Stream of Search (SoS): Learning to Search in Language
2404.03683
2
29
Abstract
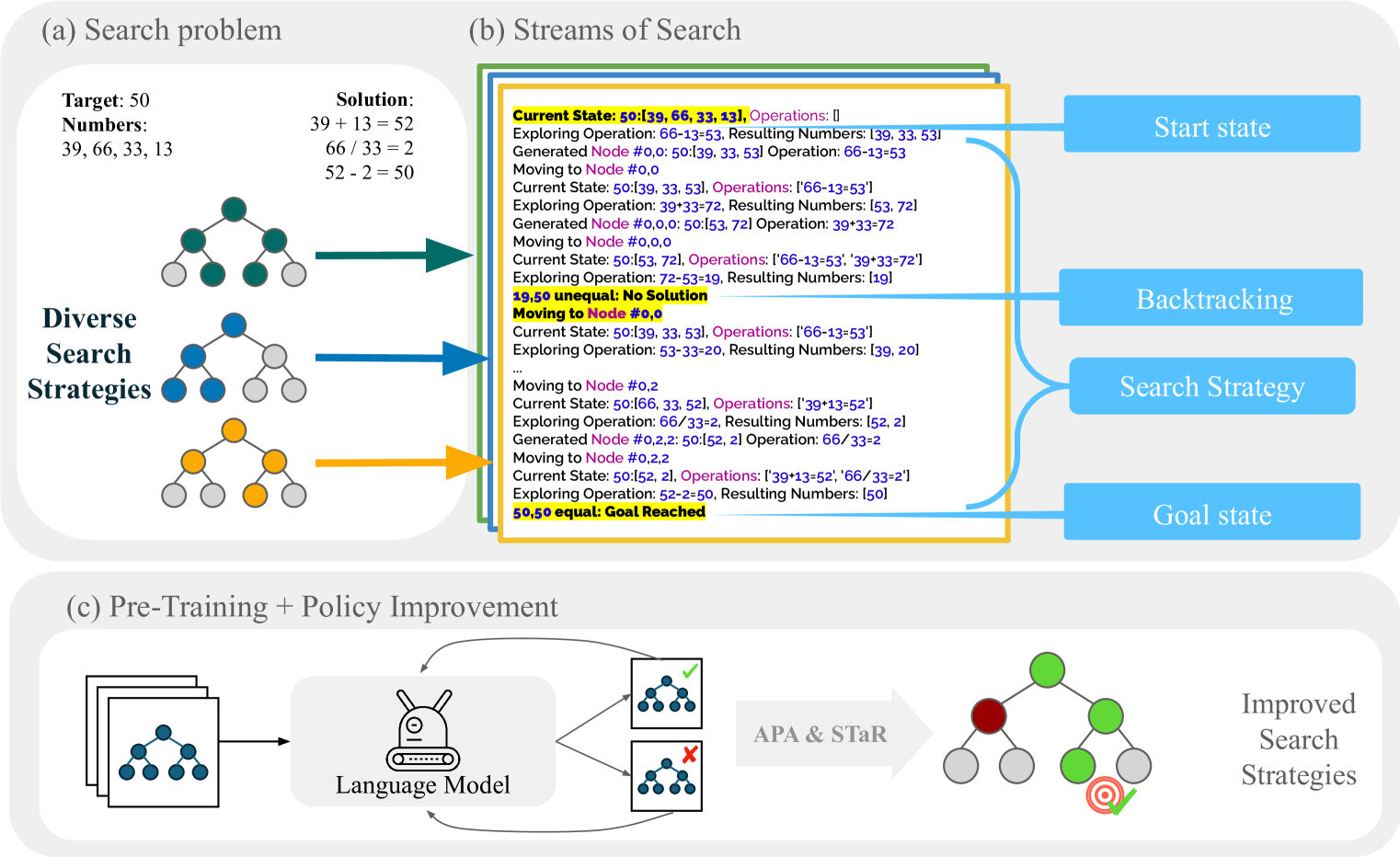
Language models are rarely shown fruitful mistakes while training. They then struggle to look beyond the next token, suffering from a snowballing of errors and struggling to predict the consequence of their actions several steps ahead. In this paper, we show how language models can be taught to search by representing the process of search in language, as a flattened string -- a stream of search (SoS). We propose a unified language for search that captures an array of different symbolic search strategies. We demonstrate our approach using the simple yet difficult game of Countdown, where the goal is to combine input numbers with arithmetic operations to reach a target number. We pretrain a transformer-based language model from scratch on a dataset of streams of search generated by heuristic solvers. We find that SoS pretraining increases search accuracy by 25% over models trained to predict only the optimal search trajectory. We further finetune this model with two policy improvement methods: Advantage-Induced Policy Alignment (APA) and Self-Taught Reasoner (STaR). The finetuned SoS models solve 36% of previously unsolved problems, including problems that cannot be solved by any of the heuristic solvers. Our results indicate that language models can learn to solve problems via search, self-improve to flexibly use different search strategies, and potentially discover new ones.
