Compressing Search with Language Models

0
Sign in to get full access
Overview
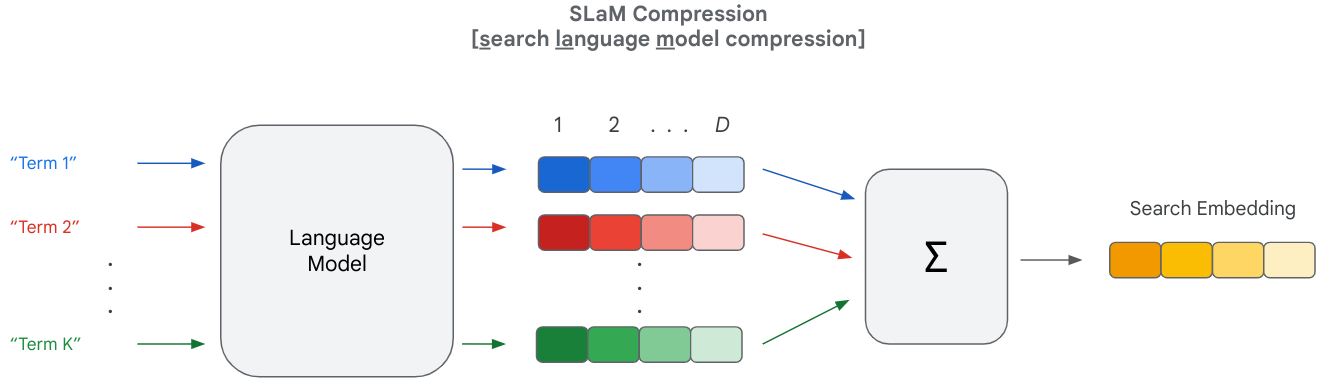
- This paper introduces SLaM, a technique for compressing search models using large language models (LLMs)
- SLaM can significantly reduce the size of search models while maintaining good performance
- The approach involves training an LLM to predict the outputs of the original search model, effectively "distilling" the model's knowledge into a smaller, more efficient representation
Plain English Explanation
The researchers developed a method called SLaM (Searchable Language Model) that can take a large, complex search model and compress it down into a smaller, more efficient version. The key idea is to train a large language model to mimic the behavior of the original search model.
Imagine you have a very detailed map of a city, but it's so big and unwieldy that it's hard to use. SLaM allows you to create a smaller, simpler map that captures the most important information from the original - the streets, landmarks, etc. - while being much easier to carry around and refer to. The smaller map isn't as comprehensive as the original, but it can still provide most of the relevant information you need.
Similarly, SLaM takes a large, powerful search model and "distills" its knowledge into a more compact language model. This compressed version can then be used in place of the original, providing good search results while using much less computational resources. This could be particularly useful for deploying high-quality search on resource-constrained devices like phones or IoT sensors.
Technical Explanation
The core of the SLaM approach is training an LLM to predict the outputs of the original search model. The researchers used a technique called knowledge distillation to transfer the knowledge from the large search model into the smaller LLM.
Specifically, they fine-tuned the LLM on a dataset consisting of search queries paired with the corresponding outputs from the original search model. This allowed the LLM to learn to mimic the behavior of the search model, effectively "compressing" its knowledge into the LLM's parameters.
The compressed LLM can then be used as a drop-in replacement for the original search model, providing similar search results but with much smaller memory and computational requirements. The authors explore different techniques for further compressing the LLM, such as pruning and quantization, to reduce its size even further.
Critical Analysis
The SLaM approach seems promising for enabling high-quality search on resource-constrained devices. By leveraging the powerful representational capabilities of LLMs, the method can achieve significant model compression while preserving much of the original search model's performance.
However, the paper does not explore the potential limitations of this approach. For example, it's unclear how well SLaM would handle rare or out-of-distribution queries that the original search model was able to handle, but the LLM was not trained on. There may also be challenges in ensuring the compressed model maintains the same level of fairness and robustness as the original.
Additionally, the authors do not discuss the potential environmental impact of training large LLMs, which can be computationally and energy-intensive. Careful consideration should be given to the tradeoffs between model compression and the carbon footprint of the overall system.
Overall, the SLaM technique represents an interesting and potentially impactful approach to compressing search models using LLMs. However, further research is needed to fully understand its limitations and ensure it can be deployed responsibly.
Conclusion
The SLaM technique introduced in this paper offers a promising way to compress large, complex search models into more efficient representations. By training a large language model to mimic the behavior of the original search model, the researchers were able to achieve significant reductions in model size while maintaining good search performance.
This approach could enable high-quality search to be deployed on resource-constrained devices, such as smartphones or IoT sensors, where the computational and memory requirements of traditional search models would be prohibitive. The ability to "distill" the knowledge of a large search model into a more compact form represents an important step towards making advanced search capabilities more widely accessible.
At the same time, the paper highlights the need for further research to fully understand the limitations and potential tradeoffs of this compression technique. Careful consideration must be given to ensuring the compressed models maintain the same level of fairness, robustness, and environmental sustainability as the original search models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Compressing Search with Language Models
Thomas Mulc, Jennifer L. Steele
Millions of people turn to Google Search each day for information on things as diverse as new cars or flu symptoms. The terms that they enter contain valuable information on their daily intent and activities, but the information in these search terms has been difficult to fully leverage. User-defined categorical filters have been the most common way to shrink the dimensionality of search data to a tractable size for analysis and modeling. In this paper we present a new approach to reducing the dimensionality of search data while retaining much of the information in the individual terms without user-defined rules. Our contributions are two-fold: 1) we introduce SLaM Compression, a way to quantify search terms using pre-trained language models and create a representation of search data that has low dimensionality, is memory efficient, and effectively acts as a summary of search, and 2) we present CoSMo, a Constrained Search Model for estimating real world events using only search data. We demonstrate the efficacy of our contributions by estimating with high accuracy U.S. automobile sales and U.S. flu rates using only Google Search data.
Read more7/2/2024

