Clio: Real-time Task-Driven Open-Set 3D Scene Graphs

0

Sign in to get full access
Overview
- This paper introduces Clio, a real-time 3D scene understanding system that can build task-driven open-set 3D scene graphs.
- Clio aims to enable more advanced and interactive applications for 3D environments by understanding the semantic and functional relationships between objects.
- The system can detect and recognize a wide range of objects in 3D scenes, as well as infer their affordances and relationships to support task-level reasoning.
Plain English Explanation
Clio is a new computer vision system that can analyze 3D scenes in real-time and build detailed "scene graphs" - a structured way of representing the objects, their properties, and how they are related to each other. Unlike previous systems that could only recognize a limited set of known objects, Clio is designed to work in "open-set" environments, meaning it can detect and understand a wide variety of objects, even ones it hasn't been specifically trained on before.
This open-set capability allows Clio to be more flexible and adaptable to real-world scenarios. Moreover, Clio goes beyond just identifying objects - it also tries to understand their functional properties and relationships. For example, it can determine that a chair is "sit-able" or that a cup is "hold-able" and connected to a table. This task-aware understanding enables Clio to reason about how the elements in a 3D scene could be used to accomplish higher-level goals or tasks.
The researchers behind Clio believe this kind of rich 3D scene understanding is a key step toward more advanced and intuitive interactive applications, like robotic assistants that can better understand and navigate complex environments. By building a detailed semantic model of a 3D space, Clio aims to provide a foundation for AI systems to plan, reason, and interact with the world in more human-like ways.
Technical Explanation
The core of Clio is a deep learning-based 3D scene understanding pipeline that operates in real-time. It takes as input a 3D point cloud or RGB-D data and produces a structured 3D scene graph. This graph represents the objects detected in the scene, along with their semantic categories, geometric properties, and relationships to other objects.
Central to Clio's approach is the use of an "open-set" object detection and recognition model, which allows the system to handle a diverse, open-ended set of object classes, going beyond the fixed taxonomies of previous works like QuestMaps, 3D Open Vocabulary Panoptic Segmentation, and Mapping High-Level Semantic Regions. This open-set capability is achieved through a combination of advanced object detection and zero-shot classification techniques.
In addition to object recognition, Clio also infers the functional affordances of detected objects, as well as the semantic relationships between them. This allows the system to build a rich, task-aware 3D scene graph that can be leveraged for higher-level reasoning and planning. The researchers demonstrate Clio's capabilities on a variety of 3D scene understanding benchmarks, showing its superior performance compared to previous state-of-the-art methods.
Critical Analysis
The Clio system represents a significant advancement in 3D scene understanding, but it also has some limitations and areas for further research noted in the paper. For example, the open-set object recognition approach, while powerful, still has room for improvement in terms of accuracy and generalization to novel objects.
Additionally, the inference of object affordances and relationships, while a key strength of Clio, could be further enhanced by incorporating more contextual and commonsense reasoning. The current implementation relies primarily on visual cues, and integrating additional knowledge sources could lead to even more robust and generalizable scene understanding.
Another potential area for improvement is the system's real-time performance, which is critical for many interactive applications. While Clio operates at an impressive frame rate, further optimizations or specialized hardware could unlock even faster processing speeds.
Finally, the evaluation of Clio is primarily focused on indoor 3D scenes, and its performance in more complex, outdoor environments remains to be seen. Extending the system's capabilities to handle a wider range of real-world scenes would be an important next step.
