On Class Separability Pitfalls In Audio-Text Contrastive Zero-Shot Learning

0

Sign in to get full access
Overview
- The paper examines potential pitfalls in audio-text contrastive zero-shot learning models.
- It identifies issues with class separability that can lead to poor generalization and performance.
- The authors propose solutions to address these challenges and improve the robustness of zero-shot learning systems.
Plain English Explanation
Zero-shot learning is a technique where AI models can recognize and classify objects or concepts they haven't been explicitly trained on before. This is done by learning the relationships between visual, audio, and textual data.
In audio-text contrastive zero-shot learning, the model learns to associate audio signals with their corresponding textual descriptions. This allows the model to recognize new sound categories without needing audio examples during training.
However, the authors of this paper have identified potential issues with how these models learn to separate different sound classes. They found that the way the model's learning process is set up can lead to poor generalization - the model may not work well on new examples outside its training data.
The core problem is that the model can "cheat" by exploiting spurious statistical correlations in the training data, rather than learning the true underlying relationships between audio and text. This can result in the model performing well on the training data but failing on new, unseen examples.
To address this, the authors propose solutions to improve the model's class separability - its ability to clearly distinguish between different sound categories. This helps the model learn more robust and generalizable associations between audio and text.
Technical Explanation
The paper focuses on the zero-shot learning setting, where the model is trained to recognize new sound categories without having access to audio examples of those categories during training.
Specifically, the authors analyze audio-text contrastive learning, a popular approach for zero-shot learning. In this setup, the model is trained to embed audio and text data into a shared latent space, where corresponding audio-text pairs are pushed together while unrelated pairs are pulled apart.
The key issue the paper identifies is that this contrastive learning process can lead to poor class separability - the model's ability to clearly distinguish between different sound categories. The authors show that the model can exploit spurious statistical correlations in the training data to achieve good performance, without actually learning the true underlying audio-text associations.
To address this, the authors propose several solutions:
- Improving the diversity of training data to reduce reliance on spurious correlations.
- Incorporating stronger regularization to encourage the model to learn more robust and generalizable representations.
- Modifying the contrastive loss function to better align with the desired class separability objective.
Through experiments on benchmark datasets, the authors demonstrate that these techniques can significantly improve the zero-shot learning performance of audio-text models, making them more reliable and robust.
Critical Analysis
The authors have identified an important issue in the field of audio-text contrastive zero-shot learning, which is the potential for models to overfit to statistical artifacts in the training data rather than learning the true underlying relationships.
One limitation of the paper is that it focuses on the specific case of audio-text zero-shot learning, and it's unclear how generalizable the proposed solutions would be to other modality combinations (e.g., vision-text) or to different zero-shot learning architectures.
Additionally, the paper does not provide a deep analysis of the specific mechanisms by which the contrastive learning process can lead to poor class separability. A more detailed examination of the failure modes and their underlying causes could have strengthened the theoretical contributions of the work.
That said, the empirical results presented are compelling and the proposed solutions seem promising for improving the robustness and reliability of zero-shot learning models. Further research exploring the generalizability of these techniques and their applicability to other domains would be valuable.
Conclusion
This paper sheds light on an important challenge in audio-text contrastive zero-shot learning – the potential for models to exploit spurious statistical correlations in the training data, leading to poor class separability and generalization.
The authors' proposed solutions, including improving data diversity, stronger regularization, and modifying the contrastive loss function, offer a path forward for building more reliable and robust zero-shot learning systems. Their work highlights the need to carefully design the learning process to align with the desired objectives, rather than relying on the model to "figure it out" on its own.
As zero-shot learning becomes increasingly important for practical applications, addressing these class separability pitfalls will be crucial for ensuring the technology can be deployed safely and effectively. This paper provides a valuable contribution towards that goal.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On Class Separability Pitfalls In Audio-Text Contrastive Zero-Shot Learning
Tiago Tavares, Fabio Ayres, Zhepei Wang, Paris Smaragdis
Recent advances in audio-text cross-modal contrastive learning have shown its potential towards zero-shot learning. One possibility for this is by projecting item embeddings from pre-trained backbone neural networks into a cross-modal space in which item similarity can be calculated in either domain. This process relies on a strong unimodal pre-training of the backbone networks, and on a data-intensive training task for the projectors. These two processes can be biased by unintentional data leakage, which can arise from using supervised learning in pre-training or from inadvertently training the cross-modal projection using labels from the zero-shot learning evaluation. In this study, we show that a significant part of the measured zero-shot learning accuracy is due to strengths inherited from the audio and text backbones, that is, they are not learned in the cross-modal domain and are not transferred from one modality to another.
