A Comprehensive Evaluation on Event Reasoning of Large Language Models

0

Sign in to get full access
Overview
- This paper provides a comprehensive evaluation of the event reasoning capabilities of large language models (LLMs).
- The authors assess the performance of LLMs on various event-related tasks, including evaluating interventional reasoning capabilities of LLMs, evaluating consistency reasoning capabilities of LLMs, and evaluating deductive competence of LLMs.
- The findings have important implications for understanding the reasoning abilities of LLMs and their potential applications in real-world scenarios.
Plain English Explanation
The paper examines how well large language models, such as GPT-3 and BERT, can reason about events and their relationships. The researchers designed a series of tests to assess different aspects of event reasoning, including the models' ability to understand the consequences of interventions, maintain consistency in their reasoning, and draw logical deductions.
The results provide insights into the strengths and limitations of these powerful language models when it comes to reasoning about real-world events and their implications. This information is crucial for understanding how LLMs can be used in practical applications, such as decision-making, planning, and risk assessment. The findings can also help guide the development of more advanced models with improved event reasoning capabilities.
Technical Explanation
The paper presents a comprehensive evaluation of the event reasoning capabilities of large language models (LLMs). The authors designed a series of experiments to assess different aspects of event reasoning, including interventional reasoning, consistency reasoning, and deductive competence.
The interventional reasoning task evaluated the models' ability to understand the consequences of hypothetical interventions on events. The consistency reasoning task assessed the models' ability to maintain logical coherence in their reasoning about events. The deductive competence task measured the models' ability to draw valid logical conclusions from given premises.
The researchers used a diverse set of LLMs, including GPT-3, BERT, and others, and compared their performance on these event reasoning tasks. They found that while the models demonstrated some event reasoning capabilities, there were also significant limitations and inconsistencies in their performance.
The LLM Reasoners: A New Evaluation Library and Analysis library was used to conduct the experiments and analyze the results.
Critical Analysis
The paper provides a thorough and systematic evaluation of event reasoning capabilities in LLMs, which is a crucial aspect of their overall reasoning abilities. The authors have designed well-structured experiments to assess different facets of event reasoning, which allows for a more comprehensive understanding of the models' strengths and weaknesses.
However, the paper does not delve into the potential reasons behind the observed limitations in the models' event reasoning capabilities. It would be valuable to further investigate the architectural and training-related factors that may contribute to these limitations, as this could inform the development of more robust and capable event reasoning models.
Additionally, the paper does not explore the potential impact of these event reasoning limitations on real-world applications, such as decision-making, planning, or risk assessment. A deeper discussion on the practical implications of the findings and the steps needed to address the identified shortcomings would enhance the paper's overall contribution.
Conclusion
This paper presents a comprehensive evaluation of the event reasoning capabilities of large language models, examining their performance on tasks related to interventional reasoning, consistency reasoning, and deductive competence. The findings provide valuable insights into the current state of event reasoning in LLMs and highlight areas for further research and improvement.
Understanding the event reasoning capabilities of LLMs is crucial for their effective deployment in real-world applications that require robust reasoning about events and their consequences. The insights from this paper can inform the development of more advanced models with enhanced event reasoning capabilities, ultimately contributing to the advancement of artificial intelligence and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Comprehensive Evaluation on Event Reasoning of Large Language Models
Zhengwei Tao, Zhi Jin, Yifan Zhang, Xiancai Chen, Haiyan Zhao, Jia Li, Bing Liang, Chongyang Tao, Qun Liu, Kam-Fai Wong
Event reasoning is a fundamental ability that underlies many applications. It requires event schema knowledge to perform global reasoning and needs to deal with the diversity of the inter-event relations and the reasoning paradigms. How well LLMs accomplish event reasoning on various relations and reasoning paradigms remains unknown. To mitigate this disparity, we comprehensively evaluate the abilities of event reasoning of LLMs. We introduce a novel benchmark EV2 for EValuation of EVent reasoning. EV2 consists of two levels of evaluation of schema and instance and is comprehensive in relations and reasoning paradigms. We conduct extensive experiments on EV2. We find that LLMs have abilities to accomplish event reasoning but their performances are far from satisfactory. We also notice the imbalance of event reasoning abilities in LLMs. Besides, LLMs have event schema knowledge, however, they're not aligned with humans on how to utilize the knowledge. Based on these findings, we guide the LLMs in utilizing the event schema knowledge as memory leading to improvements on event reasoning.
