ColPali: Efficient Document Retrieval with Vision Language Models

1

Sign in to get full access
Overview
- This paper introduces ColPali, a novel approach for efficient document retrieval using vision-language models.
- ColPali leverages the capabilities of large multimodal models to jointly represent and retrieve documents from both textual and visual content.
- The authors demonstrate that ColPali outperforms traditional text-based retrieval methods on a range of benchmark datasets, highlighting the advantages of integrating visual information for document understanding and retrieval.
Plain English Explanation
ColPali is a new way to search for and retrieve documents that uses both the text and the images in the documents. Traditional document retrieval systems only look at the text, but ColPali also considers the visual information, like photos or diagrams, to better understand the content of the document.
The key idea behind ColPali is to use large artificial intelligence models that have been trained on a vast amount of text and images. These models can learn to represent the meaning of both the text and visual content in a shared, multidimensional space. When you search for a document, ColPali can compare your query to this joint representation to find the most relevant documents, even if they don't contain the exact words you used in your search.
The researchers show that this approach outperforms traditional text-only search methods on standard benchmark datasets. By considering both the text and visual elements, ColPali can better capture the true meaning and content of documents, leading to more accurate and relevant search results.
This is an important advancement because many real-world documents, like research papers, technical manuals, or business reports, contain a mix of text and visual information. Incorporating this visual data can help users find the most relevant information more efficiently, which has applications in research, education, and various professional domains.
Technical Explanation
ColPali builds on recent progress in vision-language models, which can jointly represent textual and visual content in a shared embedding space. The authors leverage these models to develop a novel document retrieval system that can efficiently search and retrieve relevant documents based on both their textual and visual characteristics.
The core of ColPali is a two-stage retrieval process. First, the system encodes the query and documents into a joint text-image representation using a pre-trained vision-language model. This allows the system to capture the semantic relationships between the query and the document content, including both the text and any associated images or diagrams.
In the second stage, ColPali performs efficient nearest neighbor search in the joint embedding space to identify the most relevant documents for the given query. The authors demonstrate the effectiveness of this approach on several standard document retrieval benchmarks, showing significant performance gains over traditional text-based methods and hybrid approaches.
Additionally, the authors explore strategies to further enhance the performance of ColPali, such as leveraging text-heavy content understanding and visually-situated natural language processing. These extensions demonstrate the flexibility and potential of the ColPali framework to address a wide range of document retrieval scenarios.
Critical Analysis
The ColPali approach represents a promising step towards more efficient and accurate document retrieval systems. By jointly considering both textual and visual information, the authors show that the system can better capture the true meaning and content of documents, leading to improved search performance.
However, the paper does not address some potential limitations and areas for future research. For example, the performance of ColPali may be sensitive to the quality and coverage of the training data used to build the underlying vision-language model. Evaluating the system's robustness to noisy or incomplete visual information in documents would be an important area for further investigation.
Additionally, the paper does not provide a detailed analysis of the computational efficiency and scalability of the ColPali approach, which would be crucial for real-world deployment in large-scale document repositories. Exploring strategies to optimize the retrieval process, such as efficient indexing or approximate nearest neighbor search, could be valuable extensions to the current work.
Overall, the ColPali framework presents an exciting direction for document retrieval research, leveraging the power of multimodal AI models to enhance the understanding and retrieval of complex, multimedia documents. As the field of vision-language understanding continues to evolve, further advancements in this area could have significant implications for a wide range of information management and knowledge discovery applications.
Conclusion
The ColPali paper introduces a novel approach for efficient document retrieval that leverages the joint representation of textual and visual information. By using advanced vision-language models, the system can better capture the semantic content of documents, leading to improved search performance compared to traditional text-based methods.
