CICA: Content-Injected Contrastive Alignment for Zero-Shot Document Image Classification
2405.03660
0
0
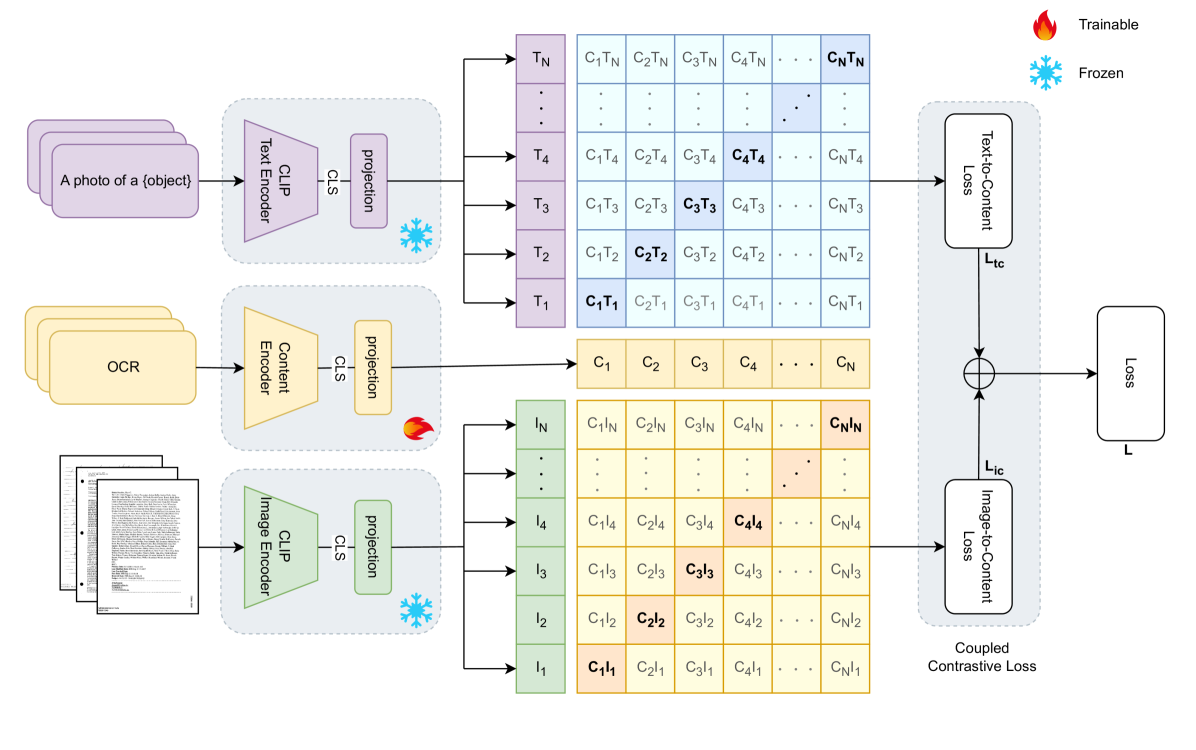
Abstract
Zero-shot learning has been extensively investigated in the broader field of visual recognition, attracting significant interest recently. However, the current work on zero-shot learning in document image classification remains scarce. The existing studies either focus exclusively on zero-shot inference, or their evaluation does not align with the established criteria of zero-shot evaluation in the visual recognition domain. We provide a comprehensive document image classification analysis in Zero-Shot Learning (ZSL) and Generalized Zero-Shot Learning (GZSL) settings to address this gap. Our methodology and evaluation align with the established practices of this domain. Additionally, we propose zero-shot splits for the RVL-CDIP dataset. Furthermore, we introduce CICA (pronounced 'ki-ka'), a framework that enhances the zero-shot learning capabilities of CLIP. CICA consists of a novel 'content module' designed to leverage any generic document-related textual information. The discriminative features extracted by this module are aligned with CLIP's text and image features using a novel 'coupled-contrastive' loss. Our module improves CLIP's ZSL top-1 accuracy by 6.7% and GZSL harmonic mean by 24% on the RVL-CDIP dataset. Our module is lightweight and adds only 3.3% more parameters to CLIP. Our work sets the direction for future research in zero-shot document classification.
Create account to get full access
Overview
- This paper introduces CICA (Content-Injected Contrastive Alignment), a novel zero-shot learning approach for document image classification.
- CICA leverages contrastive learning to align visual features of document images with their textual content, enabling effective zero-shot transfer to novel classes.
- The authors demonstrate CICA's superior performance compared to existing zero-shot and generalized zero-shot learning methods on several document image classification benchmarks.
