Computational Copyright: Towards A Royalty Model for Music Generative AI

0

Sign in to get full access
Overview
- This paper proposes a computational framework to address copyright challenges posed by AI-generated music.
- The authors explore various digital music royalty models and suggest a novel approach to compensate artists and rights-holders.
- The paper aims to provide a practical solution to the complex legal and economic issues surrounding AI-generated content and copyright.
Plain English Explanation
The paper tackles the tricky problem of copyright in the age of AI-generated music. As AI systems become more advanced, they can create music that sounds increasingly human-like. This raises questions about who owns the rights to that music - the AI system's developers, the artists whose work was used to train the AI, or someone else entirely?
The authors look at existing models for paying royalties to music creators and rights-holders. They examine case studies of how these models work in the real world. Based on this analysis, the authors propose a new computational framework for determining royalty payments in the context of AI-generated music.
The goal is to find a fair and practical way to compensate everyone involved - the AI developers, the original artists whose work was used to train the AI, and the end users who consume the AI-generated music. This is a complex challenge without easy answers, but the authors aim to provide a thoughtful, evidence-based approach to tackle this emerging issue at the intersection of technology, creativity, and intellectual property.
Technical Explanation
The paper begins by providing background on the concept of music royalties. It outlines the key stakeholders (composers, publishers, record labels, digital service providers, etc.) and the various revenue streams (mechanical, performance, synchronization, etc.) in the music industry.
The authors then analyze three case studies to understand how digital music royalty models work in practice:
- Economic Solution to Copyright Challenges of Generative AI
- Uncertain Boundaries: Multidisciplinary Approaches to Copyright Issues
- AI Royalties: An IP Framework to Compensate Artists
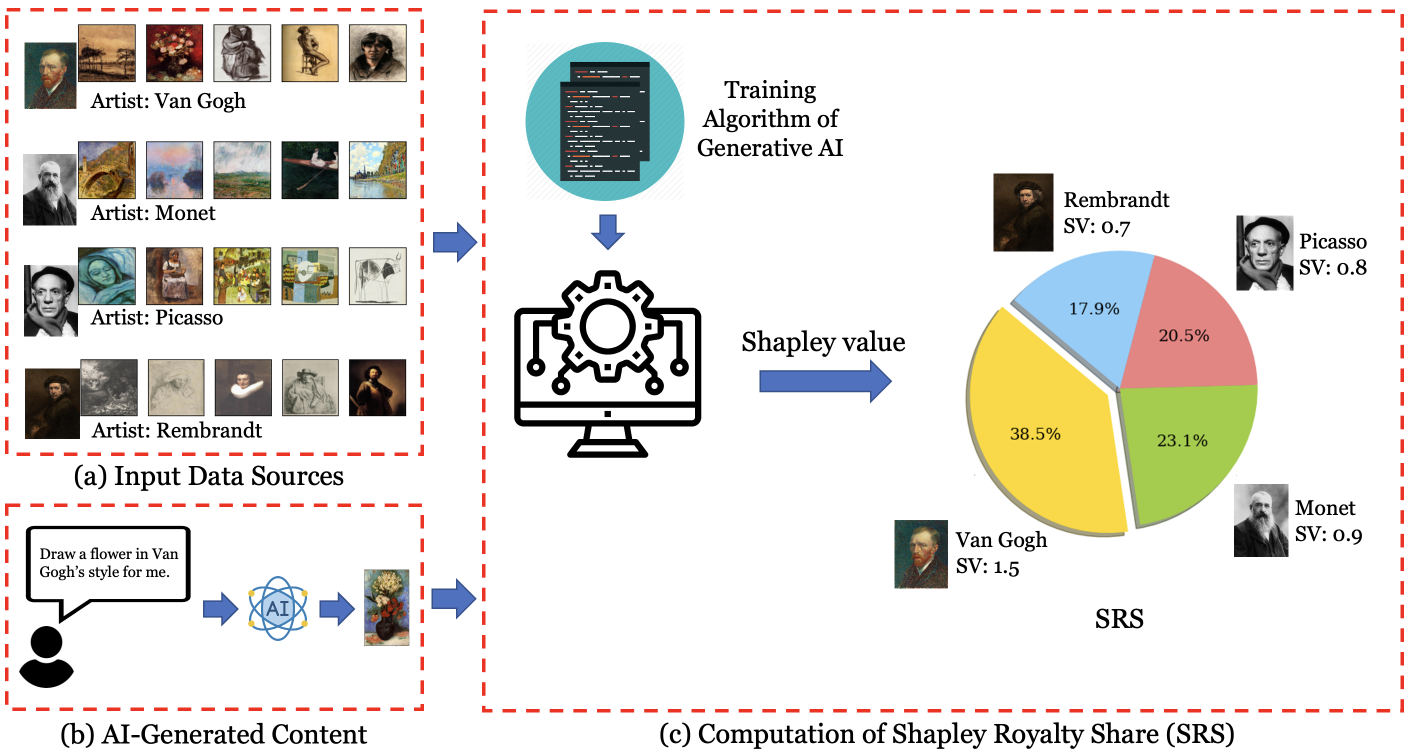
These case studies illustrate the complexities and challenges in applying traditional royalty models to AI-generated content. Building on this analysis, the authors propose a new computational framework called "Data Shapley" to determine fair royalty allocations for AI music generation platforms.
The Data Shapley approach aims to quantify the contributions of various inputs (training data, algorithms, etc.) to the value of the AI-generated output. This allows for a more nuanced and equitable distribution of royalties compared to simplistic models.
The authors also discuss the concept of "Originality Estimation and Genericization" to address challenges around assessing the originality of AI-generated works and their impact on existing copyrights.
Critical Analysis
The paper tackles a complex and timely issue, offering a thoughtful and evidence-based approach to addressing the copyright challenges posed by AI-generated music. The authors' exploration of existing royalty models and their proposal for a new computational framework are valuable contributions to the ongoing discussion.