0
When Search Engine Services meet Large Language Models: Visions and Challenges
Haoyi Xiong, Jiang Bian, Yuchen Li, Xuhong Li, Mengnan Du, Shuaiqiang Wang, Dawei Yin, Sumi Helal
Combining Large Language Models (LLMs) with search engine services marks a significant shift in the field of services computing, opening up new possibilities to enhance how we search for and retrieve information, understand content, and interact with internet services. This paper conducts an in-depth examination of how integrating LLMs with search engines can mutually benefit both technologies. We focus on two main areas: using search engines to improve LLMs (Search4LLM) and enhancing search engine functions using LLMs (LLM4Search). For Search4LLM, we investigate how search engines can provide diverse high-quality datasets for pre-training of LLMs, how they can use the most relevant documents to help LLMs learn to answer queries more accurately, how training LLMs with Learning-To-Rank (LTR) tasks can enhance their ability to respond with greater precision, and how incorporating recent search results can make LLM-generated content more accurate and current. In terms of LLM4Search, we examine how LLMs can be used to summarize content for better indexing by search engines, improve query outcomes through optimization, enhance the ranking of search results by analyzing document relevance, and help in annotating data for learning-to-rank tasks in various learning contexts. However, this promising integration comes with its challenges, which include addressing potential biases and ethical issues in training models, managing the computational and other costs of incorporating LLMs into search services, and continuously updating LLM training with the ever-changing web content. We discuss these challenges and chart out required research directions to address them. We also discuss broader implications for service computing, such as scalability, privacy concerns, and the need to adapt search engine architectures for these advanced models.
Read more7/2/2024
📈
0
A Survey on Model Compression for Large Language Models
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang
Large Language Models (LLMs) have transformed natural language processing tasks successfully. Yet, their large size and high computational needs pose challenges for practical use, especially in resource-limited settings. Model compression has emerged as a key research area to address these challenges. This paper presents a survey of model compression techniques for LLMs. We cover methods like quantization, pruning, and knowledge distillation, highlighting recent advancements. We also discuss benchmarking strategies and evaluation metrics crucial for assessing compressed LLMs. This survey offers valuable insights for researchers and practitioners, aiming to enhance efficiency and real-world applicability of LLMs while laying a foundation for future advancements.
Read more7/31/2024

0
Towards More Relevant Product Search Ranking Via Large Language Models: An Empirical Study
Qi Liu, Atul Singh, Jingbo Liu, Cun Mu, Zheng Yan
Training Learning-to-Rank models for e-commerce product search ranking can be challenging due to the lack of a gold standard of ranking relevance. In this paper, we decompose ranking relevance into content-based and engagement-based aspects, and we propose to leverage Large Language Models (LLMs) for both label and feature generation in model training, primarily aiming to improve the model's predictive capability for content-based relevance. Additionally, we introduce different sigmoid transformations on the LLM outputs to polarize relevance scores in labeling, enhancing the model's ability to balance content-based and engagement-based relevances and thus prioritize highly relevant items overall. Comprehensive online tests and offline evaluations are also conducted for the proposed design. Our work sheds light on advanced strategies for integrating LLMs into e-commerce product search ranking model training, offering a pathway to more effective and balanced models with improved ranking relevance.
Read more9/27/2024