Conclusion
Overall, the Clio system represents a significant advancement in the field of 3D scene understanding, with its ability to build rich, task-aware scene graphs in real-time and across a diverse, open-set of object classes. This technology has the potential to enable a new generation of interactive applications that can better understand and reason about the 3D world around them, paving the way for more intuitive and capable AI assistants, robotic systems, and mixed reality experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Clio: Real-time Task-Driven Open-Set 3D Scene Graphs
Dominic Maggio, Yun Chang, Nathan Hughes, Matthew Trang, Dan Griffith, Carlyn Dougherty, Eric Cristofalo, Lukas Schmid, Luca Carlone
Modern tools for class-agnostic image segmentation (e.g., SegmentAnything) and open-set semantic understanding (e.g., CLIP) provide unprecedented opportunities for robot perception and mapping. While traditional closed-set metric-semantic maps were restricted to tens or hundreds of semantic classes, we can now build maps with a plethora of objects and countless semantic variations. This leaves us with a fundamental question: what is the right granularity for the objects (and, more generally, for the semantic concepts) the robot has to include in its map representation? While related work implicitly chooses a level of granularity by tuning thresholds for object detection, we argue that such a choice is intrinsically task-dependent. The first contribution of this paper is to propose a task-driven 3D scene understanding problem, where the robot is given a list of tasks in natural language and has to select the granularity and the subset of objects and scene structure to retain in its map that is sufficient to complete the tasks. We show that this problem can be naturally formulated using the Information Bottleneck (IB), an established information-theoretic framework. The second contribution is an algorithm for task-driven 3D scene understanding based on an Agglomerative IB approach, that is able to cluster 3D primitives in the environment into task-relevant objects and regions and executes incrementally. The third contribution is to integrate our task-driven clustering algorithm into a real-time pipeline, named Clio, that constructs a hierarchical 3D scene graph of the environment online using only onboard compute, as the robot explores it. Our final contribution is an extensive experimental campaign showing that Clio not only allows real-time construction of compact open-set 3D scene graphs, but also improves the accuracy of task execution by limiting the map to relevant semantic concepts.
Read more4/30/2024

0
QueSTMaps: Queryable Semantic Topological Maps for 3D Scene Understanding
Yash Mehan, Kumaraditya Gupta, Rohit Jayanti, Anirudh Govil, Sourav Garg, Madhava Krishna
Understanding the structural organisation of 3D indoor scenes in terms of rooms is often accomplished via floorplan extraction. Robotic tasks such as planning and navigation require a semantic understanding of the scene as well. This is typically achieved via object-level semantic segmentation. However, such methods struggle to segment out topological regions like kitchen in the scene. In this work, we introduce a two-step pipeline. First, we extract a topological map, i.e., floorplan of the indoor scene using a novel multi-channel occupancy representation. Then, we generate CLIP-aligned features and semantic labels for every room instance based on the objects it contains using a self-attention transformer. Our language-topology alignment supports natural language querying, e.g., a place to cook locates the kitchen. We outperform the current state-of-the-art on room segmentation by ~20% and room classification by ~12%. Our detailed qualitative analysis and ablation studies provide insights into the problem of joint structural and semantic 3D scene understanding.
Read more4/10/2024

0
Open-Set 3D Semantic Instance Maps for Vision Language Navigation -- O3D-SIM
Laksh Nanwani, Kumaraditya Gupta, Aditya Mathur, Swayam Agrawal, A. H. Abdul Hafez, K. Madhava Krishna
Humans excel at forming mental maps of their surroundings, equipping them to understand object relationships and navigate based on language queries. Our previous work SI Maps [1] showed that having instance-level information and the semantic understanding of an environment helps significantly improve performance for language-guided tasks. We extend this instance-level approach to 3D while increasing the pipeline's robustness and improving quantitative and qualitative results. Our method leverages foundational models for object recognition, image segmentation, and feature extraction. We propose a representation that results in a 3D point cloud map with instance-level embeddings, which bring in the semantic understanding that natural language commands can query. Quantitatively, the work improves upon the success rate of language-guided tasks. At the same time, we qualitatively observe the ability to identify instances more clearly and leverage the foundational models and language and image-aligned embeddings to identify objects that, otherwise, a closed-set approach wouldn't be able to identify.
