Collaborative Vision-Text Representation Optimizing for Open-Vocabulary Segmentation

0

Sign in to get full access
Overview
- This paper presents a collaborative vision-text representation model optimized for open-vocabulary segmentation.
- The model learns joint visual-textual embeddings that can be used for various downstream tasks, including open-vocabulary object detection and segmentation.
- The authors propose a novel training approach that leverages both image-text and instance-level annotations to learn more effective representations.
Plain English Explanation
The researchers developed a machine learning model that can understand the connection between visual images and textual descriptions. This allows the model to recognize and segment objects in images using a wide range of vocabulary terms, not just a predefined set.
To train the model, the researchers used two types of data:
- Image-text pairs, where each image is paired with a written description of its contents.
- Instance-level annotations, where specific objects in an image are labeled with their names.
By using both of these data sources, the model was able to learn a [object Object] - a way of representing visual and textual information in a shared mathematical space. This allows the model to understand the relationships between what it sees in an image and what is described in text.
The key benefit of this approach is that the model can then be used for [object Object]. Instead of only being able to recognize a predefined set of object categories, it can detect and segment any object that is described in the training text data. This makes the model much more flexible and applicable to a wider range of real-world scenarios.
Technical Explanation
The researchers propose a Collaborative Vision-Text Representation (CoVT) model that learns joint visual-textual embeddings optimized for open-vocabulary segmentation. The key components are:
-
Vision-Text Encoder: A transformer-based architecture that encodes both image and text inputs into a shared embedding space. This allows the model to learn the relationship between visual and textual features.
-
Instance-Level Segmentation Head: A segmentation head that can predict pixel-level masks for objects described by any textual label, not just a predefined vocabulary.
-
Multi-Task Training: The model is trained on both image-text pairs (for general visual-textual alignment) and instance-level annotations (for learning detailed object segmentation).
The researchers evaluate the model on several open-vocabulary object detection and segmentation benchmarks, showing that it outperforms prior methods that rely on predefined vocabularies. The joint visual-textual representations learned by CoVT are a key enabler of this improved performance.
Critical Analysis
The paper makes a convincing case for the benefits of the proposed CoVT model for open-vocabulary segmentation. However, a few potential limitations and areas for future work are worth considering:
-
Dataset Bias: The performance of the model may be influenced by biases present in the training datasets, such as over-representation of certain object categories or linguistic patterns. Further analysis of dataset composition and its impact on model generalization would be valuable.
-
Computational Efficiency: Transformer-based architectures like CoVT can be computationally intensive, which may limit their deployment in real-world applications with strict latency requirements. Exploring more efficient model designs or compression techniques could help address this.
-
Multimodal Alignment: While the paper focuses on aligning vision and text, there may be opportunities to further leverage other modalities, such as audio or video, to learn even richer multimodal representations.
-
[object Object]: As with many deep learning models, understanding the inner workings of CoVT and ensuring its robustness to adversarial inputs or distribution shifts could be an important area for future research.
Conclusion
The Collaborative Vision-Text Representation (CoVT) model presented in this paper represents an important step forward in [object Object]. By learning joint visual-textual embeddings and leveraging both image-text and instance-level annotations, the model can recognize and segment objects described by a wide range of textual labels, going beyond the limitations of predefined vocabularies.
This advance has the potential to enhance a variety of real-world applications, from assistive technologies to robotic vision systems, by enabling more flexible and adaptive understanding of visual scenes. As the field of [object Object] continues to evolve, the insights and techniques presented in this paper are likely to inspire further research and development in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Collaborative Vision-Text Representation Optimizing for Open-Vocabulary Segmentation
Siyu Jiao, Hongguang Zhu, Jiannan Huang, Yao Zhao, Yunchao Wei, Humphrey Shi
Pre-trained vision-language models, e.g. CLIP, have been increasingly used to address the challenging Open-Vocabulary Segmentation (OVS) task, benefiting from their well-aligned vision-text embedding space. Typical solutions involve either freezing CLIP during training to unilaterally maintain its zero-shot capability, or fine-tuning CLIP vision encoder to achieve perceptual sensitivity to local regions. However, few of them incorporate vision-text collaborative optimization. Based on this, we propose the Content-Dependent Transfer to adaptively enhance each text embedding by interacting with the input image, which presents a parameter-efficient way to optimize the text representation. Besides, we additionally introduce a Representation Compensation strategy, reviewing the original CLIP-V representation as compensation to maintain the zero-shot capability of CLIP. In this way, the vision and text representation of CLIP are optimized collaboratively, enhancing the alignment of the vision-text feature space. To the best of our knowledge, we are the first to establish the collaborative vision-text optimizing mechanism within the OVS field. Extensive experiments demonstrate our method achieves superior performance on popular OVS benchmarks. In open-vocabulary semantic segmentation, our method outperforms the previous state-of-the-art approaches by +0.5, +2.3, +3.4, +0.4 and +1.1 mIoU, respectively on A-847, A-150, PC-459, PC-59 and PAS-20. Furthermore, in a panoptic setting on ADE20K, we achieve the performance of 27.1 PQ, 73.5 SQ, and 32.9 RQ. Code will be available at https://github.com/jiaosiyu1999/MAFT-Plus.git .
Read more8/2/2024
👀
0
Enhancing Vision Models for Text-Heavy Content Understanding and Interaction
Adithya TG, Adithya SK, Abhinav R Bharadwaj, Abhiram HA, Dr. Surabhi Narayan
Interacting and understanding with text heavy visual content with multiple images is a major challenge for traditional vision models. This paper is on enhancing vision models' capability to comprehend or understand and learn from images containing a huge amount of textual information from the likes of textbooks and research papers which contain multiple images like graphs, etc and tables in them with different types of axes and scales. The approach involves dataset preprocessing, fine tuning which is by using instructional oriented data and evaluation. We also built a visual chat application integrating CLIP for image encoding and a model from the Massive Text Embedding Benchmark which is developed to consider both textual and visual inputs. An accuracy of 96.71% was obtained. The aim of the project is to increase and also enhance the advance vision models' capabilities in understanding complex visual textual data interconnected data, contributing to multimodal AI.
Read more6/3/2024
0
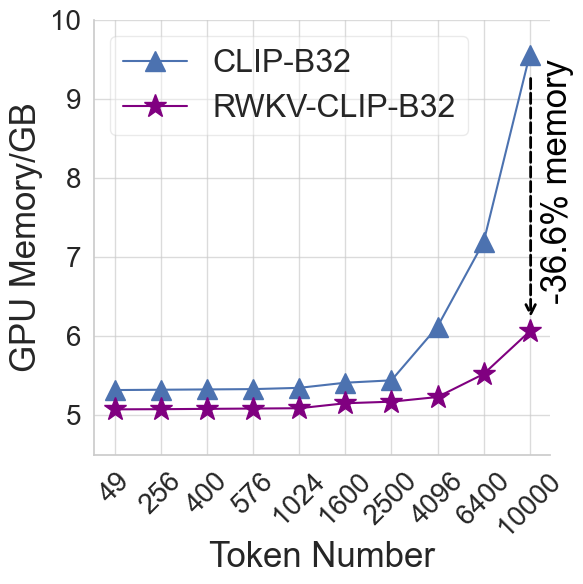
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
Read more6/12/2024