Create account to get full access
Overview
- This paper introduces a novel approach called "Stream of Search" (SoS) that enables language models to learn how to search effectively within their own language space.
- The key idea is to train the model to generate a stream of search queries that incrementally refine an original query, rather than just producing a single output.
- This allows the model to actively explore and navigate the language space to find the most relevant information, similar to how humans search on the internet.
Plain English Explanation
The paper presents a new way for language models, like the ones that power chatbots and virtual assistants, to improve their search capabilities. Integrating Hyperparameter Search into GRAM and Can Small Language Models Help Large Language Models? have explored related ideas.
Traditionally, these models would simply generate a single response to a query. But the "Stream of Search" (SoS) approach trains the model to instead produce a series of refined search queries. This allows the model to explore the space of possible responses, much like how humans might refine their searches on the internet to find the most relevant information.
By learning to search within its own language abilities, the model can better understand the nuances and context of the original query. This is similar to how Dwell: Beginning How Language Models Embed Long-Term Memory explored how language models can build up an understanding over multiple interactions.
The key insight is that training the model to actively search, rather than just produce a single output, can lead to more accurate and useful responses. This could have interesting applications for virtual assistants, chatbots, and other language-based AI systems.
Technical Explanation
The core of the SoS approach is to train the language model to generate a "stream" of search queries, where each query iteratively refines the previous one. This is done by structuring the training process as a multi-step search task.
The model is first given an initial query, and then tasked with producing a sequence of refined queries that gradually hone in on the most relevant information. The quality of the final query in the sequence is then used to provide feedback and update the model's parameters.
This training process encourages the model to explore the space of possible queries, rather than simply outputting a single fixed response. The authors show that this leads to better performance on a range of language understanding and retrieval tasks, compared to standard language models.
The Solving Ability Amplification Strategy (SAAS) paper explored a related idea of using iterative refinement to improve model performance. The SoS approach builds on these insights, applying them specifically to the domain of language search and retrieval.
Critical Analysis
One key limitation of the SoS approach is that it relies on being able to provide high-quality feedback on the final query in the sequence. In real-world applications, obtaining such detailed feedback may be challenging.
The paper also does not address how the SoS approach would scale to more complex, open-ended search tasks. The experiments focus on relatively constrained, factual retrieval scenarios. Applying the technique to more ambiguous, exploratory search tasks may require further innovations.
Additionally, the computational overhead of generating and evaluating multiple search queries may limit the practical deployment of SoS in some settings. The tradeoffs between search quality and efficiency would need to be carefully considered.
Overall, the SoS approach represents an interesting step towards improving the search capabilities of language models. However, further research is needed to fully understand its strengths, weaknesses, and potential real-world applications. Readers are encouraged to Do Sentence Transformers Learn Quasi-Geospatial Concepts? and form their own conclusions about the merits of this work.
