CoS: Enhancing Personalization and Mitigating Bias with Context Steering

0
Sign in to get full access
Overview
- The paper focuses on enhancing personalization and mitigating bias in large language models (LLMs) using a technique called "context steering" (CoS).
- CoS aims to provide a way for users to steer the language model's outputs towards their desired context or persona, while also reducing unwanted biases in the generated text.
- The researchers propose a framework that combines personalization, debiasing, and controllability to improve the overall quality and usefulness of LLM outputs.
Plain English Explanation
The paper discusses a method called "context steering" (CoS) that can help make large language models (LLMs) more personalized and less biased. LLMs are AI systems that can generate human-like text, but they can sometimes produce biased or irrelevant outputs.
The researchers' idea with CoS is to give users more control over the language model, allowing them to steer the output towards their desired context or persona. For example, a user might want the language model to write in a more formal or casual tone, or to have a certain level of empathy or creativity. CoS aims to provide this personalization while also reducing unwanted biases in the generated text.
The researchers propose a framework that combines personalization, debiasing, and controllability to improve the overall quality and usefulness of LLM outputs. This could be helpful for a variety of applications, such as customizing language model responses using contrastive context learning, learning long contexts offline, or steering large language models towards data-driven goals.
Technical Explanation
The paper introduces a framework called "context steering" (CoS) that aims to enhance personalization and mitigate bias in large language models (LLMs). The key elements of the CoS framework are:
-
Personalization: CoS allows users to steer the language model's outputs towards their desired context or persona, such as a more formal or casual tone, or a certain level of empathy or creativity.
-
Debiasing: CoS also aims to reduce unwanted biases in the generated text, such as gender, racial, or political biases, by incorporating debiasing techniques into the framework.
-
Controllability: CoS provides users with a higher degree of control over the language model's outputs, enabling them to customize the generated text to better suit their needs or preferences.
To implement the CoS framework, the researchers propose several novel techniques, including collaborative stance detection using contrastive heterogeneous topic modeling and supervised knowledge enhancement for large language models.
The paper presents experiments and evaluations demonstrating the effectiveness of the CoS framework in enhancing personalization and mitigating bias, compared to traditional language modeling approaches.
Critical Analysis
The paper presents a compelling approach to improving the personalization and bias mitigation capabilities of large language models. However, a few potential limitations or areas for further research are worth considering:
-
Generalizability: The paper focuses on a specific framework and set of techniques for context steering. It would be valuable to explore how the core principles of CoS could be applied or adapted to other language modeling architectures or approaches.
-
User Interaction: The paper does not delve deeply into the user experience aspects of the CoS framework, such as how users would actually interact with and provide input to the system. Designing intuitive and effective user interfaces for context steering could be an important area for future research.
-
Ethical Considerations: While the paper emphasizes the importance of debiasing, there may be additional ethical implications or unintended consequences of providing users with increased control over language model outputs that warrant further examination.
-
Scalability: As language models continue to grow in size and complexity, it will be crucial to ensure that the CoS framework can scale effectively to maintain its performance and efficiency.
Overall, the CoS framework presented in the paper represents a promising step towards enhancing the personalization and bias mitigation capabilities of large language models, with potential applications across a wide range of domains.
Conclusion
The paper introduces a framework called "context steering" (CoS) that aims to enhance personalization and mitigate bias in large language models (LLMs). The key aspects of the CoS framework are personalization, debiasing, and controllability, which work together to improve the overall quality and usefulness of LLM outputs.
The researchers propose several novel techniques to implement the CoS framework, including collaborative stance detection and supervised knowledge enhancement. Experimental results demonstrate the effectiveness of CoS in improving personalization and reducing unwanted biases, compared to traditional language modeling approaches.
While the paper presents a compelling approach, there are also some potential limitations or areas for further research, such as generalizability, user interaction, ethical considerations, and scalability. Nevertheless, the CoS framework represents a promising step forward in the ongoing effort to make large language models more personalized, controllable, and socially responsible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CoS: Enhancing Personalization and Mitigating Bias with Context Steering
Jerry Zhi-Yang He, Sashrika Pandey, Mariah L. Schrum, Anca Dragan
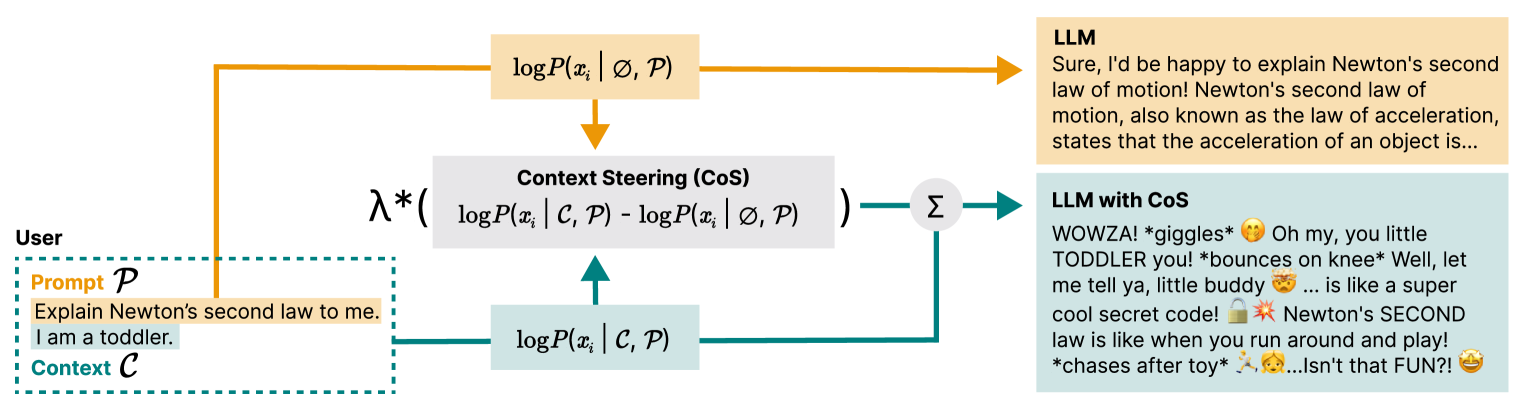
