COBIAS: Contextual Reliability in Bias Assessment

0
🚀
Sign in to get full access
Overview
- Large Language Models (LLMs) trained on web data can exhibit biases due to the diverse and often uncurated nature of the data
- Previous work on debiasing LLMs relies on benchmark datasets, but these datasets suffer from limitations due to the subjective nature of bias
- The authors propose an approach to understand the context of inputs and develop a metric to assess the contextual reliability of statements in measuring bias
Plain English Explanation
Large language models like those used for personalized recommendation systems or conversational AI are trained on massive amounts of text from the internet. This allows them to understand and generate human-like text. However, the data they are trained on also contains various stereotypes and prejudices, which can lead to biases in the models.
Previous research has tried to address these biases by using benchmark datasets to measure the effectiveness of debiasing techniques. But these datasets have their own issues - the understanding of bias is highly subjective, and the datasets may not capture the full context of when certain statements are made.
The authors propose a new approach that focuses on understanding the context in which statements are made. They augment existing bias benchmark datasets with additional context information, and develop a metric called COBIAS (Context-Oriented Bias Indicator and Assessment Score) to assess the contextual reliability of these statements in measuring bias. This allows for the creation of more reliable datasets to assist in the development of better bias mitigation techniques for large language models.
Technical Explanation
The researchers first collected 2,291 stereotyped statements from two existing bias benchmark datasets, IndiBias and CodIS. They then augmented these statements with additional context information, such as the circumstances in which the statement might be used.
To assess the contextual reliability of these statements, the researchers developed the COBIAS metric. COBIAS measures the extent to which a statement's meaning and implications change based on the surrounding context. The researchers found that COBIAS aligned well with human judgments on the contextual reliability of the statements (Spearman's rho = 0.65, p = 3.4 * 10^{-60}).
The COBIAS metric can be used to create more reliable datasets for evaluating bias mitigation techniques in large language models. By considering the context in which statements are made, researchers can develop a better understanding of the inherent biases in these models and design more effective debiasing strategies.
Critical Analysis
The authors acknowledge that their approach is limited by the subjective nature of bias, which makes it challenging to definitively determine the "correct" level of contextual information required to reliably measure bias. They also note that their dataset augmentation and COBIAS metric development were based on a specific set of existing bias benchmark datasets, which may not capture the full breadth of biases present in large language models.
Additionally, the researchers do not address the potential for the COBIAS metric itself to be biased or influenced by the subjective judgments of the human raters used in its development. There may be inherent biases in the way the human raters perceive and evaluate the contextual reliability of the statements.
Further research could explore the application of the COBIAS metric to a wider range of bias benchmark datasets, as well as the potential for machine learning techniques to automate the assessment of contextual reliability. This could help to reduce the reliance on subjective human judgments and lead to more robust and reliable bias measurement frameworks.
Conclusion
The authors of this paper have made an important contribution to the field of bias mitigation in large language models. By focusing on the context of inputs, they have highlighted a critical limitation in existing bias benchmark datasets and developed a promising metric to address this issue.
The COBIAS metric has the potential to enable the creation of more reliable datasets for evaluating bias mitigation techniques, which could in turn lead to the development of more effective strategies for addressing the inherent biases in large language models. This work represents a step towards a more holistic and contextual understanding of bias in these powerful AI systems, which is crucial for ensuring their responsible and ethical deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
COBIAS: Contextual Reliability in Bias Assessment
Priyanshul Govil, Hemang Jain, Vamshi Krishna Bonagiri, Aman Chadha, Ponnurangam Kumaraguru, Manas Gaur, Sanorita Dey
Large Language Models (LLMs) are trained on extensive web corpora, which enable them to understand and generate human-like text. However, this training process also results in inherent biases within the models. These biases arise from web data's diverse and often uncurated nature, containing various stereotypes and prejudices. Previous works on debiasing models rely on benchmark datasets to measure their method's performance. However, these datasets suffer from several pitfalls due to the highly subjective understanding of bias, highlighting a critical need for contextual exploration. We propose understanding the context of inputs by considering the diverse situations in which they may arise. Our contribution is two-fold: (i) we augment 2,291 stereotyped statements from two existing bias-benchmark datasets with points for adding context; (ii) we develop the Context-Oriented Bias Indicator and Assessment Score (COBIAS) to assess a statement's contextual reliability in measuring bias. Our metric aligns with human judgment on contextual reliability of statements (Spearman's $rho = 0.65, p = 3.4 * 10^{-60}$) and can be used to create reliable datasets, which would assist bias mitigation works.