Plain English Explanation
CICA is a new way to classify document images without needing examples of every type of document. Typically, machine learning models need to be trained on lots of examples of each class of document in order to learn how to recognize them. But with CICA, the model can learn to classify novel document types that it hasn't seen before.
The key idea behind CICA is to use "contrastive learning" to align the visual features of document images with their textual content. This means the model learns to match up the visual appearance of a document with the words and information it contains. By making these visual-textual connections, the model can then take what it has learned and apply it to classify new types of documents it hasn't seen before.
This zero-shot learning approach allows the model to work with new document types that weren't included in its original training, which is a very useful capability. The authors show that CICA outperforms other state-of-the-art zero-shot and generalized zero-shot learning methods on standard document image classification benchmarks.
Technical Explanation
The CICA architecture consists of a visual encoder that processes the document image and a text encoder that processes the document's textual content. These encoders are trained using contrastive learning to align the visual and textual representations.
Specifically, CICA optimizes a contrastive loss function that encourages the model to push the visual and textual embeddings of the same document closer together, while pulling apart the embeddings of mismatched document-text pairs. This forces the model to learn a joint visual-textual representation that captures the semantics of the document.
During inference, CICA can then classify novel document types by comparing the visual embedding of the input document to the learned textual class embeddings, without requiring any training examples of the new classes. This zero-shot learning capability enables CICA to generalize to a wider range of document types.
The authors further enhance CICA's performance through a content-injection technique that injects the document's textual content directly into the visual encoder, allowing it to better leverage the semantic information. This content-injected contrastive alignment leads to significant improvements over standard contrastive learning approaches.
Critical Analysis
The CICA paper presents a compelling zero-shot learning solution for document image classification, demonstrating strong performance on several benchmarks. However, the authors acknowledge some potential limitations:
- The approach relies on the availability of high-quality textual content associated with each document image. In real-world scenarios, this textual metadata may not always be present or accurate.
