Cloud-based XAI Services for Assessing Open Repository Models Under Adversarial Attacks

0

Sign in to get full access
Overview
- This paper examines the quality attributes of AI vision models in open repositories under adversarial attacks.
- The researchers developed a conceptual framework for AI model quality assurance and used it to evaluate the robustness of popular open-source AI models.
- They found that many models are vulnerable to adversarial attacks, highlighting the need for more rigorous testing and quality assurance practices in the AI development ecosystem.
Plain English Explanation
The paper is focused on understanding how well popular AI vision models, like those used for image recognition, can withstand malicious attacks designed to trick the models into making incorrect predictions. These types of attacks, known as "adversarial attacks," are a major concern in the field of Explainable Artificial Intelligence (XAI), as they can undermine the trust and reliability of AI systems.
The researchers first developed a conceptual framework to assess the quality of AI models, looking at factors like their robustness, explainability, and scalability. They then used this framework to evaluate the performance of several popular open-source AI vision models when subjected to adversarial attacks.
The key finding was that many of these models were highly vulnerable to adversarial attacks, meaning that small, carefully crafted changes to the input data could cause the models to make incorrect predictions. This is a significant problem, as it undermines the reliability and trustworthiness of these AI systems, especially in critical applications like autonomous vehicles or medical diagnosis.
Technical Explanation
The researchers developed a conceptual framework for assessing the quality attributes of AI models, including their robustness, explainability, scalability, and other factors. They then used this framework to evaluate the performance of several popular open-source AI vision models, such as ResNet, VGG, and YOLO, under adversarial attacks.
The adversarial attacks were generated using a variety of techniques, including the Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD), which are designed to create small, imperceptible changes to the input data that can cause the model to make incorrect predictions. The researchers measured the models' performance on standard computer vision benchmarks, as well as their robustness to these adversarial attacks.
The results showed that many of the tested models were highly vulnerable to adversarial attacks, with significant drops in accuracy and other quality metrics when subjected to the attacks. This highlights the need for more rigorous testing and quality assurance practices in the AI development ecosystem, as well as the importance of developing more robust and secure AI models that can withstand such malicious attempts to undermine their performance.
Critical Analysis
The paper provides a valuable contribution to the growing body of research on the security and reliability of AI systems, particularly in the context of computer vision applications. The conceptual framework developed by the researchers offers a structured approach to assessing the quality attributes of AI models, which could be useful for both researchers and practitioners working in this field.
However, the paper does have some limitations. The evaluation was limited to a relatively small set of popular open-source AI vision models, and it's possible that the findings may not be generalizable to other models or domains. Additionally, the paper does not provide much detail on the specific techniques used to generate the adversarial attacks, which makes it difficult to assess the robustness of the findings.
Further research is needed to explore the generalizability of these results, as well as to develop more sophisticated techniques for evaluating the security and reliability of AI systems. It would also be valuable to investigate the potential impact of these vulnerabilities on real-world applications, and to explore approaches for building more robust and secure AI models that can better withstand adversarial attacks.
Conclusion
This paper highlights the importance of rigorous quality assurance and security testing for AI vision models, particularly in the context of the growing use of these models in a wide range of applications. The findings suggest that many popular open-source AI models are highly vulnerable to adversarial attacks, which can undermine their reliability and trustworthiness.
The conceptual framework developed by the researchers provides a valuable tool for assessing the quality attributes of AI models, and the insights from this study could help inform the development of more robust and secure AI systems in the future. As the use of AI continues to expand, it will be increasingly important to address these security concerns to ensure the safe and reliable deployment of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cloud-based XAI Services for Assessing Open Repository Models Under Adversarial Attacks
Zerui Wang, Yan Liu
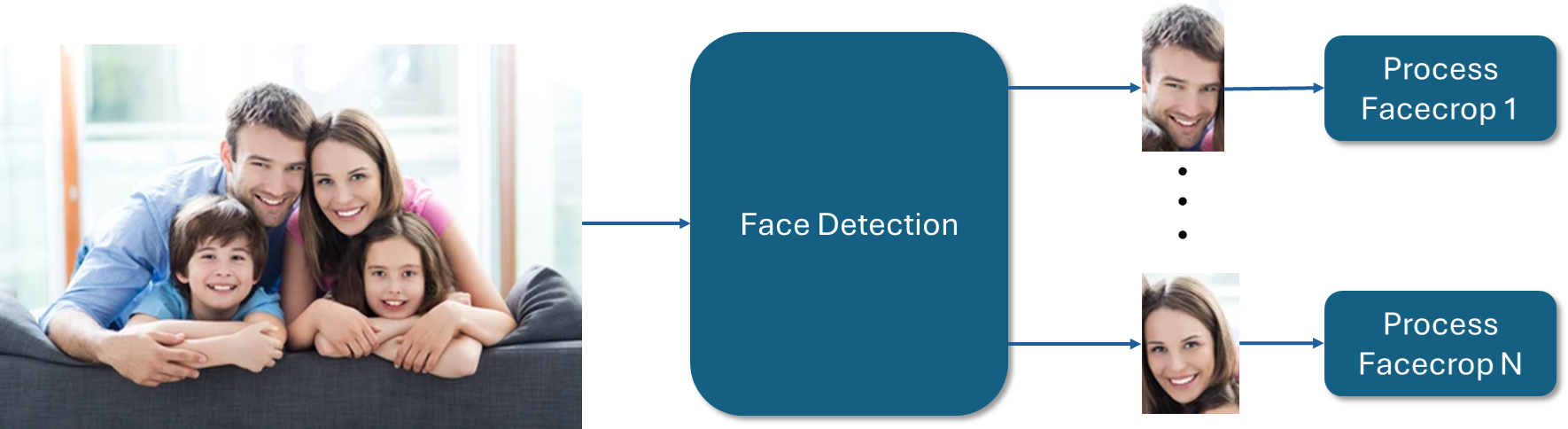
The opacity of AI models necessitates both validation and evaluation before their integration into services. To investigate these models, explainable AI (XAI) employs methods that elucidate the relationship between input features and output predictions. The operations of XAI extend beyond the execution of a single algorithm, involving a series of activities that include preprocessing data, adjusting XAI to align with model parameters, invoking the model to generate predictions, and summarizing the XAI results. Adversarial attacks are well-known threats that aim to mislead AI models. The assessment complexity, especially for XAI, increases when open-source AI models are subject to adversarial attacks, due to various combinations. To automate the numerous entities and tasks involved in XAI-based assessments, we propose a cloud-based service framework that encapsulates computing components as microservices and organizes assessment tasks into pipelines. The current XAI tools are not inherently service-oriented. This framework also integrates open XAI tool libraries as part of the pipeline composition. We demonstrate the application of XAI services for assessing five quality attributes of AI models: (1) computational cost, (2) performance, (3) robustness, (4) explanation deviation, and (5) explanation resilience across computer vision and tabular cases. The service framework generates aggregated analysis that showcases the quality attributes for more than a hundred combination scenarios.
Read more5/24/2024
0
XAI-Based Detection of Adversarial Attacks on Deepfake Detectors
Ben Pinhasov, Raz Lapid, Rony Ohayon, Moshe Sipper, Yehudit Aperstein
We introduce a novel methodology for identifying adversarial attacks on deepfake detectors using eXplainable Artificial Intelligence (XAI). In an era characterized by digital advancement, deepfakes have emerged as a potent tool, creating a demand for efficient detection systems. However, these systems are frequently targeted by adversarial attacks that inhibit their performance. We address this gap, developing a defensible deepfake detector by leveraging the power of XAI. The proposed methodology uses XAI to generate interpretability maps for a given method, providing explicit visualizations of decision-making factors within the AI models. We subsequently employ a pretrained feature extractor that processes both the input image and its corresponding XAI image. The feature embeddings extracted from this process are then used for training a simple yet effective classifier. Our approach contributes not only to the detection of deepfakes but also enhances the understanding of possible adversarial attacks, pinpointing potential vulnerabilities. Furthermore, this approach does not change the performance of the deepfake detector. The paper demonstrates promising results suggesting a potential pathway for future deepfake detection mechanisms. We believe this study will serve as a valuable contribution to the community, sparking much-needed discourse on safeguarding deepfake detectors.
Read more8/20/2024

