Closing the gap between open-source and commercial large language models for medical evidence summarization

0

Sign in to get full access
Overview
- This paper explores how open-source large language models (LLMs) can be adapted to achieve performance on par with commercial LLMs for medical evidence summarization.
- The researchers develop an approach to fine-tune open-source LLMs using a medical summarization dataset, allowing them to match or exceed the performance of commercial models.
- The findings demonstrate the potential for open-source LLMs to be a cost-effective alternative to commercial models in medical and healthcare applications.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. Commercial LLMs like GPT-3 have shown impressive performance, but they can be expensive to use. Open-source LLMs provide a more affordable alternative, but their performance has typically lagged behind commercial models.
In this research, the team set out to "close the gap" between open-source and commercial LLMs for a specific task: summarizing medical evidence. They took an open-source LLM and "adapted" it by fine-tuning it on a dataset of medical summaries. This allowed the open-source model to match or even outperform commercial LLMs on this medical summarization task.
The key insight here is that with the right fine-tuning, open-source LLMs can be just as capable as their commercial counterparts, but at a fraction of the cost. This makes them a viable and cost-effective alternative for applications in the medical and healthcare fields, where accurate summarization of evidence is crucial.
Technical Explanation
The researchers started with the open-source GPT-2 LLM and fine-tuned it on the PubMedQA dataset, which contains medical abstracts and human-written summaries. They compared the performance of the fine-tuned GPT-2 model to that of commercial LLMs like GPT-3 on the task of generating accurate summaries of medical evidence.
Through extensive experiments, the team found that their adapted open-source model was able to achieve equivalent or even better performance than the commercial models on various summarization metrics. This included measures like ROUGE score, which evaluates the similarity between the generated summaries and the human-written reference summaries.
The researchers attribute this success to the effectiveness of their fine-tuning approach, which allowed the open-source LLM to "adapt" its general language understanding capabilities to the specific domain of medical evidence summarization.
Critical Analysis
The paper provides a compelling demonstration of how open-source LLMs can be tailored to match or exceed the performance of commercial models for certain tasks. However, it's important to note that the study is focused on a single, albeit important, application (medical evidence summarization).
The researchers acknowledge that the performance of open-source LLMs may still lag behind commercial models on other tasks or datasets. Additionally, the fine-tuning process required to achieve this level of performance may be time-consuming and resource-intensive, which could limit the accessibility of this approach for some users.
Further research is needed to explore the generalizability of these findings to a broader range of applications and to investigate more efficient fine-tuning techniques that could make the process more accessible to a wider audience.
Conclusion
This paper presents a promising approach for leveraging open-source LLMs to tackle important tasks in the medical and healthcare domains. By fine-tuning an open-source model on a relevant dataset, the researchers were able to demonstrate that it can match or exceed the performance of commercial LLMs, while being a more cost-effective solution.
The findings highlight the potential for open-source LLMs to play a significant role in expanding access to powerful language AI technology, particularly in applications where accurate and reliable text summarization is crucial. As the field of AI continues to evolve, this research offers a roadmap for bridging the gap between open-source and commercial large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Closing the gap between open-source and commercial large language models for medical evidence summarization
Gongbo Zhang, Qiao Jin, Yiliang Zhou, Song Wang, Betina R. Idnay, Yiming Luo, Elizabeth Park, Jordan G. Nestor, Matthew E. Spotnitz, Ali Soroush, Thomas Campion, Zhiyong Lu, Chunhua Weng, Yifan Peng
Large language models (LLMs) hold great promise in summarizing medical evidence. Most recent studies focus on the application of proprietary LLMs. Using proprietary LLMs introduces multiple risk factors, including a lack of transparency and vendor dependency. While open-source LLMs allow better transparency and customization, their performance falls short compared to proprietary ones. In this study, we investigated to what extent fine-tuning open-source LLMs can further improve their performance in summarizing medical evidence. Utilizing a benchmark dataset, MedReview, consisting of 8,161 pairs of systematic reviews and summaries, we fine-tuned three broadly-used, open-sourced LLMs, namely PRIMERA, LongT5, and Llama-2. Overall, the fine-tuned LLMs obtained an increase of 9.89 in ROUGE-L (95% confidence interval: 8.94-10.81), 13.21 in METEOR score (95% confidence interval: 12.05-14.37), and 15.82 in CHRF score (95% confidence interval: 13.89-16.44). The performance of fine-tuned LongT5 is close to GPT-3.5 with zero-shot settings. Furthermore, smaller fine-tuned models sometimes even demonstrated superior performance compared to larger zero-shot models. The above trends of improvement were also manifested in both human and GPT4-simulated evaluations. Our results can be applied to guide model selection for tasks demanding particular domain knowledge, such as medical evidence summarization.
