CodeHalu: Code Hallucinations in LLMs Driven by Execution-based Verification
2405.00253
0
0
🌿
Abstract
Large Language Models (LLMs) have made significant progress in code generation, providing developers with unprecedented automated programming support. However, LLMs often generate code that is syntactically correct and even semantically plausible but may not execute as expected or meet specified requirements. This phenomenon of hallucinations in the code domain has not been systematically explored. To enhance the community's understanding and research on this issue, we introduce the concept of code hallucinations and propose a classification method for code hallucination based on execution verification. We classify code hallucinations into four main types: mapping, naming, resource, and logic hallucinations, with each category further divided into different subcategories to understand and address the unique challenges faced by LLMs in code generation with finer granularity. Additionally, we develop a dynamic detection algorithm named CodeHalu to quantify code hallucinations and establish the CodeHaluEval benchmark, which includes 8,883 samples from 699 tasks to systematically and quantitatively evaluate code hallucinations. By evaluating 17 popular LLMs on this benchmark, we reveal significant differences in their accuracy and reliability in code generation and provide detailed insights for further improving the code generation capabilities of LLMs. The CodeHalu benchmark and code are publicly available at https://github.com/yuchen814/CodeHalu.
Create account to get full access
Overview
- Large Language Models (LLMs) have made significant advancements in code generation, but they can sometimes produce code that appears plausible but doesn't meet requirements or execute correctly.
- This phenomenon of "code hallucinations" has not been well-explored, so the researchers propose a definition and classification system to better understand the challenges.
- They introduce the CodeHalu benchmark to systematically evaluate code hallucinations in 16 popular LLMs.
Plain English Explanation
Large language models (LLMs) are AI systems that can generate human-like text, and they've become incredibly good at writing code as well. However, the code they produce doesn't always work as expected. Sometimes the code looks plausible, but when you try to run it, it doesn't do what it's supposed to do. The researchers call this "code hallucination," where the model imagines code that seems reasonable but is actually incorrect.
To better understand this issue, the researchers came up with a way to define and categorize different types of code hallucinations. They identified four main types: mapping hallucinations (where the model misunderstands how different parts of the code should fit together), naming hallucinations (where the model uses confusing or incorrect variable/function names), resource hallucinations (where the model references resources that don't exist), and logic hallucinations (where the model's understanding of how the code should behave is flawed).
To test how often these hallucinations occur, the researchers created a benchmark called CodeHalu with thousands of code samples. They then tested 16 popular LLMs to see how often they produced hallucinated code. The results showed that these models can be quite unreliable when it comes to generating functional code, highlighting the need for improvements in model training and architecture to ensure the safety and accuracy of automatically generated code.
Technical Explanation
The researchers propose a systematic approach to defining and categorizing code hallucinations in LLMs. They start by defining code hallucinations as instances where an LLM generates code that appears plausible but fails to meet the expected requirements or executes incorrectly.
To better understand this phenomenon, the researchers categorize code hallucinations into four main types:
- Mapping Hallucinations: Where the model misunderstands how different parts of the code should fit together.
- Naming Hallucinations: Where the model uses confusing or incorrect variable/function names.
- Resource Hallucinations: Where the model references resources that don't exist.
- Logic Hallucinations: Where the model's understanding of how the code should behave is flawed.
To evaluate these hallucinations, the researchers developed a dynamic detection algorithm and constructed the CodeHalu benchmark, which includes 8,883 samples from 699 tasks. They tested 16 popular LLMs on this benchmark to measure the frequency and nature of their hallucinations during code generation.
The results revealed significant variations in the accuracy and reliability of LLMs in generating functional code, highlighting the need for further research and improvements to ensure the safety and correctness of automatically generated code.
Critical Analysis
The researchers provide a valuable framework for understanding and quantifying the issue of code hallucinations in LLMs. By categorizing the different types of hallucinations, they offer a structured approach to analyzing and addressing this problem.
However, the paper does not explore the underlying causes of these hallucinations, such as potential biases in the training data or limitations in the model architectures. Additionally, the CodeHalu benchmark may not capture the full breadth of real-world programming tasks, and the researchers acknowledge the need for further research and refinement of the benchmark.