Conclusion
The "Stream of Search" (SoS) approach introduced in this paper offers a novel way for language models to learn how to search effectively within their own language space. By training the model to generate a sequence of refined search queries, rather than a single output, the authors demonstrate improvements in language understanding and retrieval tasks.
This work represents an interesting step towards more sophisticated language-based AI systems that can actively explore and navigate information, similar to how humans search the internet. While the current implementation has some limitations, the core ideas behind SoS could have important implications for the development of virtual assistants, chatbots, and other language-based applications.
As the field of language AI continues to evolve, techniques like SoS that enhance the search and exploration capabilities of models will likely become increasingly important. Readers are encouraged to stay up-to-date with the latest advancements in this rapidly advancing area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SAAS: Solving Ability Amplification Strategy for Enhanced Mathematical Reasoning in Large Language Models
Hyeonwoo Kim, Gyoungjin Gim, Yungi Kim, Jihoo Kim, Byungju Kim, Wonseok Lee, Chanjun Park
0
0
This study presents a novel learning approach designed to enhance both mathematical reasoning and problem-solving abilities of Large Language Models (LLMs). We focus on integrating the Chain-of-Thought (CoT) and the Program-of-Thought (PoT) learning, hypothesizing that prioritizing the learning of mathematical reasoning ability is helpful for the amplification of problem-solving ability. Thus, the initial learning with CoT is essential for solving challenging mathematical problems. To this end, we propose a sequential learning approach, named SAAS (Solving Ability Amplification Strategy), which strategically transitions from CoT learning to PoT learning. Our empirical study, involving an extensive performance comparison using several benchmarks, demonstrates that our SAAS achieves state-of-the-art (SOTA) performance. The results underscore the effectiveness of our sequential learning approach, marking a significant advancement in the field of mathematical reasoning in LLMs.
4/9/2024
🏷️
Navigating the Labyrinth: Evaluating and Enhancing LLMs' Ability to Reason About Search Problems
Nasim Borazjanizadeh, Roei Herzig, Trevor Darrell, Rogerio Feris, Leonid Karlinsky
0
0
Recently, Large Language Models (LLMs) attained impressive performance in math and reasoning benchmarks. However, they still often struggle with logic problems and puzzles that are relatively easy for humans. To further investigate this, we introduce a new benchmark, SearchBench, containing 11 unique search problem types, each equipped with automated pipelines to generate an arbitrary number of instances and analyze the feasibility, correctness, and optimality of LLM-generated solutions. We show that even the most advanced LLMs fail to solve these problems end-to-end in text, e.g. GPT4 solves only 1.4%. SearchBench problems require considering multiple pathways to the solution as well as backtracking, posing a significant challenge to auto-regressive models. Instructing LLMs to generate code that solves the problem helps, but only slightly, e.g., GPT4's performance rises to 11.7%. In this work, we show that in-context learning with A* algorithm implementations enhances performance. The full potential of this promoting approach emerges when combined with our proposed Multi-Stage-Multi-Try method, which breaks down the algorithm implementation into two stages and verifies the first stage against unit tests, raising GPT-4's performance above 57%.