0
Optimizing CLIP Models for Image Retrieval with Maintained Joint-Embedding Alignment
Konstantin Schall, Kai Uwe Barthel, Nico Hezel, Klaus Jung
Contrastive Language and Image Pairing (CLIP), a transformative method in multimedia retrieval, typically trains two neural networks concurrently to generate joint embeddings for text and image pairs. However, when applied directly, these models often struggle to differentiate between visually distinct images that have similar captions, resulting in suboptimal performance for image-based similarity searches. This paper addresses the challenge of optimizing CLIP models for various image-based similarity search scenarios, while maintaining their effectiveness in text-based search tasks such as text-to-image retrieval and zero-shot classification. We propose and evaluate two novel methods aimed at refining the retrieval capabilities of CLIP without compromising the alignment between text and image embeddings. The first method involves a sequential fine-tuning process: initially optimizing the image encoder for more precise image retrieval and subsequently realigning the text encoder to these optimized image embeddings. The second approach integrates pseudo-captions during the retrieval-optimization phase to foster direct alignment within the embedding space. Through comprehensive experiments, we demonstrate that these methods enhance CLIP's performance on various benchmarks, including image retrieval, k-NN classification, and zero-shot text-based classification, while maintaining robustness in text-to-image retrieval. Our optimized models permit maintaining a single embedding per image, significantly simplifying the infrastructure needed for large-scale multi-modal similarity search systems.
Read more9/4/2024