Read more8/6/2024
0
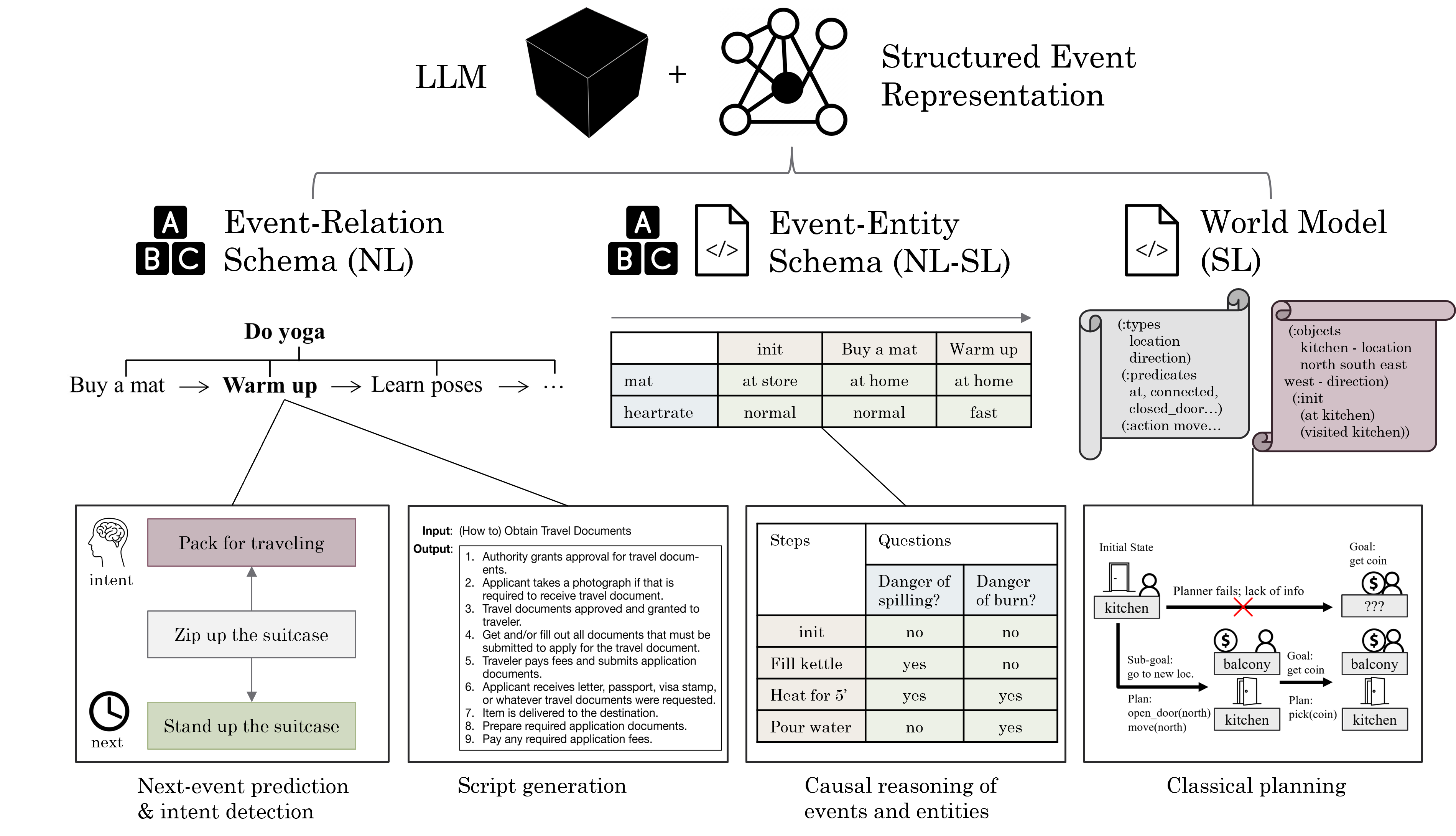
Structured Event Reasoning with Large Language Models
Li Zhang
Reasoning about real-life events is a unifying challenge in AI and NLP that has profound utility in a variety of domains, while fallacy in high-stake applications could be catastrophic. Able to work with diverse text in these domains, large language models (LLMs) have proven capable of answering questions and solving problems. However, I show that end-to-end LLMs still systematically fail to reason about complex events, and they lack interpretability due to their black-box nature. To address these issues, I propose three general approaches to use LLMs in conjunction with a structured representation of events. The first is a language-based representation involving relations of sub-events that can be learned by LLMs via fine-tuning. The second is a semi-symbolic representation involving states of entities that can be predicted and leveraged by LLMs via few-shot prompting. The third is a fully symbolic representation that can be predicted by LLMs trained with structured data and be executed by symbolic solvers. On a suite of event reasoning tasks spanning common-sense inference and planning, I show that each approach greatly outperforms end-to-end LLMs with more interpretability. These results suggest manners of synergy between LLMs and structured representations for event reasoning and beyond.