Read more8/26/2024
🤖
0
Enhancing Audio-Language Models through Self-Supervised Post-Training with Text-Audio Pairs
Anshuman Sinha, Camille Migozzi, Aubin Rey, Chao Zhang
Research on multi-modal contrastive learning strategies for audio and text has rapidly gained interest. Contrastively trained Audio-Language Models (ALMs), such as CLAP, which establish a unified representation across audio and language modalities, have enhanced the efficacy in various subsequent tasks by providing good text aligned audio encoders and vice versa. These improvements are evident in areas like zero-shot audio classification and audio retrieval, among others. However, the ability of these models to understand natural language and temporal relations is still a largely unexplored and open field for research. In this paper, we propose to equip the multi-modal ALMs with temporal understanding without loosing their inherent prior capabilities of audio-language tasks with a temporal instillation method TeminAL. We implement a two-stage training scheme TeminAL A $&$ B, where the model first learns to differentiate between multiple sounds in TeminAL A, followed by a phase that instills a sense of time, thereby enhancing its temporal understanding in TeminAL B. This approach results in an average performance gain of $5.28%$ in temporal understanding on the ESC-50 dataset, while the model remains competitive in zero-shot retrieval and classification tasks on the AudioCap/Clotho datasets. We also note the lack of proper evaluation techniques for contrastive ALMs and propose a strategy for evaluating ALMs in zero-shot settings. The general-purpose zero-shot model evaluation strategy ZSTE, is used to evaluate various prior models. ZSTE demonstrates a general strategy to evaluate all ZS contrastive models. The model trained with TeminAL successfully outperforms current models on most downstream tasks.
Read more8/20/2024
0
Audio-visual Generalized Zero-shot Learning the Easy Way
Shentong Mo, Pedro Morgado
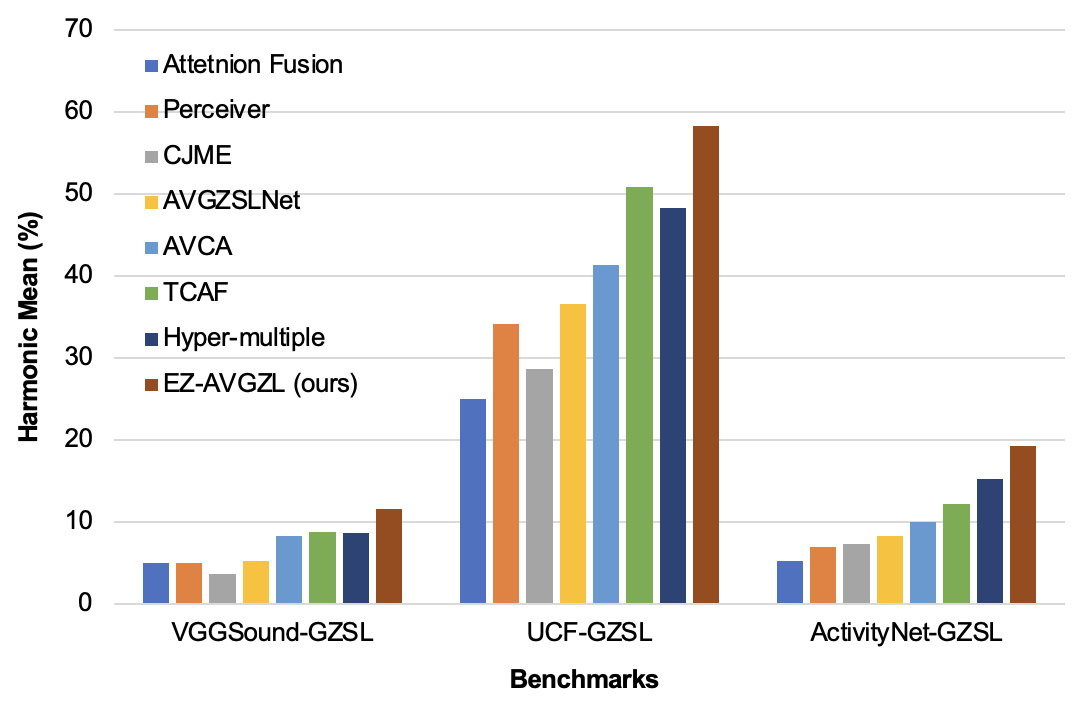
Audio-visual generalized zero-shot learning is a rapidly advancing domain that seeks to understand the intricate relations between audio and visual cues within videos. The overarching goal is to leverage insights from seen classes to identify instances from previously unseen ones. Prior approaches primarily utilized synchronized auto-encoders to reconstruct audio-visual attributes, which were informed by cross-attention transformers and projected text embeddings. However, these methods fell short of effectively capturing the intricate relationship between cross-modal features and class-label embeddings inherent in pre-trained language-aligned embeddings. To circumvent these bottlenecks, we introduce a simple yet effective framework for Easy Audio-Visual Generalized Zero-shot Learning, named EZ-AVGZL, that aligns audio-visual embeddings with transformed text representations. It utilizes a single supervised text audio-visual contrastive loss to learn an alignment between audio-visual and textual modalities, moving away from the conventional approach of reconstructing cross-modal features and text embeddings. Our key insight is that while class name embeddings are well aligned with language-based audio-visual features, they don't provide sufficient class separation to be useful for zero-shot learning. To address this, our method leverages differential optimization to transform class embeddings into a more discriminative space while preserving the semantic structure of language representations. We conduct extensive experiments on VGGSound-GZSL, UCF-GZSL, and ActivityNet-GZSL benchmarks. Our results demonstrate that our EZ-AVGZL achieves state-of-the-art performance in audio-visual generalized zero-shot learning.
