Chronos: Learning the Language of Time Series
2403.07815
207
0
Abstract
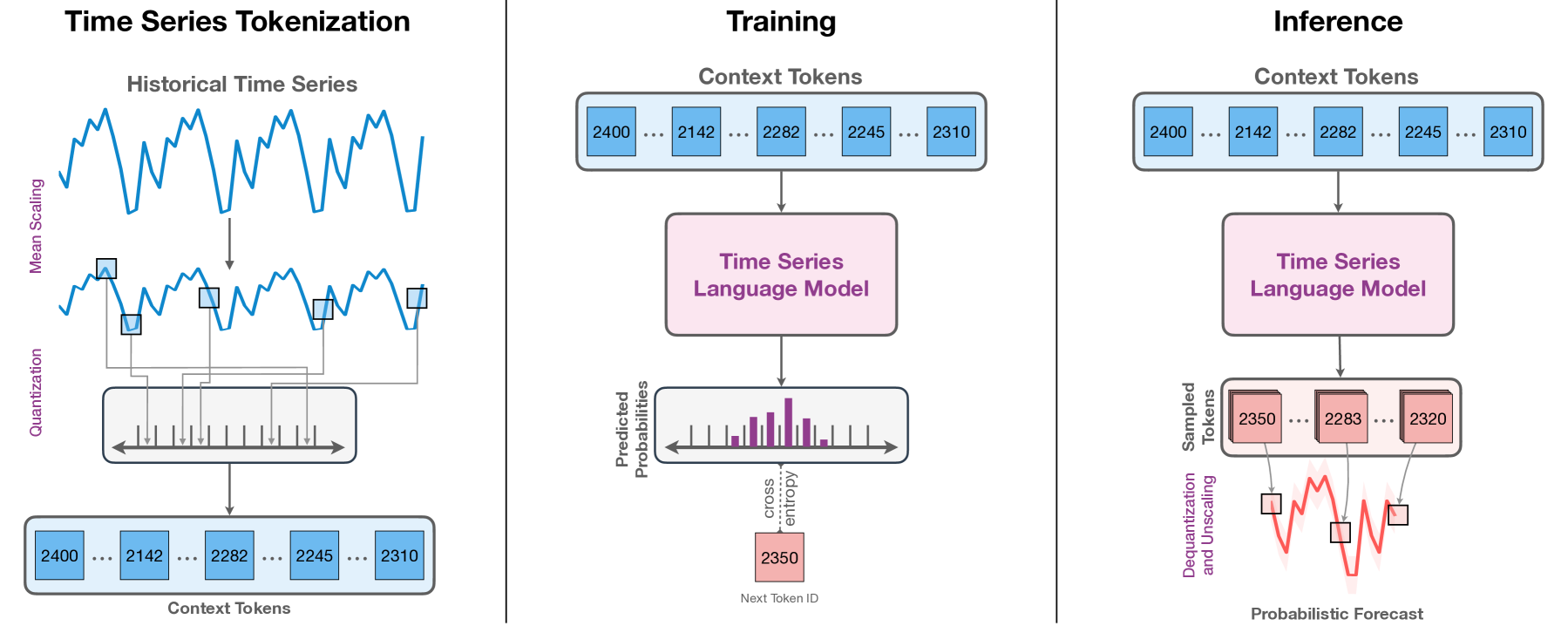
We introduce Chronos, a simple yet effective framework for pretrained probabilistic time series models. Chronos tokenizes time series values using scaling and quantization into a fixed vocabulary and trains existing transformer-based language model architectures on these tokenized time series via the cross-entropy loss. We pretrained Chronos models based on the T5 family (ranging from 20M to 710M parameters) on a large collection of publicly available datasets, complemented by a synthetic dataset that we generated via Gaussian processes to improve generalization. In a comprehensive benchmark consisting of 42 datasets, and comprising both classical local models and deep learning methods, we show that Chronos models: (a) significantly outperform other methods on datasets that were part of the training corpus; and (b) have comparable and occasionally superior zero-shot performance on new datasets, relative to methods that were trained specifically on them. Our results demonstrate that Chronos models can leverage time series data from diverse domains to improve zero-shot accuracy on unseen forecasting tasks, positioning pretrained models as a viable tool to greatly simplify forecasting pipelines.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces Chronos, a new approach to learning the "language of time series" using large language models (LLMs).
- The researchers explore how LLMs can be used for time series forecasting tasks and identify key challenges and limitations of current LLM-based forecasting models.
- Chronos aims to address these issues by incorporating specialized time series architectures and pretraining strategies into the LLM framework.
Plain English Explanation
Time series data, which represents measurements or observations collected over time, is ubiquitous in fields like finance, healthcare, and environmental monitoring. Accurately forecasting future values in time series data is an important but challenging task.