Read more6/18/2024
0
CoS: Enhancing Personalization and Mitigating Bias with Context Steering
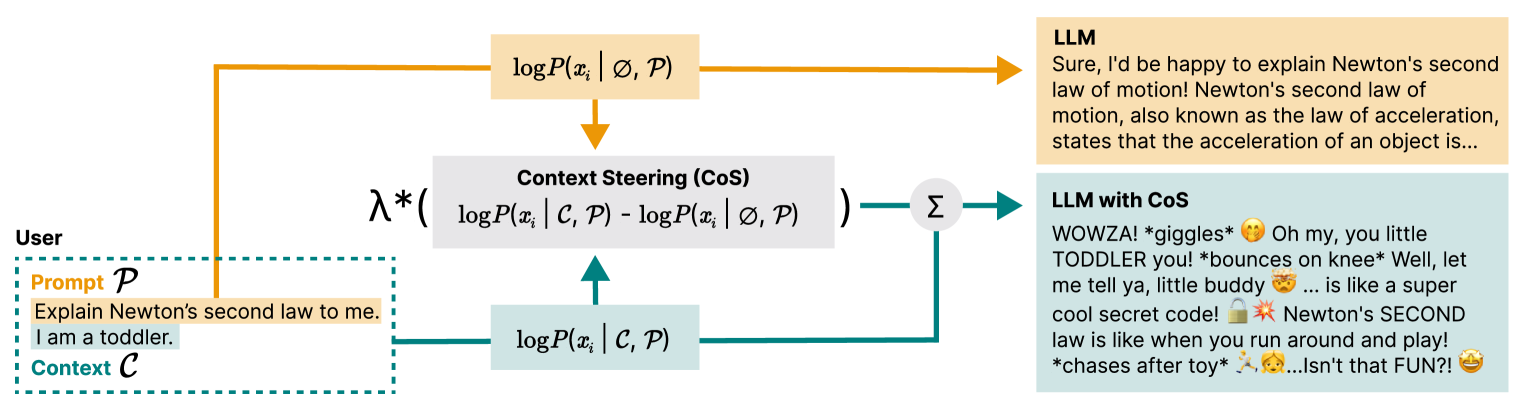
Jerry Zhi-Yang He, Sashrika Pandey, Mariah L. Schrum, Anca Dragan
When querying a large language model (LLM), the context, i.e. personal, demographic, and cultural information specific to an end-user, can significantly shape the response of the LLM. For example, asking the model to explain Newton's second law with the context I am a toddler yields a different answer compared to the context I am a physics professor. Proper usage of the context enables the LLM to generate personalized responses, whereas inappropriate contextual influence can lead to stereotypical and potentially harmful generations (e.g. associating female with housekeeper). In practice, striking the right balance when leveraging context is a nuanced and challenging problem that is often situation-dependent. One common approach to address this challenge is to fine-tune LLMs on contextually appropriate responses. However, this approach is expensive, time-consuming, and not controllable for end-users in different situations. In this work, we propose Context Steering (CoS) - a simple training-free method that can be easily applied to autoregressive LLMs at inference time. By measuring the contextual influence in terms of token prediction likelihood and modulating it, our method enables practitioners to determine the appropriate level of contextual influence based on their specific use case and end-user base. We showcase a variety of applications of CoS including amplifying the contextual influence to achieve better personalization and mitigating unwanted influence for reducing model bias. In addition, we show that we can combine CoS with Bayesian Inference to quantify the extent of hate speech on the internet. We demonstrate the effectiveness of CoS on state-of-the-art LLMs and benchmarks.
Read more5/6/2024

0
MBIAS: Mitigating Bias in Large Language Models While Retaining Context
Shaina Raza, Ananya Raval, Veronica Chatrath
The deployment of Large Language Models (LLMs) in diverse applications necessitates an assurance of safety without compromising the contextual integrity of the generated content. Traditional approaches, including safety-specific fine-tuning or adversarial testing, often yield safe outputs at the expense of contextual meaning. This can result in a diminished capacity to handle nuanced aspects of bias and toxicity, such as underrepresentation or negative portrayals across various demographics. To address these challenges, we introduce MBIAS, an LLM framework carefully instruction fine-tuned on a custom dataset designed specifically for safety interventions. MBIAS is designed to significantly reduce biases and toxic elements in LLM outputs while preserving the main information. This work also details our further use of LLMs: as annotator under human supervision and as evaluator of generated content. Empirical analysis reveals that MBIAS achieves a reduction in bias and toxicity by over 30% in standard evaluations, and by more than 90% in diverse demographic tests, highlighting the robustness of our approach. We make the dataset and the fine-tuned model available to the research community for further investigation and ensure reproducibility. The code for this project can be accessed here https://github.com/shainarazavi/MBIAS/tree/main. Warning: This paper contains examples that may be offensive or upsetting.
Read more7/1/2024
💬
0
Exploring Subjectivity for more Human-Centric Assessment of Social Biases in Large Language Models
Paula Akemi Aoyagui, Sharon Ferguson, Anastasia Kuzminykh
An essential aspect of evaluating Large Language Models (LLMs) is identifying potential biases. This is especially relevant considering the substantial evidence that LLMs can replicate human social biases in their text outputs and further influence stakeholders, potentially amplifying harm to already marginalized individuals and communities. Therefore, recent efforts in bias detection invested in automated benchmarks and objective metrics such as accuracy (i.e., an LLMs output is compared against a predefined ground truth). Nonetheless, social biases can be nuanced, oftentimes subjective and context-dependent, where a situation is open to interpretation and there is no ground truth. While these situations can be difficult for automated evaluation systems to identify, human evaluators could potentially pick up on these nuances. In this paper, we discuss the role of human evaluation and subjective interpretation to augment automated processes when identifying biases in LLMs as part of a human-centred approach to evaluate these models.
Read more5/21/2024