- While CICA can generalize to novel document classes, its performance may still be inferior to fully supervised learning approaches when training data for the target classes is available.
- The content-injection technique introduces additional complexity and hyperparameters that need to be carefully tuned, potentially limiting the method's ease of use.
Additionally, the paper does not explore the robustness of CICA to noisy or adversarial inputs, which is an important consideration for practical document image classification systems. Further research could investigate CICA's sensitivity to real-world variations in document layout, quality, and content.
Conclusion
The CICA paper presents a novel zero-shot learning approach for document image classification that leverages contrastive alignment of visual and textual representations. By enabling effective transfer to novel document classes without requiring any training examples, CICA offers a promising solution for expanding the capabilities of document image classification systems.
The content-injected contrastive alignment technique is a key innovation that enhances CICA's performance, although its practical deployment may require careful tuning and consideration of potential limitations. Overall, the CICA method represents an important step forward in the field of zero-shot document image classification and could have significant implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
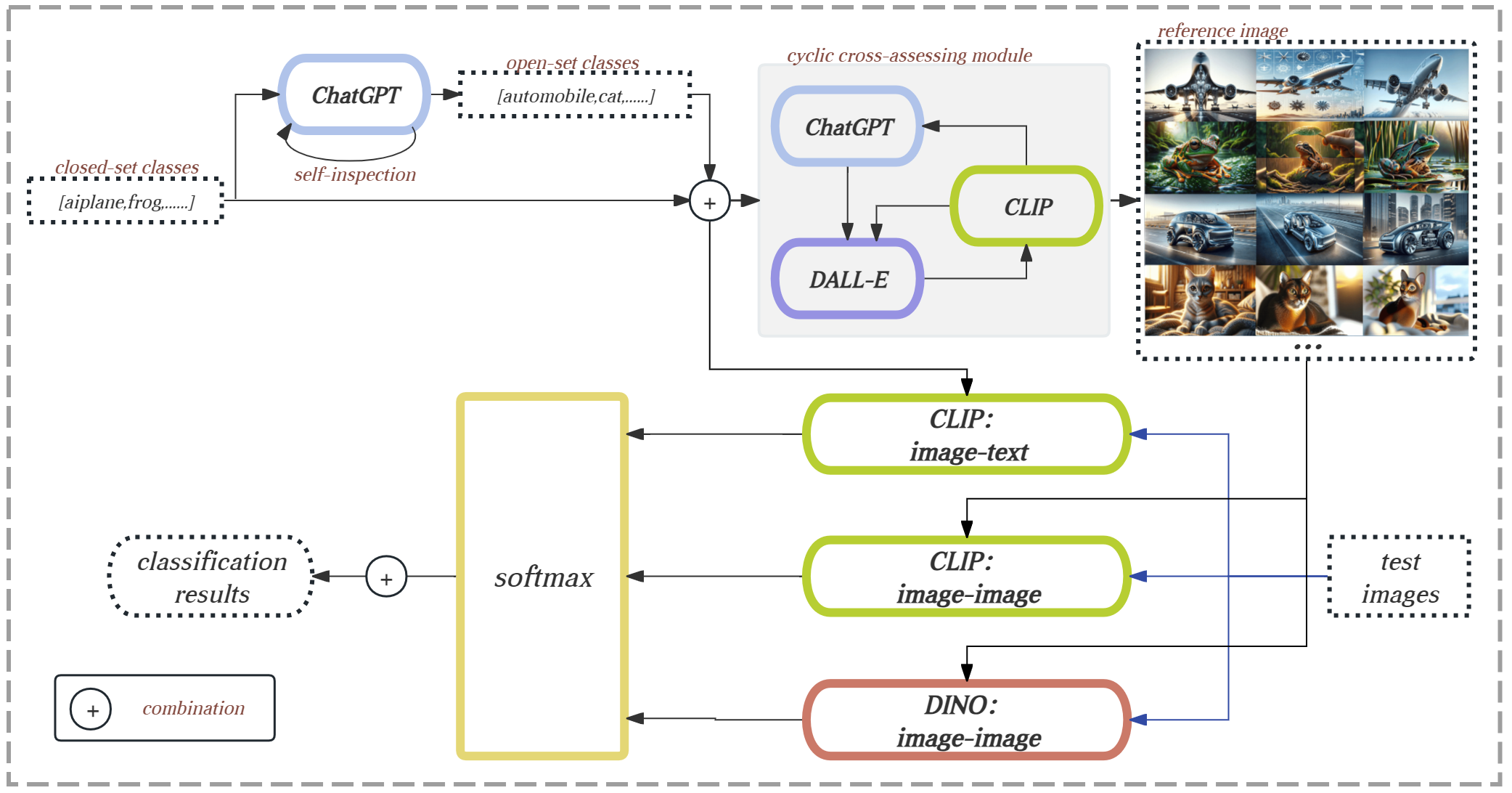
Multi-method Integration with Confidence-based Weighting for Zero-shot Image Classification
Siqi Yin, Lifan Jiang
0
0
This paper introduces a novel framework for zero-shot learning (ZSL), i.e., to recognize new categories that are unseen during training, by using a multi-model and multi-alignment integration method. Specifically, we propose three strategies to enhance the model's performance to handle ZSL: 1) Utilizing the extensive knowledge of ChatGPT and the powerful image generation capabilities of DALL-E to create reference images that can precisely describe unseen categories and classification boundaries, thereby alleviating the information bottleneck issue; 2) Integrating the results of text-image alignment and image-image alignment from CLIP, along with the image-image alignment results from DINO, to achieve more accurate predictions; 3) Introducing an adaptive weighting mechanism based on confidence levels to aggregate the outcomes from different prediction methods. Experimental results on multiple datasets, including CIFAR-10, CIFAR-100, and TinyImageNet, demonstrate that our model can significantly improve classification accuracy compared to single-model approaches, achieving AUROC scores above 96% across all test datasets, and notably surpassing 99% on the CIFAR-10 dataset.
5/6/2024
🛸
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
0
0
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
6/7/2024
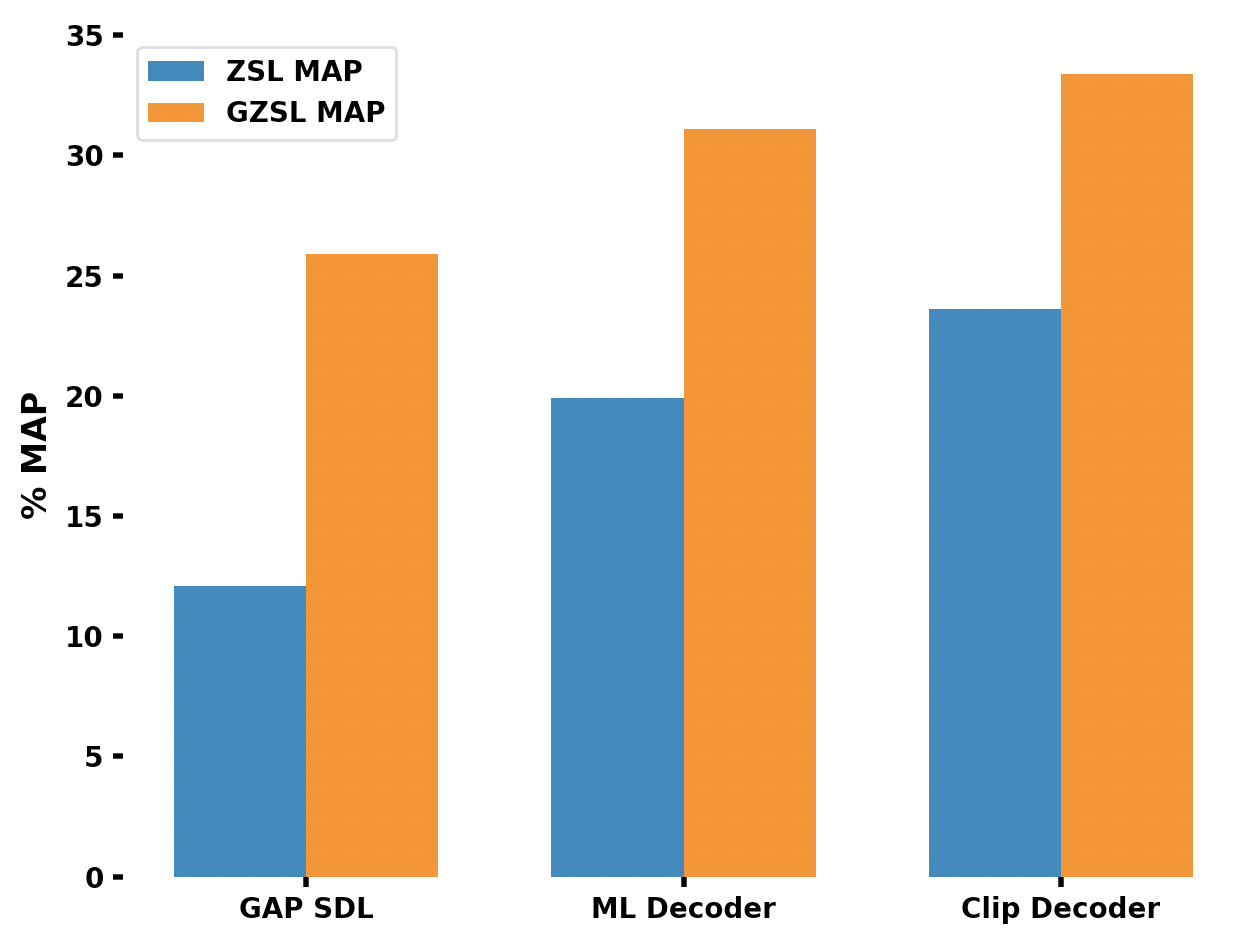