Recent advances in large language models (LLMs) like GPT-3 have shown impressive capabilities in areas like natural language processing and generation. Researchers have begun exploring whether LLMs can also be effective for time series forecasting, with some initial success demonstrated by models like Temporal Fusion Transformer and Tempo.
However, the authors of this paper argue that current LLM-based forecasters still struggle with key challenges, such as effectively capturing the intricate patterns and temporal dynamics present in time series data. They introduce Chronos, a new approach that aims to address these limitations by combining the strengths of LLMs with specialized time series architectures and pretraining strategies.
Technical Explanation
The core of Chronos is a novel transformer-based architecture that incorporates several key components to better handle time series data:
- Time Series Encoding: Chronos uses a specialized time series encoder that can effectively capture the temporal dynamics and patterns present in the input time series data.
- Temporal Attention: The model utilizes a temporal attention mechanism that allows it to focus on relevant past time steps when making forecasts, rather than treating the time series as a static sequence.
- Time Series Pretraining: Chronos is pretrained on a large corpus of synthetic time series data generated using techniques like TSGF and AutoSKTime, helping the model learn general time series patterns and dynamics.
In addition to the architectural innovations, the researchers also explore different fine-tuning and prompt engineering strategies to further enhance Chronos' performance on a variety of time series forecasting tasks.
Critical Analysis
The authors acknowledge several limitations and areas for future research:
- The synthetic pretraining data may not fully capture the complexity and diversity of real-world time series, and further work is needed to improve the quality and realism of the synthetic data.
- Chronos, like many LLM-based models, can be computationally expensive and resource-intensive, which may limit its practical deployment in some scenarios.
- The paper focuses primarily on univariate time series forecasting, and additional research is needed to extend Chronos to more complex multivariate and hierarchical forecasting problems.
Despite these limitations, the Chronos approach represents an important step forward in leveraging the power of LLMs for time series analysis and forecasting. By addressing key challenges in this domain, the researchers have laid the groundwork for more robust and reliable time series forecasting models that can have significant impact across a wide range of applications.
Conclusion
The Chronos paper demonstrates the potential of combining large language models with specialized time series architectures and pretraining strategies to advance the state-of-the-art in time series forecasting. The researchers have identified critical limitations in existing LLM-based forecasters and proposed an innovative approach to address them.
While further research is needed to refine and expand the Chronos model, this work represents an important contribution to the field of time series analysis and forecasting. By "learning the language of time series," Chronos and similar models have the potential to unlock new insights and enable more accurate predictions in a wide range of domains, from finance and healthcare to environmental monitoring and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Language Models Still Struggle to Zero-shot Reason about Time Series
Mike A. Merrill, Mingtian Tan, Vinayak Gupta, Tom Hartvigsen, Tim Althoff
0
0
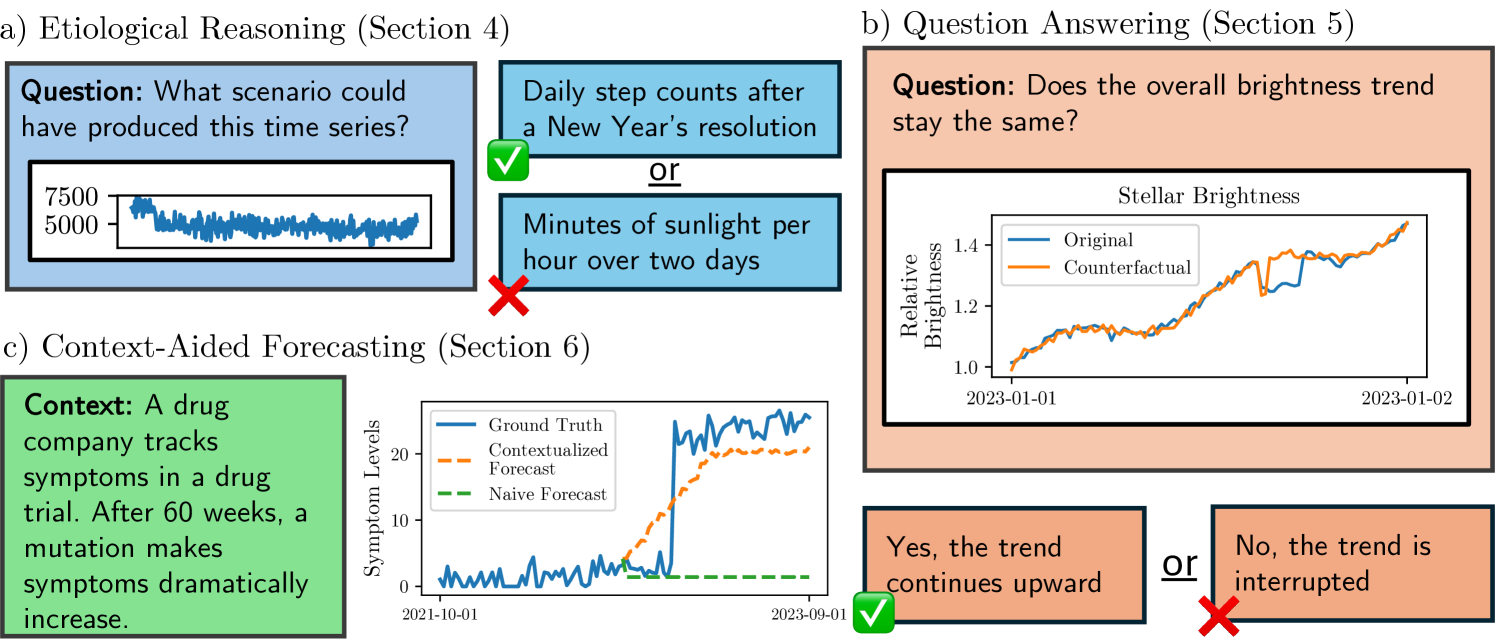