0
Explainable Artificial Intelligence: A Survey of Needs, Techniques, Applications, and Future Direction
Melkamu Mersha, Khang Lam, Joseph Wood, Ali AlShami, Jugal Kalita
Artificial intelligence models encounter significant challenges due to their black-box nature, particularly in safety-critical domains such as healthcare, finance, and autonomous vehicles. Explainable Artificial Intelligence (XAI) addresses these challenges by providing explanations for how these models make decisions and predictions, ensuring transparency, accountability, and fairness. Existing studies have examined the fundamental concepts of XAI, its general principles, and the scope of XAI techniques. However, there remains a gap in the literature as there are no comprehensive reviews that delve into the detailed mathematical representations, design methodologies of XAI models, and other associated aspects. This paper provides a comprehensive literature review encompassing common terminologies and definitions, the need for XAI, beneficiaries of XAI, a taxonomy of XAI methods, and the application of XAI methods in different application areas. The survey is aimed at XAI researchers, XAI practitioners, AI model developers, and XAI beneficiaries who are interested in enhancing the trustworthiness, transparency, accountability, and fairness of their AI models.
Read more9/4/2024

0
More Questions than Answers? Lessons from Integrating Explainable AI into a Cyber-AI Tool
Ashley Suh, Harry Li, Caitlin Kenney, Kenneth Alperin, Steven R. Gomez
We share observations and challenges from an ongoing effort to implement Explainable AI (XAI) in a domain-specific workflow for cybersecurity analysts. Specifically, we briefly describe a preliminary case study on the use of XAI for source code classification, where accurate assessment and timeliness are paramount. We find that the outputs of state-of-the-art saliency explanation techniques (e.g., SHAP or LIME) are lost in translation when interpreted by people with little AI expertise, despite these techniques being marketed for non-technical users. Moreover, we find that popular XAI techniques offer fewer insights for real-time human-AI workflows when they are post hoc and too localized in their explanations. Instead, we observe that cyber analysts need higher-level, easy-to-digest explanations that can offer as little disruption as possible to their workflows. We outline unaddressed gaps in practical and effective XAI, then touch on how emerging technologies like Large Language Models (LLMs) could mitigate these existing obstacles.
Read more8/12/2024