CLIP-Decoder : ZeroShot Multilabel Classification using Multimodal CLIP Aligned Representation
Muhammad Ali, Salman Khan
0
0
Multi-label classification is an essential task utilized in a wide variety of real-world applications. Multi-label zero-shot learning is a method for classifying images into multiple unseen categories for which no training data is available, while in general zero-shot situations, the test set may include observed classes. The CLIP-Decoder is a novel method based on the state-of-the-art ML-Decoder attention-based head. We introduce multi-modal representation learning in CLIP-Decoder, utilizing the text encoder to extract text features and the image encoder for image feature extraction. Furthermore, we minimize semantic mismatch by aligning image and word embeddings in the same dimension and comparing their respective representations using a combined loss, which comprises classification loss and CLIP loss. This strategy outperforms other methods and we achieve cutting-edge results on zero-shot multilabel classification tasks using CLIP-Decoder. Our method achieves an absolute increase of 3.9% in performance compared to existing methods for zero-shot learning multi-label classification tasks. Additionally, in the generalized zero-shot learning multi-label classification task, our method shows an impressive increase of almost 2.3%.
6/24/2024
⛏️
Transductive Zero-Shot and Few-Shot CLIP
S'egol`ene Martin (OPIS, CVN), Yunshi Huang (ETS), Fereshteh Shakeri (ETS), Jean-Christophe Pesquet (OPIS, CVN), Ismail Ben Ayed (ETS)
0
0
Transductive inference has been widely investigated in few-shot image classification, but completely overlooked in the recent, fast growing literature on adapting vision-langage models like CLIP. This paper addresses the transductive zero-shot and few-shot CLIP classification challenge, in which inference is performed jointly across a mini-batch of unlabeled query samples, rather than treating each instance independently. We initially construct informative vision-text probability features, leading to a classification problem on the unit simplex set. Inspired by Expectation-Maximization (EM), our optimization-based classification objective models the data probability distribution for each class using a Dirichlet law. The minimization problem is then tackled with a novel block Majorization-Minimization algorithm, which simultaneously estimates the distribution parameters and class assignments. Extensive numerical experiments on 11 datasets underscore the benefits and efficacy of our batch inference approach.On zero-shot tasks with test batches of 75 samples, our approach yields near 20% improvement in ImageNet accuracy over CLIP's zero-shot performance. Additionally, we outperform state-of-the-art methods in the few-shot setting. The code is available at: https://github.com/SegoleneMartin/transductive-CLIP.
5/30/2024