Read more7/19/2024
0
Zero-Shot Audio Captioning Using Soft and Hard Prompts
Yiming Zhang, Xuenan Xu, Ruoyi Du, Haohe Liu, Yuan Dong, Zheng-Hua Tan, Wenwu Wang, Zhanyu Ma
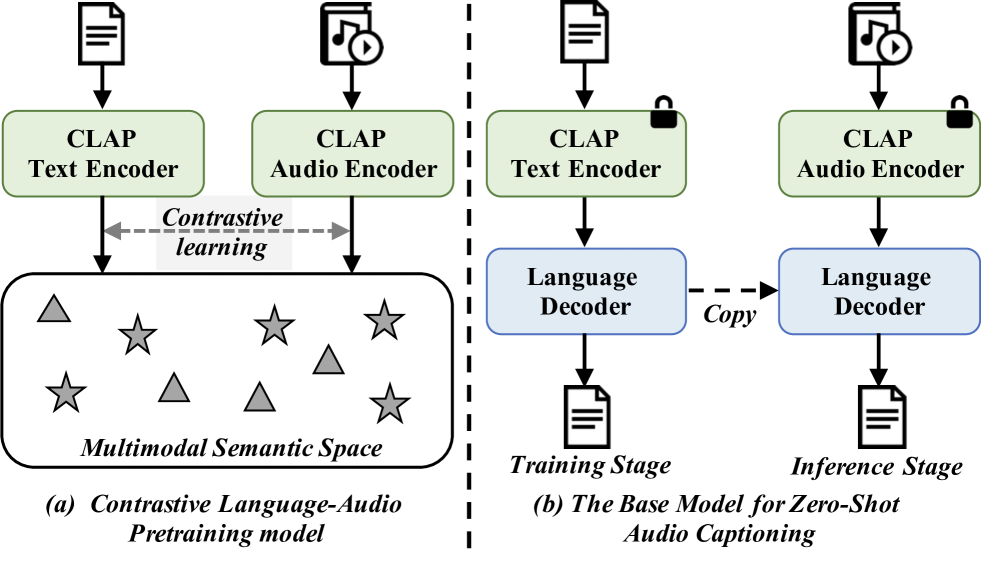
In traditional audio captioning methods, a model is usually trained in a fully supervised manner using a human-annotated dataset containing audio-text pairs and then evaluated on the test sets from the same dataset. Such methods have two limitations. First, these methods are often data-hungry and require time-consuming and expensive human annotations to obtain audio-text pairs. Second, these models often suffer from performance degradation in cross-domain scenarios, i.e., when the input audio comes from a different domain than the training set, which, however, has received little attention. We propose an effective audio captioning method based on the contrastive language-audio pre-training (CLAP) model to address these issues. Our proposed method requires only textual data for training, enabling the model to generate text from the textual feature in the cross-modal semantic space.In the inference stage, the model generates the descriptive text for the given audio from the audio feature by leveraging the audio-text alignment from CLAP.We devise two strategies to mitigate the discrepancy between text and audio embeddings: a mixed-augmentation-based soft prompt and a retrieval-based acoustic-aware hard prompt. These approaches are designed to enhance the generalization performance of our proposed model, facilitating the model to generate captions more robustly and accurately. Extensive experiments on AudioCaps and Clotho benchmarks show the effectiveness of our proposed method, which outperforms other zero-shot audio captioning approaches for in-domain scenarios and outperforms the compared methods for cross-domain scenarios, underscoring the generalization ability of our method.
Read more6/11/2024