However, the paper acknowledges several caveats and areas for further research. For example, the Data Shapley method relies on accurate quantification of various input contributions, which may be practically challenging to implement. Additionally, the assessment of originality and genericization of AI-generated works is an active area of legal and academic debate, with no clear consensus yet.
Furthermore, the paper does not address potential issues around privacy, bias, and transparency in the data and algorithms used to train AI music generation systems. These are important considerations that could impact the fairness and acceptability of any proposed royalty model.
Overall, the paper presents a valuable framework for thinking about copyright in the context of AI-generated content. While the solutions proposed are not perfect, they represent a thoughtful step towards addressing a complex and rapidly evolving issue.
Conclusion
This paper offers a computational approach to addressing the copyright challenges posed by AI-generated music. By exploring existing digital music royalty models and proposing a novel framework called Data Shapley, the authors aim to develop a more equitable and practical way to compensate artists, rights-holders, and other stakeholders in the era of AI-powered creativity.
While the solutions presented are not without limitations, the paper's analysis and proposed framework represent an important contribution to the ongoing discussion at the intersection of technology, intellectual property, and the arts. As AI systems continue to advance and their impact on creative industries grows, frameworks like the one described in this paper will become increasingly crucial in navigating the complex legal and economic issues involved.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Computational Copyright: Towards A Royalty Model for Music Generative AI
Junwei Deng, Shiyuan Zhang, Jiaqi Ma
The advancement of generative AI has given rise to pressing copyright challenges, especially within the music industry. This paper focuses on the economic aspects of these challenges, emphasizing that the economic impact constitutes a central issue in the copyright arena. Furthermore, the complexity of the black-box generative AI technologies not only suggests but necessitates algorithmic solutions. Yet, such solutions have been largely missing, exacerbating regulatory hurdles in this landscape. We seek to address this gap by proposing viable royalty models for revenue sharing on AI music generation platforms. We start by examining existing royalty models utilized by platforms like Spotify and YouTube, and then discuss how to adapt them to the unique context of AI-generated music. A significant challenge emerging from this adaptation is the attribution of AI-generated music to influential copyrighted content in the training data. To this end, we present algorithmic solutions employing data attribution techniques. We also conduct a range of experiments to verify the effectiveness and robustness of these solutions. This research is one of the early attempts to integrate technical advancements with economic and legal considerations in the field of music generative AI, offering a computational copyright solution for the challenges posed by the opaque nature of AI technologies.