The paper also does not discuss potential mitigation strategies or approaches to enhancing the summarization capabilities of LLMs to reduce the occurrence of hallucinations. Exploring techniques like multi-modal LLMs or improved training methods could be valuable areas for future research.
Overall, this study provides a solid foundation for understanding and measuring code hallucinations in LLMs, but there is still much work to be done to address the underlying challenges and ensure the reliable and safe generation of code by these powerful AI systems.
Conclusion
This paper introduces the concept of code hallucinations in LLMs and proposes a systematic approach to defining and categorizing these phenomena. By creating the CodeHalu benchmark, the researchers were able to quantify the frequency and nature of hallucinations in 16 popular LLMs.
The findings reveal significant variations in the accuracy and reliability of these models when it comes to generating functional code, highlighting the urgent need for further research and improvements to ensure the safety and correctness of automatically generated code. This study offers valuable insights for the broader AI community and lays the groundwork for future work on enhancing the robustness and reliability of LLMs in the context of code generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring and Evaluating Hallucinations in LLM-Powered Code Generation
Fang Liu, Yang Liu, Lin Shi, Houkun Huang, Ruifeng Wang, Zhen Yang, Li Zhang, Zhongqi Li, Yuchi Ma
0
0
The rise of Large Language Models (LLMs) has significantly advanced many applications on software engineering tasks, particularly in code generation. Despite the promising performance, LLMs are prone to generate hallucinations, which means LLMs might produce outputs that deviate from users' intent, exhibit internal inconsistencies, or misalign with the factual knowledge, making the deployment of LLMs potentially risky in a wide range of applications. Existing work mainly focuses on investing the hallucination in the domain of natural language generation (NLG), leaving a gap in understanding the types and extent of hallucinations in the context of code generation. To bridge the gap, we conducted a thematic analysis of the LLM-generated code to summarize and categorize the hallucinations present in it. Our study established a comprehensive taxonomy of hallucinations in LLM-generated code, encompassing 5 primary categories of hallucinations depending on the conflicting objectives and varying degrees of deviation observed in code generation. Furthermore, we systematically analyzed the distribution of hallucinations, exploring variations among different LLMs and their correlation with code correctness. Based