Time series are critical for decision-making in fields like finance and healthcare. Their importance has driven a recent influx of works passing time series into language models, leading to non-trivial forecasting on some datasets. But it remains unknown whether non-trivial forecasting implies that language models can reason about time series. To address this gap, we generate a first-of-its-kind evaluation framework for time series reasoning, including formal tasks and a corresponding dataset of multi-scale time series paired with text captions across ten domains. Using these data, we probe whether language models achieve three forms of reasoning: (1) Etiological Reasoning - given an input time series, can the language model identify the scenario that most likely created it? (2) Question Answering - can a language model answer factual questions about time series? (3) Context-Aided Forecasting - does highly relevant textual context improve a language model's time series forecasts? We find that otherwise highly-capable language models demonstrate surprisingly limited time series reasoning: they score marginally above random on etiological and question answering tasks (up to 30 percentage points worse than humans) and show modest success in using context to improve forecasting. These weakness showcase that time series reasoning is an impactful, yet deeply underdeveloped direction for language model research. We also make our datasets and code public at to support further research in this direction at https://github.com/behavioral-data/TSandLanguage
4/19/2024
📈
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, Yichen Zhou
0
0
Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a variety of public datasets comes close to the accuracy of state-of-the-art supervised forecasting models for each individual dataset. Our model is based on pretraining a patched-decoder style attention model on a large time-series corpus, and can work well across different forecasting history lengths, prediction lengths and temporal granularities.
4/19/2024
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
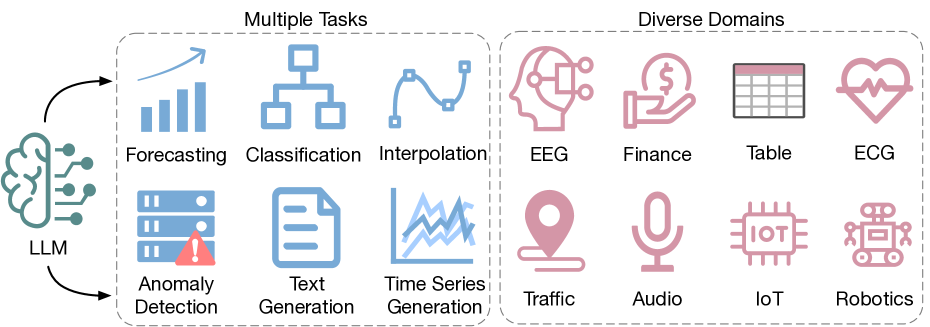
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024
🛸
TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
Defu Cao, Furong Jia, Sercan O Arik, Tomas Pfister, Yixiang Zheng, Wen Ye, Yan Liu
0
0
The past decade has witnessed significant advances in time series modeling with deep learning. While achieving state-of-the-art results, the best-performing architectures vary highly across applications and domains. Meanwhile, for natural language processing, the Generative Pre-trained Transformer (GPT) has demonstrated impressive performance via training one general-purpose model across various textual datasets. It is intriguing to explore whether GPT-type architectures can be effective for time series, capturing the intrinsic dynamic attributes and leading to significant accuracy improvements. In this paper, we propose a novel framework, TEMPO, that can effectively learn time series representations. We focus on utilizing two essential inductive biases of the time series task for pre-trained models: (i) decomposition of the complex interaction between trend, seasonal and residual components; and (ii) introducing the design of prompts to facilitate distribution adaptation in different types of time series. TEMPO expands the capability for dynamically modeling real-world temporal phenomena from data within diverse domains. Our experiments demonstrate the superior performance of TEMPO over state-of-the-art methods on zero shot setting for a number of time series benchmark datasets. This performance gain is observed not only in scenarios involving previously unseen datasets but also in scenarios with multi-modal inputs. This compelling finding highlights TEMPO's potential to constitute a foundational model-building framework.
4/3/2024