Read more7/23/2024
0
An Economic Solution to Copyright Challenges of Generative AI
Jiachen T. Wang, Zhun Deng, Hiroaki Chiba-Okabe, Boaz Barak, Weijie J. Su
Generative artificial intelligence (AI) systems are trained on large data corpora to generate new pieces of text, images, videos, and other media. There is growing concern that such systems may infringe on the copyright interests of training data contributors. To address the copyright challenges of generative AI, we propose a framework that compensates copyright owners proportionally to their contributions to the creation of AI-generated content. The metric for contributions is quantitatively determined by leveraging the probabilistic nature of modern generative AI models and using techniques from cooperative game theory in economics. This framework enables a platform where AI developers benefit from access to high-quality training data, thus improving model performance. Meanwhile, copyright owners receive fair compensation, driving the continued provision of relevant data for generative model training. Experiments demonstrate that our framework successfully identifies the most relevant data sources used in artwork generation, ensuring a fair and interpretable distribution of revenues among copyright owners.
Read more9/10/2024
🤖
0
Uncertain Boundaries: Multidisciplinary Approaches to Copyright Issues in Generative AI
Jocelyn Dzuong, Zichong Wang, Wenbin Zhang
In the rapidly evolving landscape of generative artificial intelligence (AI), the increasingly pertinent issue of copyright infringement arises as AI advances to generate content from scraped copyrighted data, prompting questions about ownership and protection that impact professionals across various careers. With this in mind, this survey provides an extensive examination of copyright infringement as it pertains to generative AI, aiming to stay abreast of the latest developments and open problems. Specifically, it will first outline methods of detecting copyright infringement in mediums such as text, image, and video. Next, it will delve an exploration of existing techniques aimed at safeguarding copyrighted works from generative models. Furthermore, this survey will discuss resources and tools for users to evaluate copyright violations. Finally, insights into ongoing regulations and proposals for AI will be explored and compared. Through combining these disciplines, the implications of AI-driven content and copyright are thoroughly illustrated and brought into question.
Read more4/15/2024
✅
0
Copyright Protection in Generative AI: A Technical Perspective
Jie Ren, Han Xu, Pengfei He, Yingqian Cui, Shenglai Zeng, Jiankun Zhang, Hongzhi Wen, Jiayuan Ding, Pei Huang, Lingjuan Lyu, Hui Liu, Yi Chang, Jiliang Tang
Generative AI has witnessed rapid advancement in recent years, expanding their capabilities to create synthesized content such as text, images, audio, and code. The high fidelity and authenticity of contents generated by these Deep Generative Models (DGMs) have sparked significant copyright concerns. There have been various legal debates on how to effectively safeguard copyrights in DGMs. This work delves into this issue by providing a comprehensive overview of copyright protection from a technical perspective. We examine from two distinct viewpoints: the copyrights pertaining to the source data held by the data owners and those of the generative models maintained by the model builders. For data copyright, we delve into methods data owners can protect their content and DGMs can be utilized without infringing upon these rights. For model copyright, our discussion extends to strategies for preventing model theft and identifying outputs generated by specific models. Finally, we highlight the limitations of existing techniques and identify areas that remain unexplored. Furthermore, we discuss prospective directions for the future of copyright protection, underscoring its importance for the sustainable and ethical development of Generative AI.
Read more7/25/2024