The key innovation of ColPali is its ability to integrate visual data, such as images and diagrams, into the document retrieval process. This allows the system to more accurately understand the true meaning and context of the document content, which is particularly valuable for domains where documents contain a mix of text and visual elements.
The demonstrated performance gains on standard benchmarks highlight the potential of this approach to transform how users search for and access relevant information, with applications across research, education, and various professional settings. As the field of multimodal AI continues to advance, further research and development of systems like ColPali could have far-reaching implications for the way we interact with and make sense of the growing volume of digital information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
ColPali: Efficient Document Retrieval with Vision Language Models
Manuel Faysse, Hugues Sibille, Tony Wu, Gautier Viaud, C'eline Hudelot, Pierre Colombo
Documents are visually rich structures that convey information through text, as well as tables, figures, page layouts, or fonts. While modern document retrieval systems exhibit strong performance on query-to-text matching, they struggle to exploit visual cues efficiently, hindering their performance on practical document retrieval applications such as Retrieval Augmented Generation. To benchmark current systems on visually rich document retrieval, we introduce the Visual Document Retrieval Benchmark ViDoRe, composed of various page-level retrieving tasks spanning multiple domains, languages, and settings. The inherent shortcomings of modern systems motivate the introduction of a new retrieval model architecture, ColPali, which leverages the document understanding capabilities of recent Vision Language Models to produce high-quality contextualized embeddings solely from images of document pages. Combined with a late interaction matching mechanism, ColPali largely outperforms modern document retrieval pipelines while being drastically faster and end-to-end trainable.
Read more7/2/2024
🖼️
0
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Hongyi Zhu, Jia-Hong Huang, Stevan Rudinac, Evangelos Kanoulas
Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
Read more4/30/2024
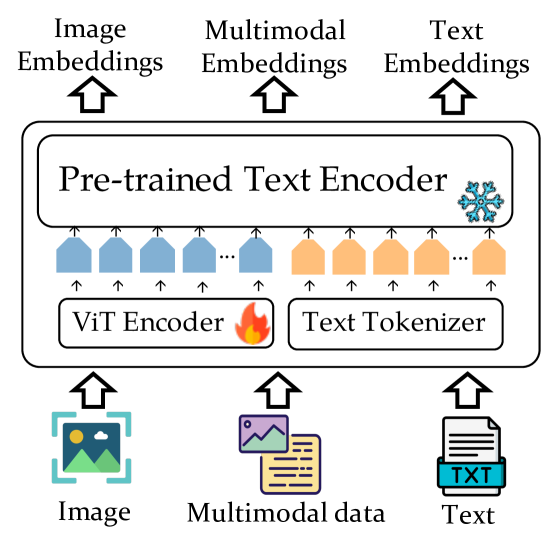
0
VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval
Junjie Zhou, Zheng Liu, Shitao Xiao, Bo Zhao, Yongping Xiong
Multi-modal retrieval becomes increasingly popular in practice. However, the existing retrievers are mostly text-oriented, which lack the capability to process visual information. Despite the presence of vision-language models like CLIP, the current methods are severely limited in representing the text-only and image-only data. In this work, we present a new embedding model VISTA for universal multi-modal retrieval. Our work brings forth threefold technical contributions. Firstly, we introduce a flexible architecture which extends a powerful text encoder with the image understanding capability by introducing visual token embeddings. Secondly, we develop two data generation strategies, which bring high-quality composed image-text to facilitate the training of the embedding model. Thirdly, we introduce a multi-stage training algorithm, which first aligns the visual token embedding with the text encoder using massive weakly labeled data, and then develops multi-modal representation capability using the generated composed image-text data. In our experiments, VISTA achieves superior performances across a variety of multi-modal retrieval tasks in both zero-shot and supervised settings. Our model, data, and source code are available at https://github.com/FlagOpen/FlagEmbedding.
Read more6/7/2024

0
DocReLM: Mastering Document Retrieval with Language Model
Gengchen Wei, Xinle Pang, Tianning Zhang, Yu Sun, Xun Qian, Chen Lin, Han-Sen Zhong, Wanli Ouyang
With over 200 million published academic documents and millions of new documents being written each year, academic researchers face the challenge of searching for information within this vast corpus. However, existing retrieval systems struggle to understand the semantics and domain knowledge present in academic papers. In this work, we demonstrate that by utilizing large language models, a document retrieval system can achieve advanced semantic understanding capabilities, significantly outperforming existing systems. Our approach involves training the retriever and reranker using domain-specific data generated by large language models. Additionally, we utilize large language models to identify candidates from the references of retrieved papers to further enhance the performance. We use a test set annotated by academic researchers in the fields of quantum physics and computer vision to evaluate our system's performance. The results show that DocReLM achieves a Top 10 accuracy of 44.12% in computer vision, compared to Google Scholar's 15.69%, and an increase to 36.21% in quantum physics, while that of Google Scholar is 12.96%.
Read more5/21/2024