When querying a large language model (LLM), the context, i.e. personal, demographic, and cultural information specific to an end-user, can significantly shape the response of the LLM. For example, asking the model to explain Newton's second law with the context I am a toddler yields a different answer compared to the context I am a physics professor. Proper usage of the context enables the LLM to generate personalized responses, whereas inappropriate contextual influence can lead to stereotypical and potentially harmful generations (e.g. associating female with housekeeper). In practice, striking the right balance when leveraging context is a nuanced and challenging problem that is often situation-dependent. One common approach to address this challenge is to fine-tune LLMs on contextually appropriate responses. However, this approach is expensive, time-consuming, and not controllable for end-users in different situations. In this work, we propose Context Steering (CoS) - a simple training-free method that can be easily applied to autoregressive LLMs at inference time. By measuring the contextual influence in terms of token prediction likelihood and modulating it, our method enables practitioners to determine the appropriate level of contextual influence based on their specific use case and end-user base. We showcase a variety of applications of CoS including amplifying the contextual influence to achieve better personalization and mitigating unwanted influence for reducing model bias. In addition, we show that we can combine CoS with Bayesian Inference to quantify the extent of hate speech on the internet. We demonstrate the effectiveness of CoS on state-of-the-art LLMs and benchmarks.
Read more5/6/2024
🚀
0
COBIAS: Contextual Reliability in Bias Assessment
Priyanshul Govil, Hemang Jain, Vamshi Krishna Bonagiri, Aman Chadha, Ponnurangam Kumaraguru, Manas Gaur, Sanorita Dey
Large Language Models (LLMs) are trained on extensive web corpora, which enable them to understand and generate human-like text. However, this training process also results in inherent biases within the models. These biases arise from web data's diverse and often uncurated nature, containing various stereotypes and prejudices. Previous works on debiasing models rely on benchmark datasets to measure their method's performance. However, these datasets suffer from several pitfalls due to the highly subjective understanding of bias, highlighting a critical need for contextual exploration. We propose understanding the context of inputs by considering the diverse situations in which they may arise. Our contribution is two-fold: (i) we augment 2,291 stereotyped statements from two existing bias-benchmark datasets with points for adding context; (ii) we develop the Context-Oriented Bias Indicator and Assessment Score (COBIAS) to assess a statement's contextual reliability in measuring bias. Our metric aligns with human judgment on contextual reliability of statements (Spearman's $rho = 0.65, p = 3.4 * 10^{-60}$) and can be used to create reliable datasets, which would assist bias mitigation works.
Read more6/18/2024
💬
0
Improving Context-Aware Preference Modeling for Language Models
Silviu Pitis, Ziang Xiao, Nicolas Le Roux, Alessandro Sordoni
While finetuning language models from pairwise preferences has proven remarkably effective, the underspecified nature of natural language presents critical challenges. Direct preference feedback is uninterpretable, difficult to provide where multidimensional criteria may apply, and often inconsistent, either because it is based on incomplete instructions or provided by diverse principals. To address these challenges, we consider the two-step preference modeling procedure that first resolves the under-specification by selecting a context, and then evaluates preference with respect to the chosen context. We decompose reward modeling error according to these two steps, which suggests that supervising context in addition to context-specific preference may be a viable approach to aligning models with diverse human preferences. For this to work, the ability of models to evaluate context-specific preference is critical. To this end, we contribute context-conditioned preference datasets and accompanying experiments that investigate the ability of language models to evaluate context-specific preference. We use our datasets to (1) show that existing preference models benefit from, but fail to fully consider, added context, (2) finetune a context-aware reward model with context-specific performance exceeding that of GPT-4 and Llama 3 70B on tested datasets, and (3) investigate the value of context-aware preference modeling.
Read more7/23/2024

0
Contextualized Sequence Likelihood: Enhanced Confidence Scores for Natural Language Generation
Zhen Lin, Shubhendu Trivedi, Jimeng Sun
The advent of large language models (LLMs) has dramatically advanced the state-of-the-art in numerous natural language generation tasks. For LLMs to be applied reliably, it is essential to have an accurate measure of their confidence. Currently, the most commonly used confidence score function is the likelihood of the generated sequence, which, however, conflates semantic and syntactic components. For instance, in question-answering (QA) tasks, an awkward phrasing of the correct answer might result in a lower probability prediction. Additionally, different tokens should be weighted differently depending on the context. In this work, we propose enhancing the predicted sequence probability by assigning different weights to various tokens using attention values elicited from the base LLM. By employing a validation set, we can identify the relevant attention heads, thereby significantly improving the reliability of the vanilla sequence probability confidence measure. We refer to this new score as the Contextualized Sequence Likelihood (CSL). CSL is easy to implement, fast to compute, and offers considerable potential for further improvement with task-specific prompts. Across several QA datasets and a diverse array of LLMs, CSL has demonstrated significantly higher reliability than state-of-the-art baselines in predicting generation quality, as measured by the AUROC or AUARC.
Read more6/5/2024