on the results, we proposed HalluCode, a benchmark for evaluating the performance of code LLMs in recognizing hallucinations. Hallucination recognition and mitigation experiments with HalluCode and HumanEval show existing LLMs face great challenges in recognizing hallucinations, particularly in identifying their types, and are hardly able to mitigate hallucinations. We believe our findings will shed light on future research about hallucination evaluation, detection, and mitigation, ultimately paving the way for building more effective and reliable code LLMs in the future.
5/14/2024
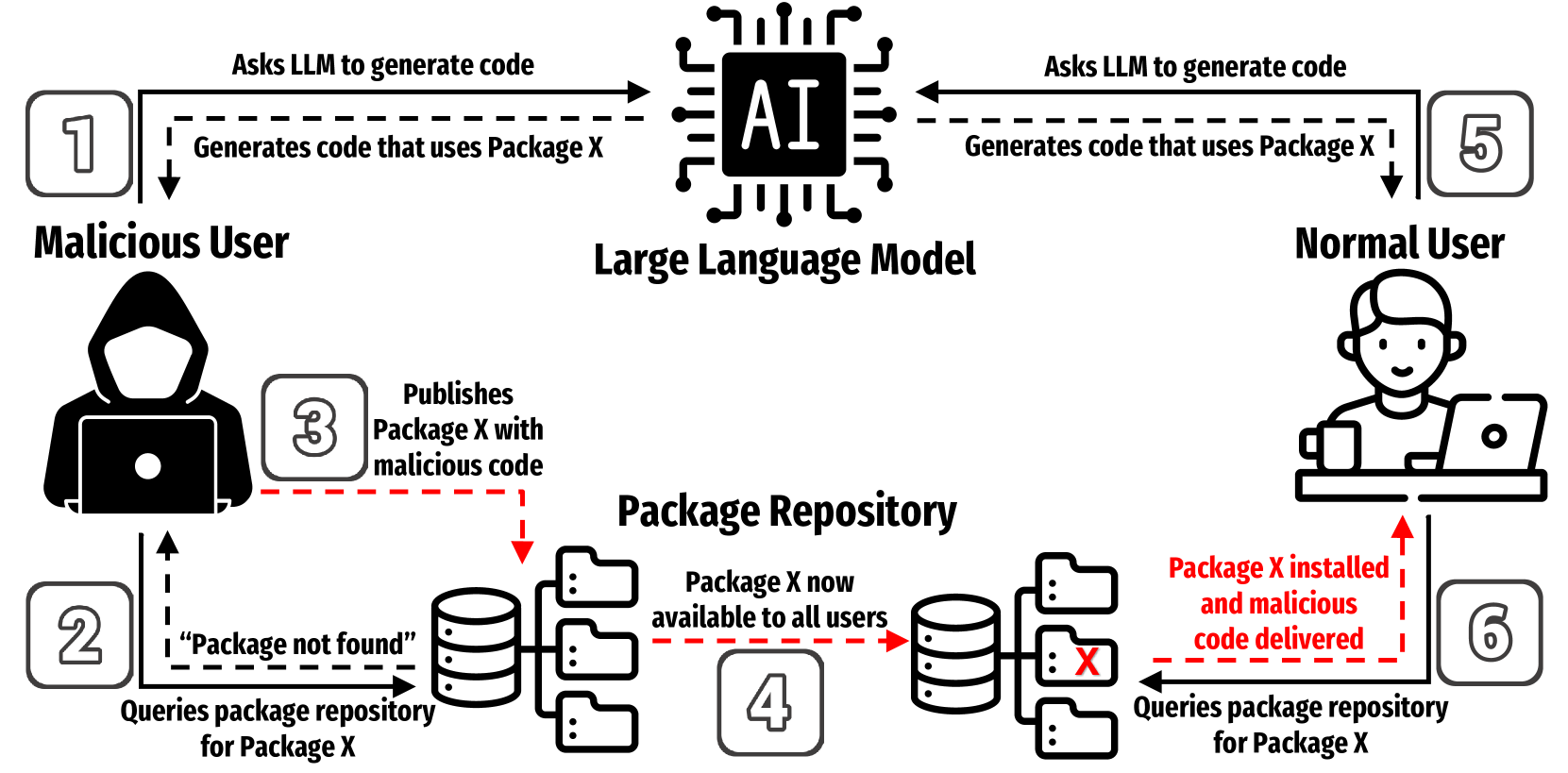
We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs
Joseph Spracklen, Raveen Wijewickrama, A H M Nazmus Sakib, Anindya Maiti, Murtuza Jadliwala
0
0
The reliance of popular programming languages such as Python and JavaScript on centralized package repositories and open-source software, combined with the emergence of code-generating Large Language Models (LLMs), has created a new type of threat to the software supply chain: package hallucinations. These hallucinations, which arise from fact-conflicting errors when generating code using LLMs, represent a novel form of package confusion attack that poses a critical threat to the integrity of the software supply chain. This paper conducts a rigorous and comprehensive evaluation of package hallucinations across different programming languages, settings, and parameters, exploring how different configurations of LLMs affect the likelihood of generating erroneous package recommendations and identifying the root causes of this phenomena. Using 16 different popular code generation models, across two programming languages and two unique prompt datasets, we collect 576,000 code samples which we analyze for package hallucinations. Our findings reveal that 19.7% of generated packages across all the tested LLMs are hallucinated, including a staggering 205,474 unique examples of hallucinated package names, further underscoring the severity and pervasiveness of this threat. We also implemented and evaluated mitigation strategies based on Retrieval Augmented Generation (RAG), self-detected feedback, and supervised fine-tuning. These techniques demonstrably reduced package hallucinations, with hallucination rates for one model dropping below 3%. While the mitigation efforts were effective in reducing hallucination rates, our study reveals that package hallucinations are a systemic and persistent phenomenon that pose a significant challenge for code generating LLMs.
6/18/2024
💬
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
0
0
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
4/30/2024

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024