Read more8/2/2024
💬
0
Comparative Analysis of Open-Source Language Models in Summarizing Medical Text Data
Yuhao Chen, Zhimu Wang, Bo Wen, Farhana Zulkernine
Unstructured text in medical notes and dialogues contains rich information. Recent advancements in Large Language Models (LLMs) have demonstrated superior performance in question answering and summarization tasks on unstructured text data, outperforming traditional text analysis approaches. However, there is a lack of scientific studies in the literature that methodically evaluate and report on the performance of different LLMs, specifically for domain-specific data such as medical chart notes. We propose an evaluation approach to analyze the performance of open-source LLMs such as Llama2 and Mistral for medical summarization tasks, using GPT-4 as an assessor. Our innovative approach to quantitative evaluation of LLMs can enable quality control, support the selection of effective LLMs for specific tasks, and advance knowledge discovery in digital health.
Read more5/31/2024
🚀
0
Can Open-Source LLMs Compete with Commercial Models? Exploring the Few-Shot Performance of Current GPT Models in Biomedical Tasks
Samy Ateia, Udo Kruschwitz
Commercial large language models (LLMs), like OpenAI's GPT-4 powering ChatGPT and Anthropic's Claude 3 Opus, have dominated natural language processing (NLP) benchmarks across different domains. New competing Open-Source alternatives like Mixtral 8x7B or Llama 3 have emerged and seem to be closing the gap while often offering higher throughput and being less costly to use. Open-Source LLMs can also be self-hosted, which makes them interesting for enterprise and clinical use cases where sensitive data should not be processed by third parties. We participated in the 12th BioASQ challenge, which is a retrieval augmented generation (RAG) setting, and explored the performance of current GPT models Claude 3 Opus, GPT-3.5-turbo and Mixtral 8x7b with in-context learning (zero-shot, few-shot) and QLoRa fine-tuning. We also explored how additional relevant knowledge from Wikipedia added to the context-window of the LLM might improve their performance. Mixtral 8x7b was competitive in the 10-shot setting, both with and without fine-tuning, but failed to produce usable results in the zero-shot setting. QLoRa fine-tuning and Wikipedia context did not lead to measurable performance gains. Our results indicate that the performance gap between commercial and open-source models in RAG setups exists mainly in the zero-shot setting and can be closed by simply collecting few-shot examples for domain-specific use cases. The code needed to rerun these experiments is available through GitHub.
Read more7/19/2024
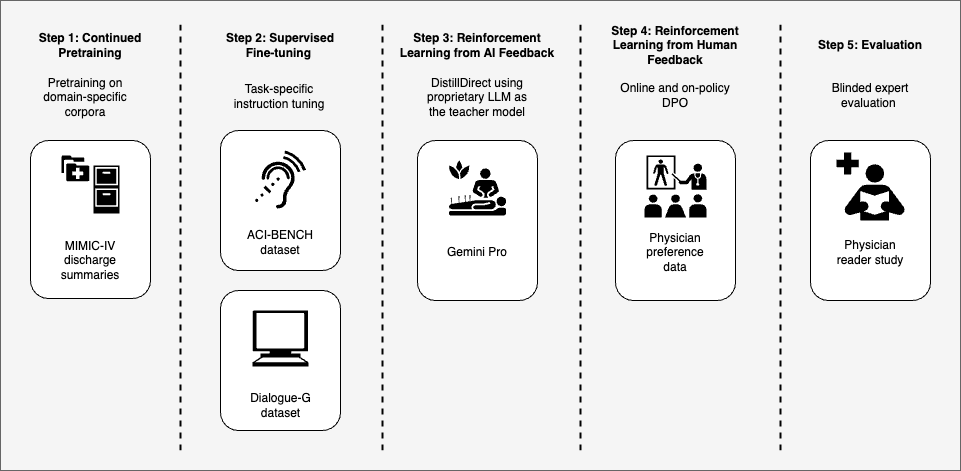
0
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Hanyin Wang, Chufan Gao, Bolun Liu, Qiping Xu, Guleid Hussein, Mohamad El Labban, Kingsley Iheasirim, Hariprasad Korsapati, Chuck Outcalt, Jimeng Sun
Proprietary Large Language Models (LLMs) such as GPT-4 and Gemini have demonstrated promising capabilities in clinical text summarization tasks. However, due to patient data privacy concerns and computational costs, many healthcare providers prefer using small, locally-hosted models over external generic LLMs. This study presents a comprehensive domain- and task-specific adaptation process for the open-source LLaMA-2 13 billion parameter model, enabling it to generate high-quality clinical notes from outpatient patient-doctor dialogues. Our process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced a new approach, DistillDirect, for performing on-policy reinforcement learning with Gemini 1.0 Pro as the teacher model. Our resulting model, LLaMA-Clinic, can generate clinical notes comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. In the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness than physician-authored notes (4.1/5). Our cost analysis for inference shows that our LLaMA-Clinic model achieves a 3.75-fold cost reduction compared to an external generic LLM service. Additionally, we highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format, rather than relying on LLMs to determine this for clinical practice. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research.
Read more6/11/2024