility to the general public complicates the identification of these sophisticated deepfakes. Acknowledging the urgency to address the vulnerability of current deepfake detectors to this evolving threat, our paper introduces two extensive deepfake datasets generated by state-of-the-art diffusion models as other datasets are less diverse and low in quality. Our extensive experiments also showed that our dataset is more challenging compared to the other face deepfake datasets. Our strategic dataset creation not only challenge the deepfake detectors but also sets a new benchmark for more evaluation. Our comprehensive evaluation reveals the struggle of existing detection methods, often optimized for specific image domains and manipulations, to effectively adapt to the intricate nature of diffusion deepfakes, limiting their practical utility. To address this critical issue, we investigate the impact of enhancing training data diversity on representative detection methods. This involves expanding the diversity of both manipulation techniques and image domains. Our findings underscore that increasing training data diversity results in improved generalizability. Moreover, we propose a novel momentum difficulty boosting strategy to tackle the additional challenge posed by training data heterogeneity. This strategy dynamically assigns appropriate sample weights based on learning difficulty, enhancing the model's adaptability to both easy and challenging samples. Extensive experiments on both existing and newly proposed benchmarks demonstrate that our model optimization approach surpasses prior alternatives significantly.
Read more4/3/2024
🛸
0
Towards a Simultaneous and Granular Identity-Expression Control in Personalized Face Generation
Renshuai Liu, Bowen Ma, Wei Zhang, Zhipeng Hu, Changjie Fan, Tangjie Lv, Yu Ding, Xuan Cheng
In human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individuals while exhibiting diverse expressions. This paper introduces our efforts towards personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model that can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in the conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling, and explicitly background conditioning. Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping, and face reenactment methods.
Read more4/9/2024