Read more8/30/2024
💬
1
Improving Large Language Models in Event Relation Logical Prediction
Meiqi Chen, Yubo Ma, Kaitao Song, Yixin Cao, Yan Zhang, Dongsheng Li
Event relations are crucial for narrative understanding and reasoning. Governed by nuanced logic, event relation extraction (ERE) is a challenging task that demands thorough semantic understanding and rigorous logical reasoning. In this paper, we conduct an in-depth investigation to systematically explore the capability of LLMs in understanding and applying event relation logic. More in detail, we first investigate the deficiencies of LLMs in logical reasoning across different tasks. Our study reveals that LLMs are not logically consistent reasoners, which results in their suboptimal performance on tasks that need rigorous reasoning. To address this, we explore three different approaches to endow LLMs with event relation logic, and thus enable them to generate more coherent answers across various scenarios. Based on our approach, we also contribute a synthesized dataset (LLM-ERL) involving high-order reasoning for evaluation and fine-tuning. Extensive quantitative and qualitative analyses on different tasks also validate the effectiveness of our approaches and provide insights for solving practical tasks with LLMs in future work. Codes are available at https://github.com/chenmeiqii/Teach-LLM-LR.
Read more8/12/2024

0
New!Are Large Language Models Really Good Logical Reasoners? A Comprehensive Evaluation and Beyond
Fangzhi Xu, Qika Lin, Jiawei Han, Tianzhe Zhao, Jun Liu, Erik Cambria
Logical reasoning consistently plays a fundamental and significant role in the domains of knowledge engineering and artificial intelligence. Recently, Large Language Models (LLMs) have emerged as a noteworthy innovation in natural language processing (NLP). However, the question of whether LLMs can effectively address the task of logical reasoning, which requires gradual cognitive inference similar to human intelligence, remains unanswered. To this end, we aim to bridge this gap and provide comprehensive evaluations in this paper. Firstly, to offer systematic evaluations, we select fifteen typical logical reasoning datasets and organize them into deductive, inductive, abductive and mixed-form reasoning settings. Considering the comprehensiveness of evaluations, we include 3 early-era representative LLMs and 4 trending LLMs. Secondly, different from previous evaluations relying only on simple metrics (e.g., emph{accuracy}), we propose fine-level evaluations in objective and subjective manners, covering both answers and explanations, including emph{answer correctness}, emph{explain correctness}, emph{explain completeness} and emph{explain redundancy}. Additionally, to uncover the logical flaws of LLMs, problematic cases will be attributed to five error types from two dimensions, i.e., emph{evidence selection process} and emph{reasoning process}. Thirdly, to avoid the influences of knowledge bias and concentrate purely on benchmarking the logical reasoning capability of LLMs, we propose a new dataset with neutral content. Based on the in-depth evaluations, this paper finally forms a general evaluation scheme of logical reasoning capability from six dimensions (i.e., emph{Correct}, emph{Rigorous}, emph{Self-aware}, emph{Active}, emph{Oriented} and emph{No hallucination}). It reflects the pros and cons of LLMs and gives guiding directions for future works.
Read more9/17/2024