6/19/2024
StreamBench: Towards Benchmarking Continuous Improvement of Language Agents
Cheng-Kuang Wu, Zhi Rui Tam, Chieh-Yen Lin, Yun-Nung Chen, Hung-yi Lee
0
0
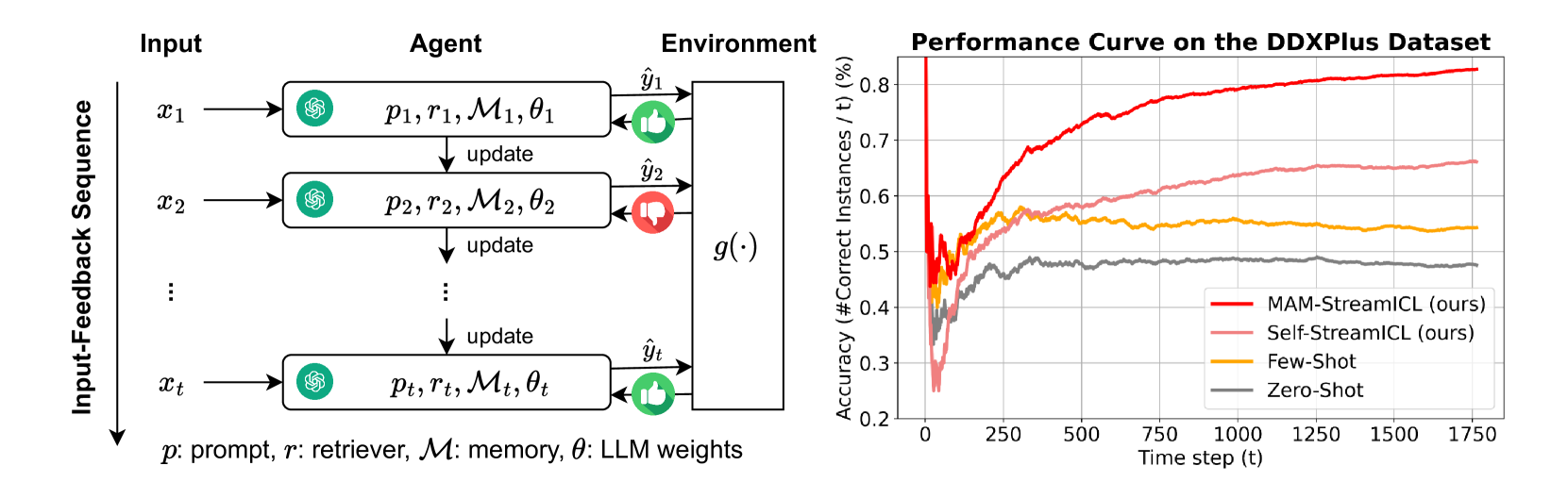
Recent works have shown that large language model (LLM) agents are able to improve themselves from experience, which is an important ability for continuous enhancement post-deployment. However, existing benchmarks primarily evaluate their innate capabilities and do not assess their ability to improve over time. To address this gap, we introduce StreamBench, a pioneering benchmark designed to evaluate the continuous improvement of LLM agents over an input-feedback sequence. StreamBench simulates an online learning environment where LLMs receive a continuous flow of feedback stream and iteratively enhance their performance. In addition, we propose several simple yet effective baselines for improving LLMs on StreamBench, and provide a comprehensive analysis to identify critical components that contribute to successful streaming strategies. Our work serves as a stepping stone towards developing effective online learning strategies for LLMs, paving the way for more adaptive AI systems in streaming scenarios.
6/14/2024

Automated Statistical Model Discovery with Language Models
Michael Y. Li, Emily B. Fox, Noah D. Goodman
0
0
Statistical model discovery is a challenging search over a vast space of models subject to domain-specific constraints. Efficiently searching over this space requires expertise in modeling and the problem domain. Motivated by the domain knowledge and programming capabilities of large language models (LMs), we introduce a method for language model driven automated statistical model discovery. We cast our automated procedure within the principled framework of Box's Loop: the LM iterates between proposing statistical models represented as probabilistic programs, acting as a modeler, and critiquing those models, acting as a domain expert. By leveraging LMs, we do not have to define a domain-specific language of models or design a handcrafted search procedure, which are key restrictions of previous systems. We evaluate our method in three settings in probabilistic modeling: searching within a restricted space of models, searching over an open-ended space, and improving expert models under natural language constraints (e.g., this model should be interpretable to an ecologist). Our method identifies models on par with human expert designed models and extends classic models in interpretable ways. Our results highlight the promise of LM-driven model discovery.
6/26/2024