Read more4/30/2024
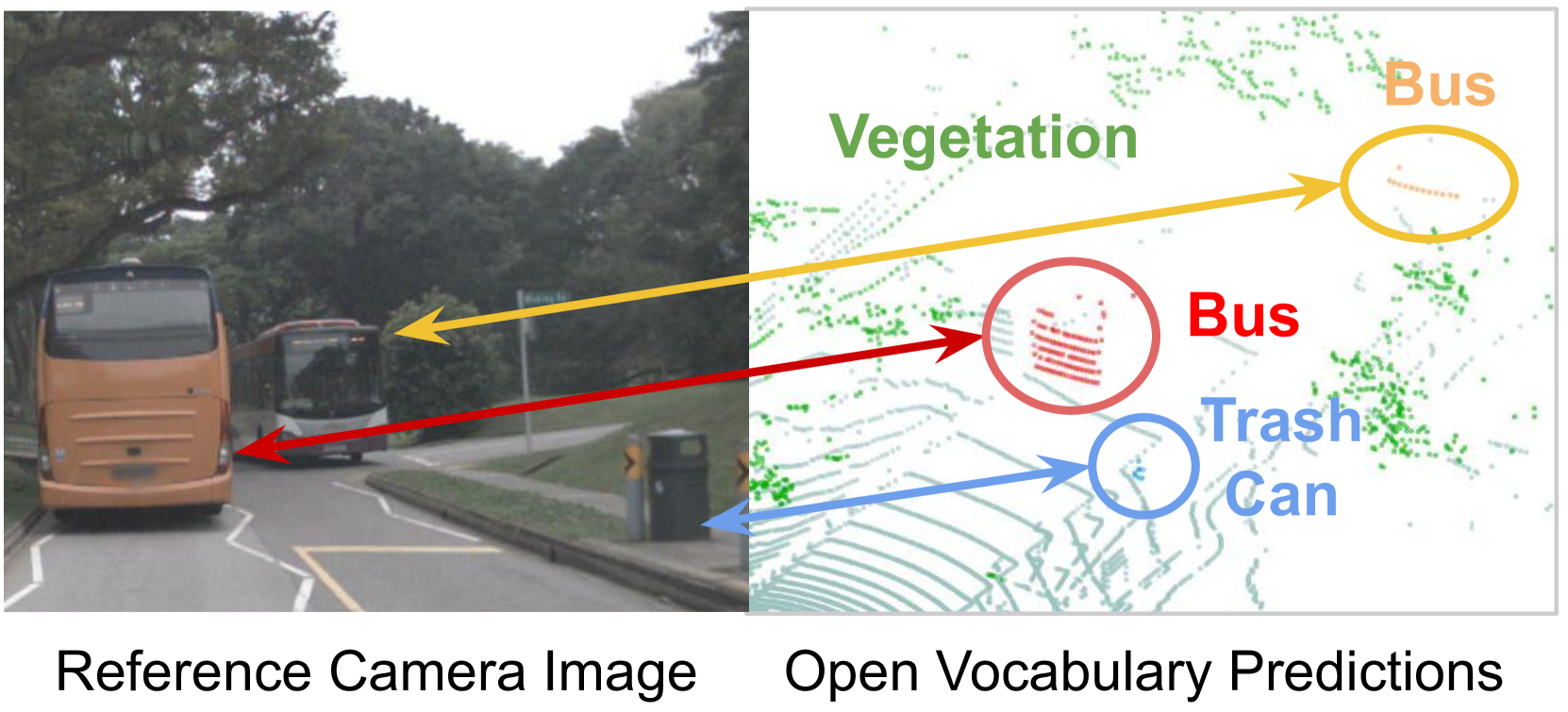
0
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Zihao Xiao, Longlong Jing, Shangxuan Wu, Alex Zihao Zhu, Jingwei Ji, Chiyu Max Jiang, Wei-Chih Hung, Thomas Funkhouser, Weicheng Kuo, Anelia Angelova, Yin Zhou, Shiwei Sheng
3D panoptic segmentation is a challenging perception task, especially in autonomous driving. It aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing these approaches to unseen things and unseen stuff categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not guarantee good performance due to poor per-mask classification quality, especially for novel stuff categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms the strong baseline by a large margin.
Read more4/4/2024